Оглавление
Исследователи Google разработали новый параллельный алгоритм для дифференциально-приватного выбора разделов, который позволяет обрабатывать сотни миллиардов записей данных с сохранением конфиденциальности пользователей. Технология, представленная на ICML2025, существенно улучшает соотношение приватности и полезности данных по сравнению с существующими методами.
Проблема масштабируемой приватности
Современные наборы данных, основанные на пользовательской информации, содержат огромную ценность для развития искусственного интеллекта и машинного обучения. Однако их использование сопряжено с рисками для конфиденциальности. Дифференциально-приватный выбор разделов (DP partition selection) позволяет идентифицировать значимые подмножества уникальных элементов из больших коллекций данных, предотвращая возможность определения вклада отдельного пользователя в финальный результат.
Этот подход является критически важным первым шагом во многих задачах data science, включая:
- Извлечение словаря из корпусов текста
- Анализ потоков данных с сохранением приватности
- Построение гистограмм по пользовательским данным
- Повышение эффективности тонкой настройки моделей
Параллельная обработка данных перестала быть опцией и стала необходимостью. Современные наборы данных просто нереально обрабатывать последовательными методами — это заняло бы непрактично много времени. Новый алгоритм Google решает именно эту проблему масштабируемости.
Как работает алгоритм MAD
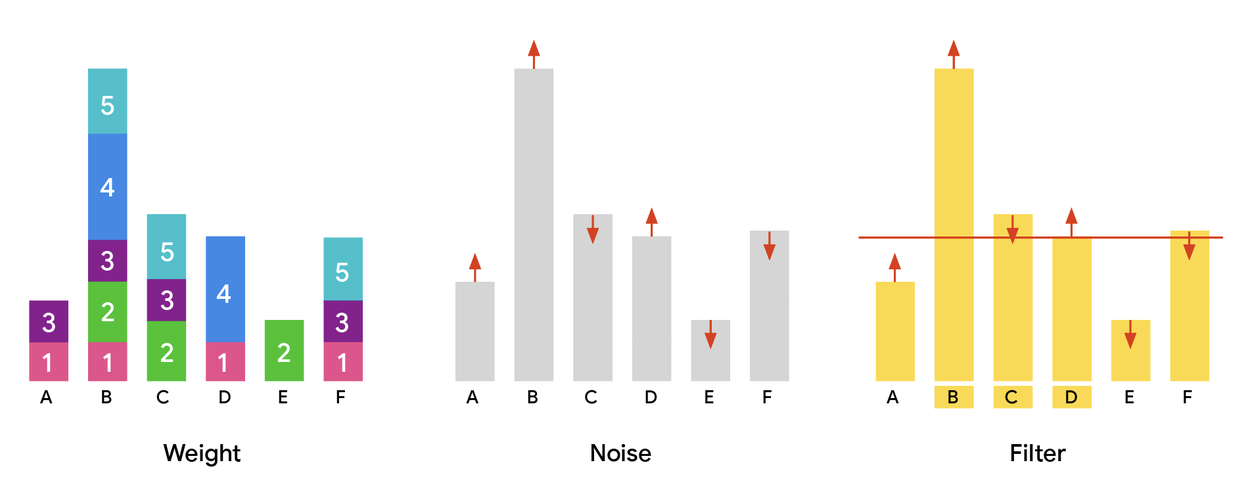
Традиционный подход к дифференциально-приватному выбору разделов включает три этапа: вычисление веса для каждого элемента, добавление шума для обеспечения приватности и фильтрацию по пороговому значению. Однако этот метод имеет существенный недостаток — «перераспределение веса», когда популярные элементы получают значительно больше веса, чем необходимо для преодоления порога.
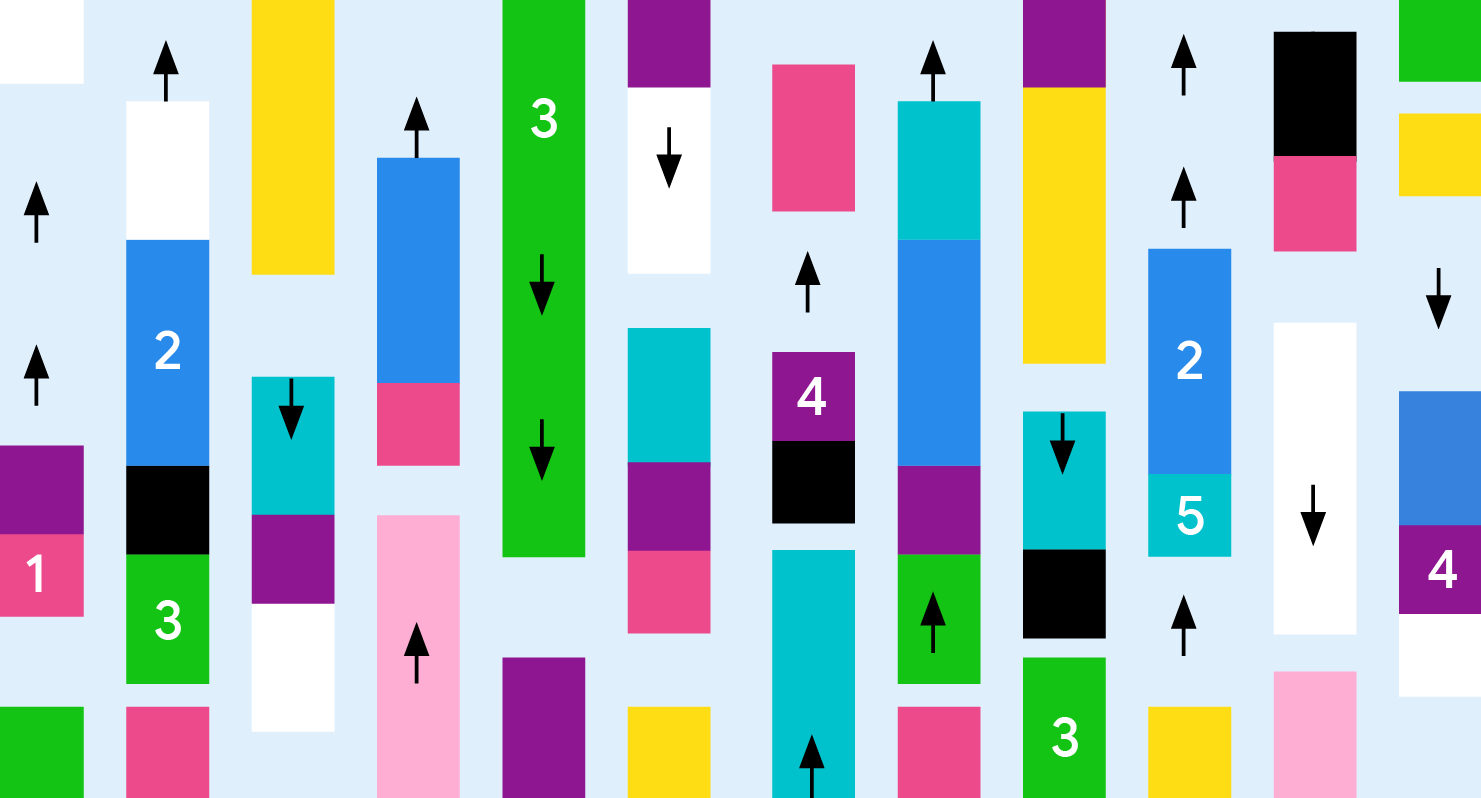
