
Оглавление
IBM представила второе поколение моделей Granite Embedding R2, которые бросают вызов традиционным компромиссам в области поиска информации для предприятий. Эти модели предлагают сочетание высокой точности, скорости работы и поддержки длинных контекстов при лицензии Apache 2.0.
Три модели для разных задач
В семейство Granite Embedding R2 входят три модели с открытой лицензией:
- granite-embedding-english-r2 (149 млн параметров) — флагманская модель с 768-мерными эмбеддингами
- granite-embedding-small-english-r2 (47 млн параметров) — компактная модель с 384-мерными эмбеддингами
- granite-embedding-reranker-english-r2 (149 млн параметров) — кросс-энкодер для точного ранжирования
Ключевые улучшения по сравнению с первым поколением включают увеличение длины контекста в 16 раз (с 512 до 8192 токенов), повышение скорости инференса на 19–44% и достижение наилучших результатов в различных задачах.
Современная архитектура и обучение
Модели построены на архитектуре ModernBERT с чередующимися механизмами внимания, ротационными позиционными эмбеддингами и поддержкой Flash Attention. Обучение проводилось на 2 триллионах токенов из качественных источников, включая GneissWeb, Wikipedia и Granite Code.
Пятиэтапный процесс обучения включает:
- Предварительное обучение для поиска с использованием RetroMAE
- Предварительное обучение на табличных данных с синтетическими описаниями
- Контрастивное дообучение на полу-супервизированных парах
- Контрастивная дистилляция с учителем Mistral-7B
- Адаптация для диалогового поиска
Производительность: лидерство в точности и скорости
Оценка на шести открытых бенчмарках (MTEB v2, CoIR, TableIR, LongEmbed, MTRAG и MLDR) показала превосходство Granite R2 как в точности, так и в скорости.
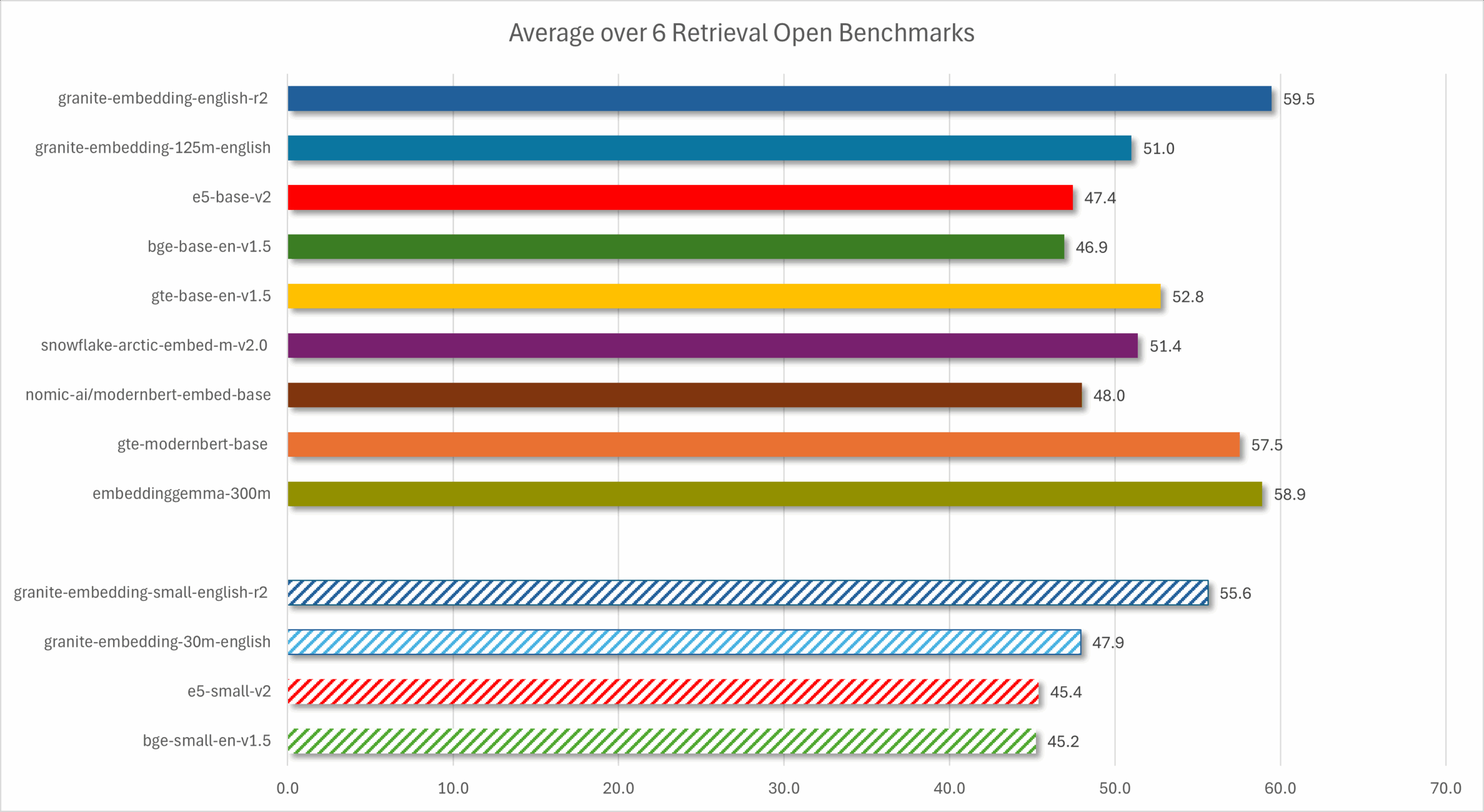
Флагманская модель granite-embedding-english-r2 достигает наивысшего среднего показателя 59.5 NDCG@10, превосходя все сравнимые open-source модели, включая те, что вдвое больше по размеру. Компактная модель показывает результат 55.6, обгоняя многих более крупных конкурентов.
