
Оглавление
Исследователи из стартапа Goodfire.ai представили первое убедительное доказательство того, что механизмы запоминания и логического мышления в языковых моделях ИИ используют совершенно разные нейронные пути. Это открытие может изменить подход к редактированию моделей и устранению нежелательных данных.
Хирургическое разделение функций
В препринте статьи, опубликованной в конце октября, команда описала эксперименты с моделями Allen Institute for AI OLMo-7B. Ученые обнаружили, что удаление путей запоминания приводит к потере 97% способности к точному воспроизведению тренировочных данных, при этом логическое мышление сохраняется практически полностью.
Например, на 22-м слое модели OLMo-7B нижние 50% весовых компонентов показали на 23% более высокую активацию на запомненных данных, тогда как верхние 10% активировались на 26% сильнее на общем, незапоминаемом тексте.
Поразительно, но арифметические операции оказались ближе к механизмам запоминания, а не логического мышления. После удаления цепей памяти математическая производительность упала до 66%, в то время как логические задачи остались практически нетронутыми. Это объясняет, почему языковые модели так плохо справляются с математикой без внешних инструментов — они пытаются вспомнить арифметику из ограниченной таблицы запоминания, а не вычислять её, как студент, который зазубрил таблицу умножения, но не понял принцип умножения.
Ландшафт потерь как карта мышления
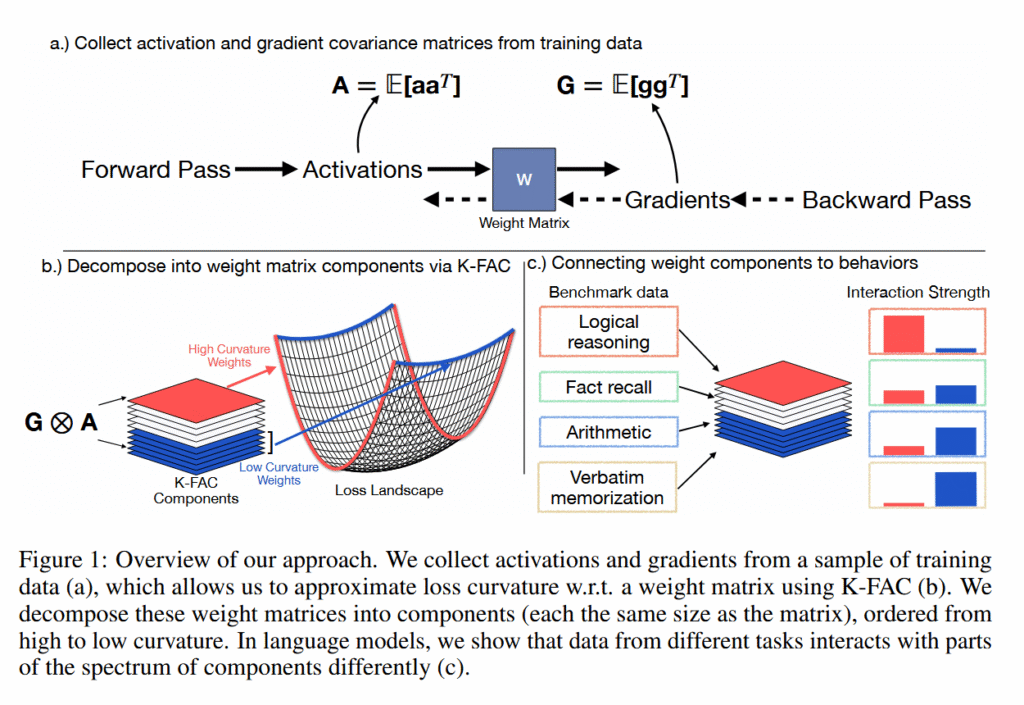
Чтобы понять, как исследователи различали запоминание и мышление, нужно познакомиться с концепцией «ландшафта потерь» в ИИ. Это визуализация того, насколько ошибочными или правильными являются предсказания модели при изменении её внутренних настроек (весов).
Представьте сложную машину с миллионами регуляторов. «Потери» измеряют количество ошибок машины. Высокие потери означают много ошибок, низкие — мало. «Ландшафт» — это то, что вы увидели бы, если бы смогли отобразить уровень ошибок для каждой возможной комбинации настроек регуляторов.
Во время обучения модели ИИ фактически «скатываются вниз» по этому ландшафту (градиентный спуск), настраивая свои веса, чтобы найти долины с минимальным количеством ошибок.
Исследователи анализировали «кривизну» ландшафтов потерь конкретных языковых моделей ИИ, измеряя, насколько чувствительна производительность модели к небольшим изменениям в различных весах нейросети. Острые пики и долины представляют высокую кривизну (где крошечные изменения вызывают большие эффекты), а плоские равнины — низкую кривизну (где изменения имеют минимальное влияние).
