
Оглавление
По данным Hugging Face, исследовательский форум Indic-scripts предпринимает масштабные усилия по созданию специализированного датасета для машинного перевода документов, написанных моди-письмом — исторической системой письменности, использовавшейся в Махараштре с XIV по XIX век.
Проблема существующих подходов
Традиционные методы перевода, включая разработки IIT Roorkee, оказались неэффективными. Их датасет MoDeTrans содержит всего 2043 предложения с транслитерацией на деванагари, что совершенно недостаточно для качественного обучения AI-моделей.
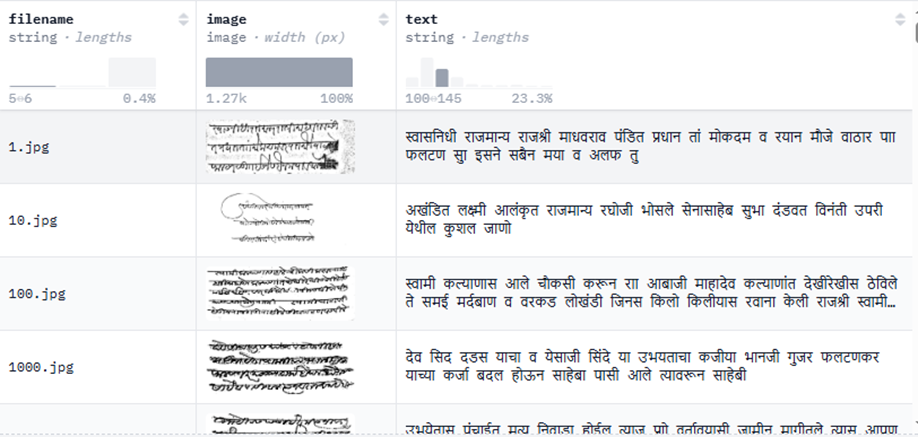
Тестирование модели MoScNet показало 100% неудач при переводе — все результаты были бессвязными и неточными. Это демонстрирует фундаментальную проблему: без репрезентативного датасета, отражающего языковые особенности периода 1400-1900 годов, достичь осмысленного перевода невозможно.
Новый подход к построению датасета
Indic-scripts Research Forum использует принципиально иную стратегию:
- Создание структурированного датасета из 50 000 слов
- Парное сопоставление слов моди-письма с современным маратхи
- Использование исторических словарей и экспертных переводов
- Векторное представление данных для последующего поиска
Для перевода исторических текстов приходится обращаться к еще более древним источникам — словарям XVIII-XIX веков. Это напоминает археологическую экспедицию в мир данных, где каждый артефакт-слово требует точной атрибуции и контекстуализации. Современные ИИ-модели, обученные на актуальных корпусах, просто не понимают язык прошлого — им нужны специальные «исторические очки» в виде качественно подобранных датасетов.
Ключевые источники данных
Исследователи используют уникальные исторические словари, включая:
- Maharashtra Language Dictionary (1821 год)
- Словарь Raghunath Bhaskar Godbole (1870 год)
- Historic Shabdakosh Y.N. Kelkar (1962 год)
- Современные вычислительные словари с 267 000 терминов
Технологическая реализация
Словарные статьи преобразуются в численные представления и хранятся в векторной базе данных. Это позволяет осуществлять семантический поиск и находить альтернативные значения слов. Такой подход станет основой для будущей языковой модели, специализированной на истории Махараштры.
Структурированные данные из словарей будут использоваться для верификации и упорядочивания неструктурированных исторических документов, поступающих в трех форматах: оригинальное моди-письмо, транслитерированный маратхи и современный маратхи.
По материалам Hugging Face





Оставить комментарий