Компания Infosys разработала специализированное решение на базе генеративного ИИ для обработки сложных мультимодальных данных в нефтегазовой отрасли. Система построена на Amazon Bedrock и использует возможности Infosys Topaz для анализа технической документации, включая текстовые отчеты, диаграммы и числовые данные.
Архитектура решения
Решение использует комплексный стек технологий AWS для обработки специализированной документации:
- Обработка документов – PyMuPDF для парсинга PDF, OpenCV для работы с изображениями
- Векторные embedding – Cohere Embed English для создания векторных представлений
- Хранилище – Amazon OpenSearch Serverless с гибридным поиском
- Модель – Amazon Nova Pro для генерации доменно-специфичных ответов
- Ранжирование – BGE reranker для улучшения релевантности результатов
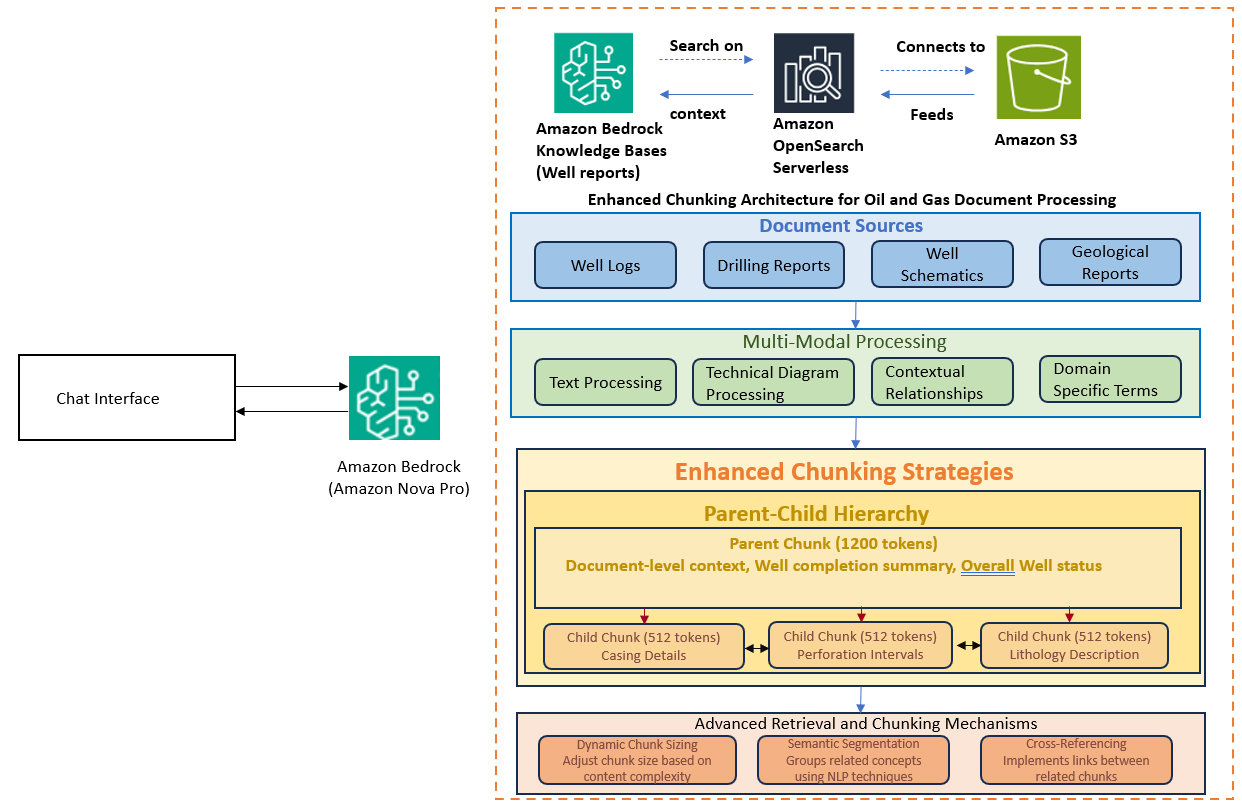
Особенности подхода
Система использует иерархическую архитектуру дробления «родитель-потомок», которая сохраняет структурные связи в документах. Это критически важно для технической документации, где контекст между текстом, таблицами и диаграммами неразрывно связан.
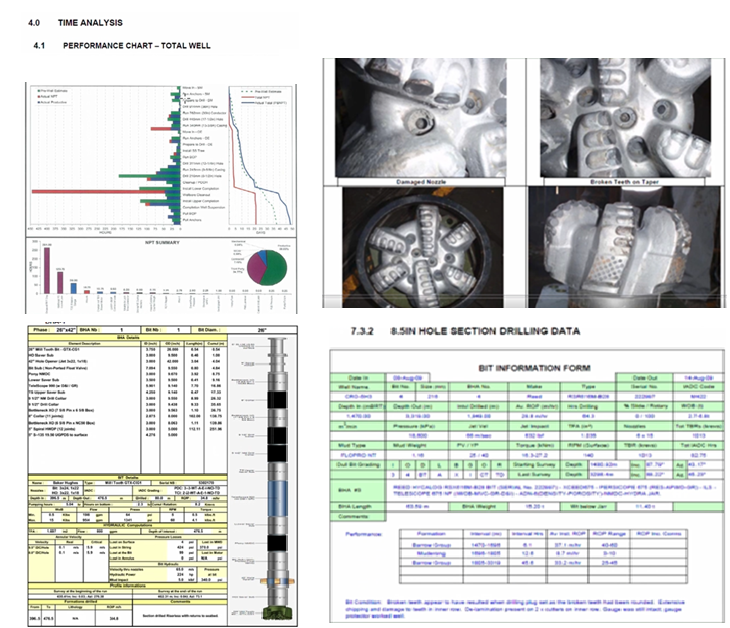
Для обработки изображений (литологические диаграммы, схемы оборудования, визуализации бурения) применялась многоуровневая стратегия промптинга с использованием мультимодальной модели Amazon Nova Pro.
Это классический пример того, как специализированные RAG-решения превосходят универсальные подходы. Вместо попыток адаптировать общую архитектуру под узкую специфическую задачу, Infosys построила систему с нуля с учетом особенностей нефтегазовой документации. Особенно впечатляет работа с мультимодальными данными — большинство существующих решений до сих пор фокусируются только на тексте.
Практическая ценность
Решение позволяет автоматизировать обработку тысяч страниц технической документации, которые ранее требовали ручного анализа. Это ускоряет принятие операционных решений и снижает риски человеческих ошибок при интерпретации сложных технических данных.
Материал с сайта: AWS Machine Learning Blog.





Оставить комментарий