
Оглавление
Сообщество Hugging Face пишет о запуске бета-версии Retrieval Embedding Benchmark (RTEB) — нового бенчмарка для надежной оценки точности поиска эмбеддинг-моделей в реальных приложениях. Существующие подходы к оценке часто не справляются с измерением истинной способности моделей к обобщению, в то время как RTEB решает эту проблему с помощью гибридной стратегии использования открытых и приватных наборов данных.
Проблемы современных бенчмарков
Производительность многих AI-приложений — от RAG-систем и агентов до рекомендательных сервисов — фундаментально ограничена качеством поиска и извлечения информации. Текущий стандарт оценки часто полагается на «zero-shot» производительность моделей на публичных бенчмарках, что в лучшем случае является приблизительной оценкой их реальных возможностей.
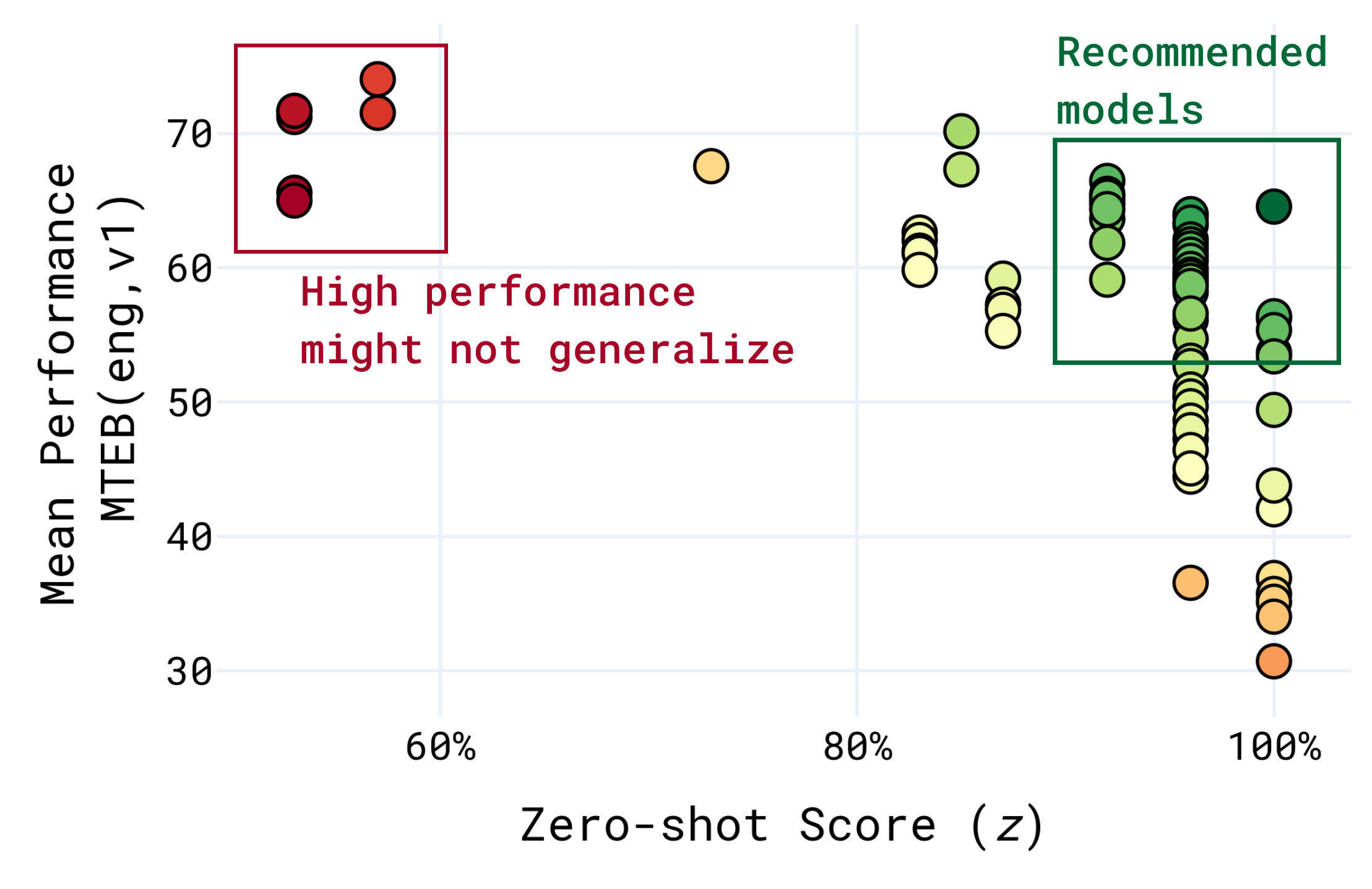
Когда модели многократно тестируются на одних и тех же публичных наборах данных, возникает разрыв между их заявленными показателями и фактической производительностью на новых, ранее невиданных данных.