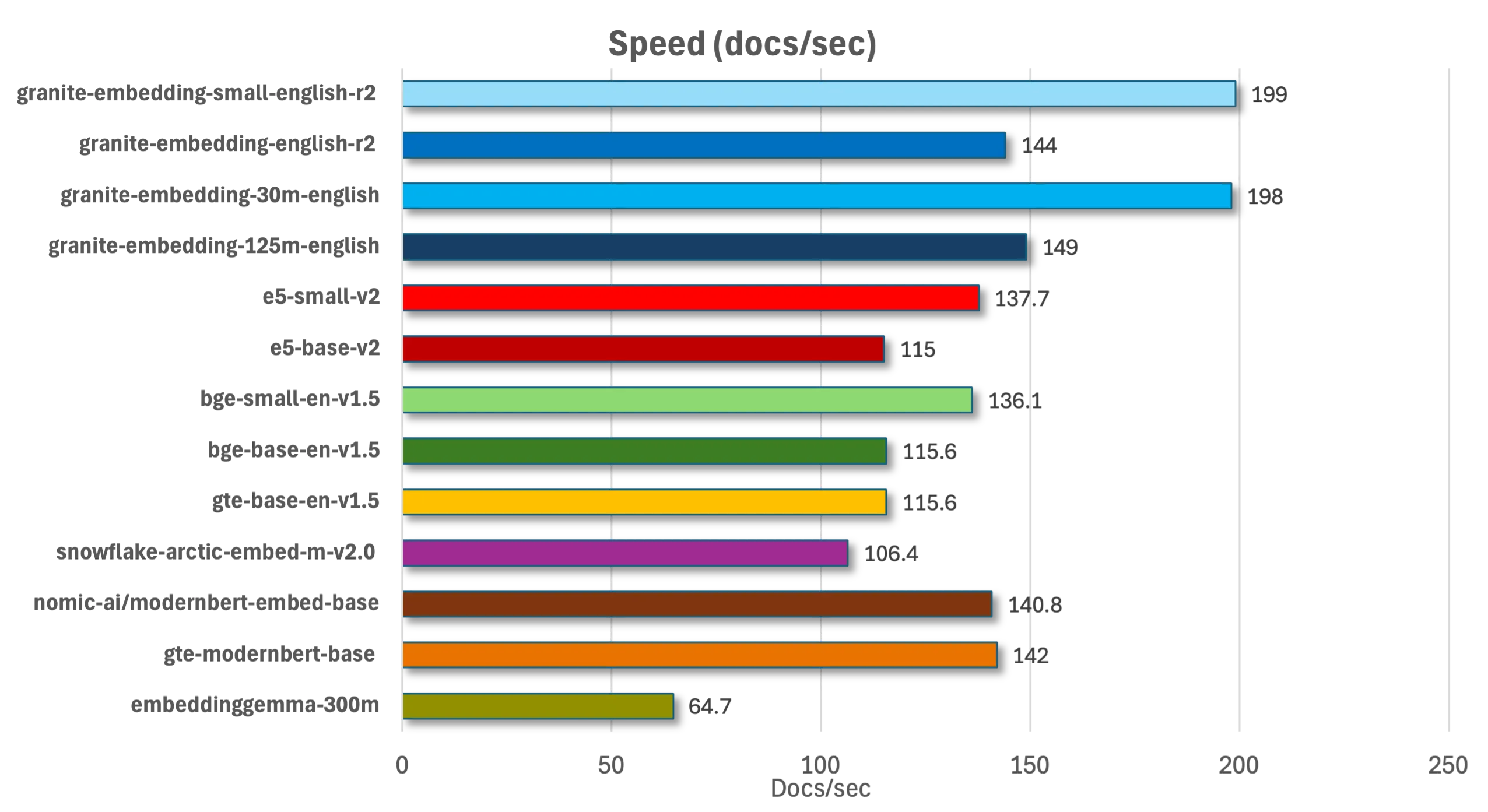
Что касается скорости, тесты на наборе из 23 000 технических документов IBM показали: модели R2 на 19–44% быстрее ведущих конкурентов при сравнимой точности. Особенно впечатляет компактная модель, обрабатывающая почти 200 документов в секунду — идеально для систем реального времени.
Экосистема поиска: модель для переранжирования
Модель переранжирования завершает пайплайн поиска информации. Построенная на основе granite-embedding-english-r2, она использует PListMLE loss для позиционно-осознанного ранжирования.
Этот подход максимизирует как полноту охвата, так и точность результатов без значительных вычислительных затрат.
IBM наконец-то сделала то, о чем многие говорили: создала модели, которые действительно работают в enterprise-сценариях без необходимости выбирать между скоростью и качеством. Особенно впечатляет работа с табличными данными — традиционно слабое место эмбеддинговых моделей. Лицензия Apache 2.0 делает это решение еще более привлекательным для коммерческого использования.
По материалам Hugging Face.





Оставить комментарий