Используя технику K-FAC (Kronecker-Factored Approximate Curvature), они обнаружили, что отдельные запомненные факты создают острые пики в этом ландшафте, но поскольку каждый запомненный элемент создает пик в разном направлении, при усреднении вместе они создают плоский профиль. Между тем, способности к мышлению, на которые опираются многие различные входные данные, сохраняют постоянные умеренные кривые по всему ландшафту.
Спектр механизмов для разных задач
Исследователи протестировали свою технику на нескольких системах ИИ, чтобы убедиться, что результаты сохраняются в разных архитектурах. Они в основном использовали семейство открытых языковых моделей Allen Institute OLMo-2, специально версии с 7 и 1 миллиардом параметров, выбранные потому, что их тренировочные данные открыто доступны.
Для моделей зрения они обучали специальные Vision Transformers (ViT-Base модели) на ImageNet с преднамеренно неправильно помеченными данными, чтобы создать контролируемое запоминание. Они также проверяли свои выводы против существующих методов удаления запоминания, таких как BalancedSubnet, чтобы установить эталоны производительности.
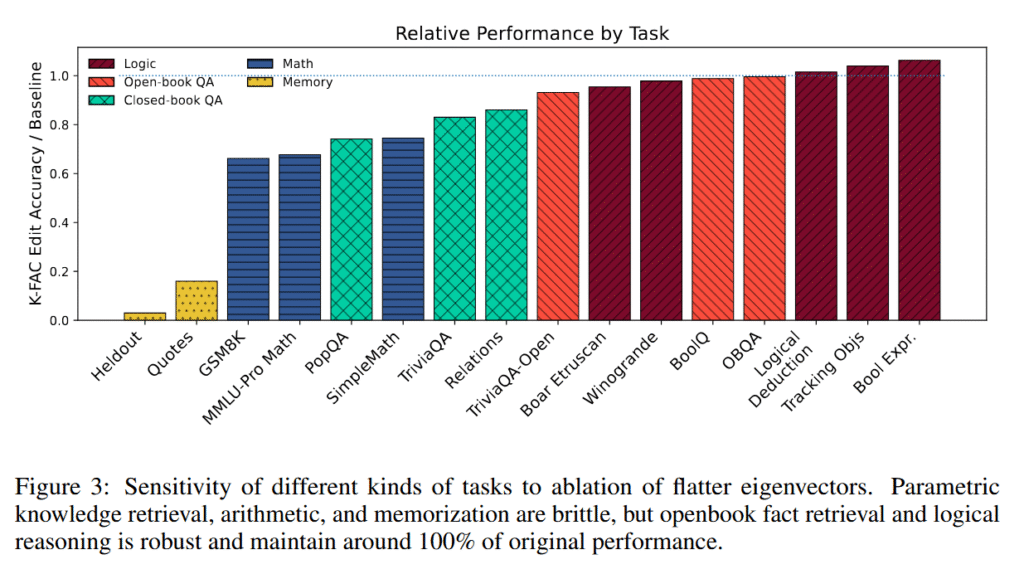
Команда проверила свое открытие, выборочно удаляя компоненты весов с низкой кривизной из этих обученных моделей. Запомненный контент упал до 3,4% воспроизведения с почти 100%. Между тем, задачи логического мышления сохранили от 95 до 106% базовой производительности.
Эти логические задачи включали:
- Оценку булевых выражений
- Логические головоломки на дедукцию
- Отслеживание объектов через множественные замены
- Бенчмарки типа BoolQ для да/нет рассуждений
- Winogrande для выводов здравого смысла
- OpenBookQA для научных вопросов, требующих рассуждений из предоставленных фактов
Некоторые задачи оказались между этими крайностями, раскрывая спектр механизмов.
Математические операции и извлечение фактов из закрытой книги разделяли пути с запоминанием, падая до 66-86% производительности после редактирования. Исследователи обнаружили, что арифметика особенно хрупка. Даже когда модели генерировали идентичные цепочки рассуждений, они терпели неудачу на этапе вычисления после удаления компонентов с низкой кривизной.
Ответы на вопросы с открытой книгой, которые полагаются на предоставленный контекст, а не на внутренние знания, оказались наиболее устойчивыми к процедуре редактирования, сохраняя почти полную производительность.
Перспективы и ограничения
В перспективе, если методы удаления информации получат дальнейшее развитие, компании ИИ потенциально смогут удалять, скажем, защищенный авторским правом контент, приватную информацию или вредный запомненный текст из нейросети, не разрушая способность модели выполнять преобразующие задачи.
Однако, поскольку нейросети хранят информацию распределенными способами, которые до сих пор не полностью поняты, на данный момент исследователи говорят, что их метод «не может гарантировать полного устранения чувствительной информации». Это ранние шаги в новом направлении исследований для ИИ.
По сообщению Ars Technica, открытие разделения памяти и логики в нейросетях открывает путь к созданию более безопасных и контролируемых систем искусственного интеллекта, способных сохранять свои аналитические способности при удалении нежелательных данных.





Оставить комментарий