Ключевые недостатки существующих подходов
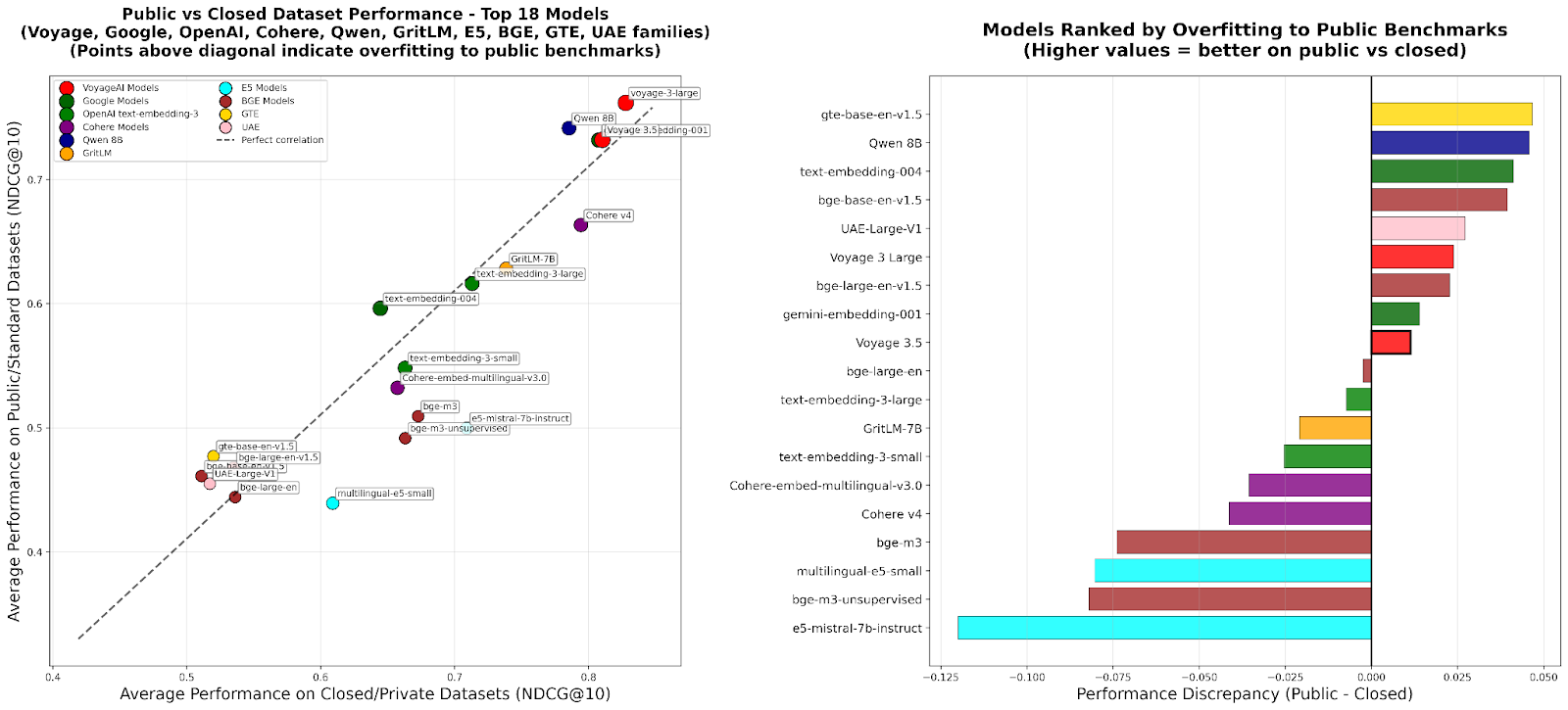
- Проблема обобщения — экосистема бенчмарков непреднамеренно поощряет «обучение под тест». Когда источники обучающих данных пересекаются с оценочными наборами, показатели модели могут быть завышены
- Несоответствие реальным приложениям — многие бенчмарки плохо согласуются с корпоративными сценариями использования. Они часто полагаются на академические наборы данных или задачи поиска, производные от QA-датасетов
Архитектура RTEB
RTEB реализует гибридную стратегию для борьбы с переобучением на бенчмарки:
- Открытые наборы данных — корпус, запросы и метки релевантности полностью публичны
- Приватные наборы данных — эти данные остаются закрытыми, а оценка проводится сопровождающим MTEB для обеспечения беспристрастности
Гибридный подход RTEB — это долгожданное решение проблемы «бенчмарк-дрифта», который стал настоящей чумой для сообщества машинного обучения. Теперь у нас наконец-то появится возможность отличать модели, которые действительно умеют обобщать, от тех, кто просто запомнил тестовые данные. Особенно ценно внимание к мультиязычности и enterprise-доменам — именно там эмбеддинги приносят реальную ценность.
Ключевые особенности бенчмарка
- Мультиязычность — наборы данных охватывают 20 языков, от распространенных вроде английского или японского до редких вроде бенгальского или финского
- Предметная ориентированность — включает датасеты из критически важных enterprise-доменов: право, здравоохранение, код и финансы
- Эффективные размеры наборов — достаточно большие для значимости (не менее 1k документов и 50 запросов), но не чрезмерно
- Поисково-ориентированная метрика — основная метрика лидерборда: NDCG@10, золотой стандарт для качества ранжирования результатов поиска
Полный список датасетов доступен на сайте. Разработчики планируют постоянно обновлять как открытую, так и закрытую части бенчмарка и активно призывают сообщество к участию.





Оставить комментарий