
Исследователи Google разработали революционный подход к генерации изображений, превращающий процесс в диалог между пользователем и искусственным интеллектом. Система PASTA (Preference Adaptive and Sequential Text-to-image Agent) использует обучение с подкреплением для адаптации к индивидуальным предпочтениям пользователя в реальном времени.
Как работает PASTA
Традиционные модели преобразования текста в изображение часто требуют многочисленных итераций и уточнений промптов для достижения желаемого результата. PASTA решает эту проблему через интерактивный процесс, где пользователь выбирает наиболее близкие варианты из предлагаемых поколений, а система учится на этих предпочтениях.
Технология основана на двухэтапной стратегии обучения:
- Сбор реальных данных взаимодействия с более чем 7000 участников
- Создание симулятора пользователя для генерации дополнительных тренировочных данных
Модель пользователя включает две ключевые компоненты: утилитарную модель, предсказывающую степень удовлетворенности пользователя изображениями, и модель выбора, предсказывающую, какие изображения будут выбраны из предложенных наборов.
Для обучения ИИ понимать человеческие предпочтения компаниям пришлось создать искусственных людей. Симулятор пользователя, идентифицирующий «типы пользователей» по их вкусам — это одновременно и гениально, и слегка пугающе. Особенно учитывая, что система научилась различать любителей животных, пейзажей и абстрактного искусства без явного указания этих категорий.
Архитектура и обучение
PASTA использует обучение с подкреплением на основе ценности с применением неявного Q-обучения. Агент обучается выбирать оптимальные наборы расширений промптов для показа пользователю на каждом шаге взаимодействия.
Процесс работы выглядит следующим образом:
- Пользователь вводит начальный промпт
- Кандидат-генератор (многомодальная модель Gemini Flash) создает разнообразные расширения промпта
- Кандидат-селектор (обученный RL агент) выбирает оптимальный набор из четырех расширений
- Генерируются соответствующие изображения с помощью Stable Diffusion XL
- Пользователь выбирает наиболее близкий вариант
- Процесс повторяется с учетом полученных предпочтений
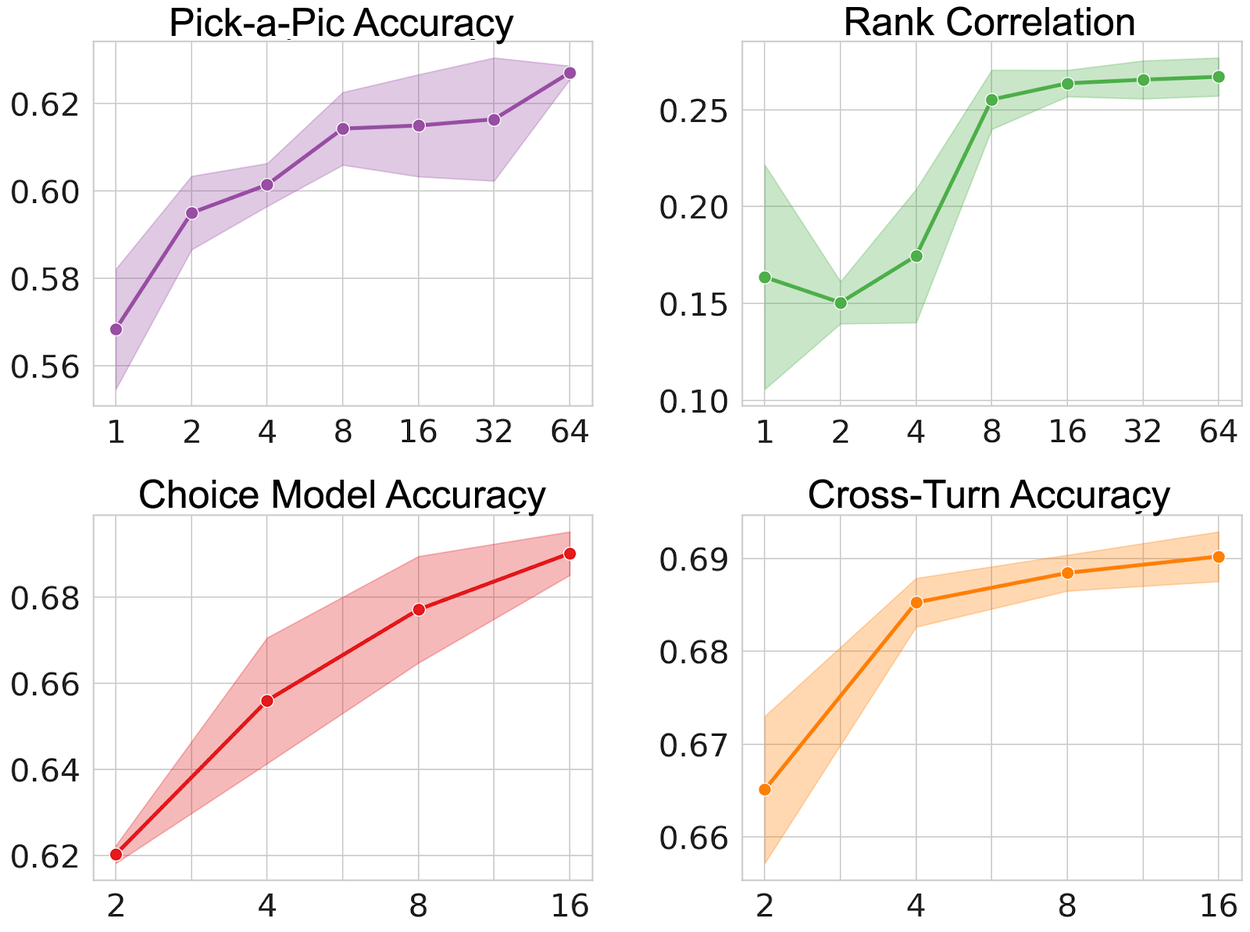
Результаты тестирования
Исследователи сравнили три версии агента: обученную только на реальных данных, только на симулированных данных, и на комбинации обоих наборов. Тестирование проводилось по четырем метрикам:
- Точность на наборе данных Pick-a-Pic
- Корреляция Спирмена
- Точность модели выбора
- Межшаговая точность

Агент, обученный на комбинированных данных, показал наилучшие результаты, превзойдя базовые модели. В прямом сравнении конечных изображений 85% участников предпочли результаты PASTA.
По материалам Google Research





Оставить комментарий