Алгоритм MaxAdaptiveDegree (MAD) вводит адаптивность в процесс назначения весов. В отличие от неадаптивных методов, где вклад каждого пользователя независим, MAD стратегически перераспределяет вес от элементов с избыточным весом к тем, которые находятся чуть ниже порогового значения.
Ключевые преимущества подхода:
- Сохранение тех же границ низкой чувствительности, что и у базового метода
- Обеспечение одинаковой эффективности в параллельных рамках обработки
- Строго лучшее соотношение полезности при тех же гарантиях приватности
Многораундовая адаптивность
Исследователи также расширили концепцию для многораундовых фреймворков выбора разделов. Этот подход позволяет безопасно выпускать промежуточные зашумленные векторы весов между раундами, что обеспечивает еще большую адаптивность.
Дополнительная информация позволяет уменьшить будущие распределения весов для элементов, которые ранее получили слишком много или слишком мало веса, дополнительно уточняя распределение весов и максимизируя полезность без ущерба для приватности.
Экспериментальные результаты
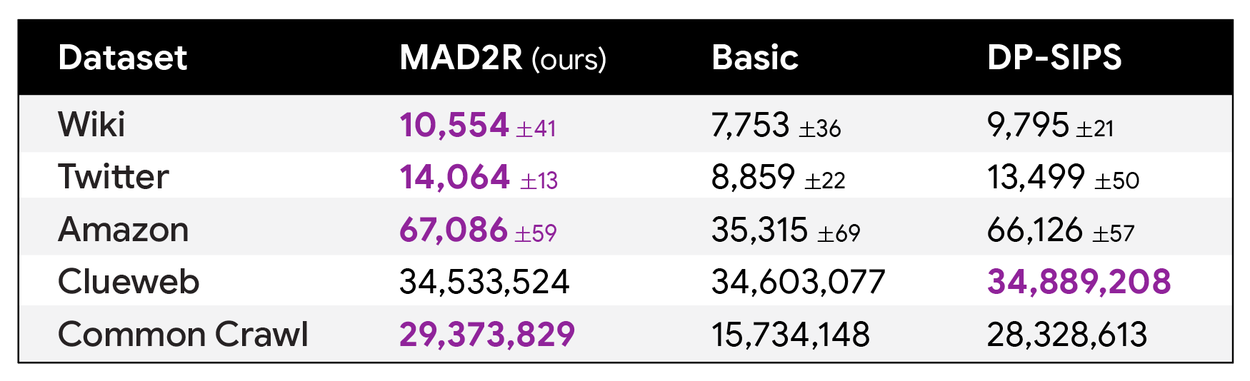
Экстенсивные эксперименты, в ходе которых MAD всего двумя итерациями достигает самых современных результатов во многих наборах данных, часто выдавая значительно больше элементов, чем другие методы при сохранении тех же гарантий конфиденциальности.
Алгоритм масштабируется до наборов данных с сотнями миллиардов элементов, что на три порядка больше, чем мы обрабатывали последовательные алгоритмы. Для поддержки сотрудничества и инноваций исследовательского сообщества Google с открытым исходным кодом реализует алгоритм на GitHub.
Открытие исходного кода — это умный ход со стороны Google. Алгоритмы приватности должны быть прозрачными и доступными для аудита сообществом. Это повышает доверие к таким решениям и ускоряет их принятие в индустрии.
Материал от Google Research.





Оставить комментарий