
Оглавление
Китайские исследователи бросили вызов фундаментальной парадигме машинного обучения, продемонстрировав, что качество данных может превзойти их количество. Вместо миллионов примеров для обучения автономных агентов достаточно всего 78 тщательно отобранных кейсов.
Согласно исследованию LIMI («Less Is More for Intelligent Agency»), методология сфокусирована на обучении ИИ-систем самостоятельным действиям — обнаружению проблем, формированию гипотез и решению задач через самонаправленное взаимодействие со средами и инструментами.
Революция в подходе к обучению
LIMI использует всего 78 ручно отобранных примеров из реальных задач разработки программного обеспечения и исследовательской деятельности. Каждый пример захватывает полный процесс человеко-машинного взаимодействия: от первоначального запроса через использование инструментов, решение проблем до финального успеха.
На бенчмарке AgencyBench, который охватывает реальные сценарии включая:
- Создание чат-приложений на C++
- Разработку Java to-do листов
- Построение AI-игр
- Микросервисные пайплайны
- Сравнения языковых моделей
- Анализ данных и бизнес-аналитику
LIMI показал результат 73.5%, используя только 78 обучающих примеров.
Сравнительный анализ производительности
Разрыв в производительности впечатляет:
- Deepseek-V3.1: 11.9%
- Kimi-K2-Instruct: 24.1%
- Qwen3-235B-A22B-Instruct: 27.5%
- GLM-4.5: 45.1%
LIMI обеспечил 53.7% прирост по сравнению с моделями, обученными на 10,000 образцов, используя в 128 раз меньше данных.
Методология также достигла 71.7% успешного выполнения требований с первой попытки, почти удвоив лучший базовый показатель. Общий уровень успеха составил 74.6% против 47.4% у GLM-4.5.

Архитектура и масштабируемость
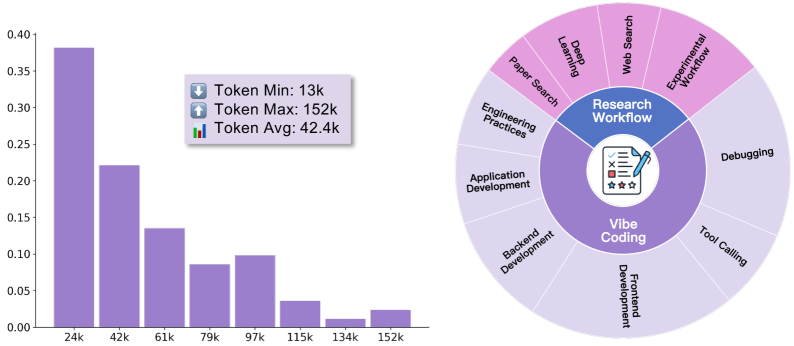
Исследователи сфокусировались на двух основных категориях:
- Вайбкодинг-платформы для совместной разработки ПО
- Исследовательские workflow для научных задач
Некоторые траектории обучения достигали 152,000 токенов, демонстрируя глубину и сложность автономного поведения, которое смогла освоить LIMI.
Если результаты подтвердятся, это может стать одним из самых значительных прорывов в эффективности обучения ИИ за последние годы. Вместо гонки за большими данными мы можем перейти к гонке за умными данными — тщательно отобранными, репрезентативными и педагогически ценными примерами.
Практические implications и доступность
Подход LIMI работает среди на моделях разных размеров:
- LIMI-Air (106 миллиардов параметров): улучшение с 17.0% до 34.3%
- LIMI (355 миллиардов параметров): скачок с 45.1% до 73.5%
Все материалы исследования — код, модели и датасеты — находятся в открытом доступе.
Результаты поддерживают недавние заявления исследователей Nvidia о том, что модели менее 10 миллиардов параметров могут быть достаточны для агентских задач. LIMI предоставляет эмпирические доказательства, что тщательная курация данных может победить брутфорс-скейлинг.
По материалам The Decoder.





Оставить комментарий