
Google выпустила EmbeddingGemma — новую модель для создания текстовых эмбеддингов, оптимизированную для работы на мобильных устройствах. Модель с 308 миллионами параметров поддерживает более 100 языков и показывает наилучшие результаты в своем классе на бенчмарке MTEB.
Технические особенности
EmbeddingGemma построена на архитектуре Gemma3, но использует двунаправленное внимание вместо каузального, что превращает ее из декодера в энкодер. Это позволяет модели обрабатывать до 2048 токенов контекста и создавать более качественные эмбеддинги для задач поиска и классификации.
Ключевые характеристики модели:
- 308 миллионов параметров — компактный размер для мобильных устройств
- Поддержка 100+ языков — мультиязычность из коробки
- Контекстное окно 2K токенов — достаточно для большинства практических задач
- Matryoshka Representation Learning — возможность уменьшения размерности эмбеддингов до 128 измерений
Интеграция и применение
Модель уже интегрирована с популярными фреймворками:
- Sentence Transformers
- LangChain
- LlamaIndex
- Haystack
- Transformers.js
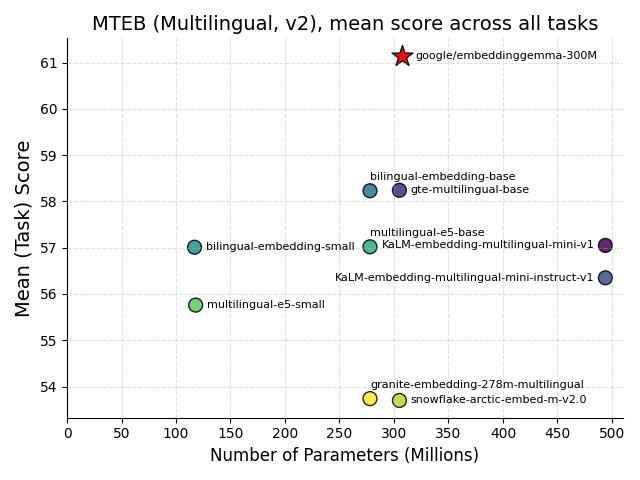
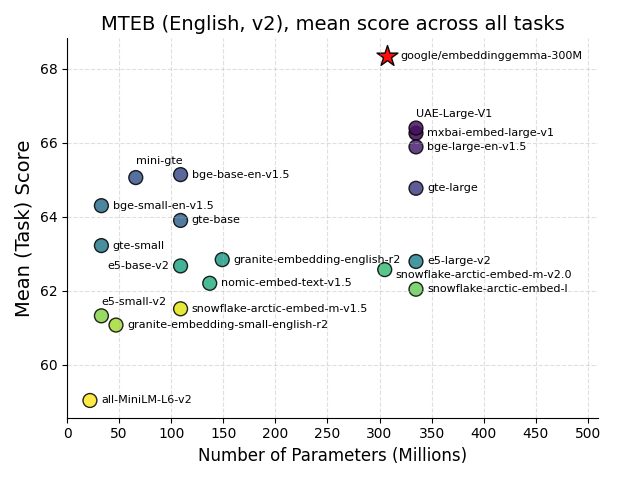
Компактные модели эмбеддингов — это тот случай, когда меньше действительно значит больше. Возможность запуска на устройстве без облачных вызовов меняет правила игры для мобильных RAG-пайплайнов и агентов. Особенно впечатляет поддержка 100 языков — для многих рынков это означает возможность строить семантический поиск без гигантских инфраструктурных затрат. Google снова показывает, что эффективность может быть важнее размера.
Обучение и производительность
Модель обучалась на корпусе из 320 миллиардов токенов, включающем веб-тексты, код и синтетические примеры. На бенчмарке MMTEB EmbeddingGemma показывает лучшие результаты среди моделей с менее чем 500 миллионами параметров.
Интересно, что после дообучения на медицинских данных модель превзошла конкурентов вдвое большего размера в задачах поиска медицинской информации.
Пишет Hugging Face





Оставить комментарий