
Оглавление
Компания Google Research анонсировала революционный подход к голосовому поиску под названием Speech-to-Retrieval (S2R), который позволяет получать ответы непосредственно из голосового запроса без необходимости предварительного преобразования в текст. Эта технология обещает сделать поиск быстрее и надежнее для всех пользователей.
Проблемы традиционного голосового поиска
Голосовой веб-поиск существует уже давно и продолжает использоваться многими людьми, при этом базовые технологии быстро развиваются для расширения возможностей применения. Изначальное решение Google для голосового поиска использовало автоматическое распознавание речи (ASR) для преобразования голосового ввода в текстовый запрос с последующим поиском документов, соответствующих этому текстовому запросу.
Однако проблема каскадного подхода моделирования заключается в том, что даже небольшие ошибки на этапе распознавания речи могут значительно изменить смысл запроса, производя неверные результаты.
Например, представьте, что кто-то выполняет голосовой поиск знаменитой картины «Крик» Эдварда Мунка. Поисковая система использует типичный подход каскадного моделирования, сначала преобразуя голосовой запрос в текст через ASR, прежде чем передать текст поисковой системе. В идеале ASR идеально транскрибирует запрос. Поисковая система получает правильный текст — «картина Крик» — и предоставляет релевантные результаты, такие как история картины, её значение и где она выставлена. Однако что, если система ASR ошибочно принимает «м» в «крик» за «н»? Она неправильно интерпретирует запрос как «экранная живопись» и возвращает нерелевантные результаты о технике экранной печати вместо деталей о шедевре Мунка.
Традиционный подход к голосовому поиску напоминает игру в испорченный телефон — каждый дополнительный этап обработки добавляет шум и искажения. S2R пытается решить фундаментальную проблему: зачем сначала переводить речь в текст, если конечная цель — найти информацию, а не просто расшифровать слова? Это похоже на попытку понять иностранный язык через двойной перевод вместо прямого общения.
Оценка потенциала S2R
Когда традиционная система ASR преобразует аудио в единую текстовую строку, она может потерять контекстные подсказки, которые могли бы помочь устранить неоднозначность значения (т.е. потерю информации). Если система неправильно интерпретирует аудио на раннем этапе, эта ошибка передается поисковой системе, которая обычно не может её исправить (т.е. распространение ошибки). В результате конечный результат поиска может не отражать намерения пользователя.
Для исследования этой взаимосвязи был проведен эксперимент, имитирующий идеальную производительность ASR. Была собрана репрезентативная выборка тестовых запросов, отражающих типичный трафик голосового поиска. Эти запросы были вручную транскрибированы аннотаторами-людьми, эффективно создавая сценарий «идеальной ASR», где транскрипция является абсолютной истиной.
Были установлены две различные поисковые системы для сравнения:
- Cascade ASR представляет типичную реальную настройку, где речь преобразуется в текст системой автоматического распознавания речи, и этот текст затем передается в систему поиска.
- Cascade groundtruth имитирует «идеальную» каскадную модель, отправляя безупречный эталонный текст напрямую в ту же систему поиска.
Извлеченные документы из обеих систем были представлены человеческим оценщикам вместе с исходным истинным запросом. Оценщики должны были сравнить результаты поиска обеих систем, предоставляя субъективную оценку их соответствующего качества.
Для измерения качества ASR используется коэффициент ошибок по словам (WER), а для измерения производительности поиска используется средний обратный ранг (MRR) — статистическая метрика для оценки любого процесса, который производит список возможных ответов на выборку запросов, упорядоченных по вероятности правильности и рассчитываемых как среднее значение обратных величин ранга первого правильного ответа по всем запросам.
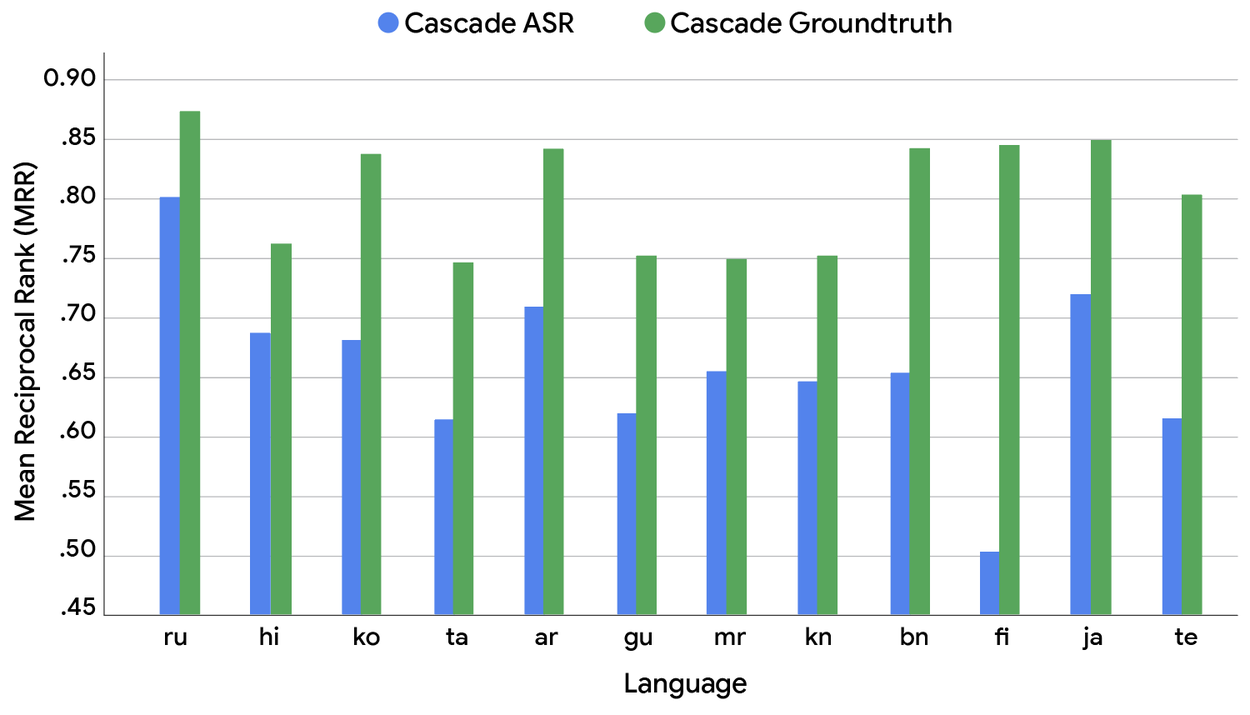
Коэффициент ошибок по словам (WER) модели ASR в различных языках голосового поиска в наборе данных SVQ.
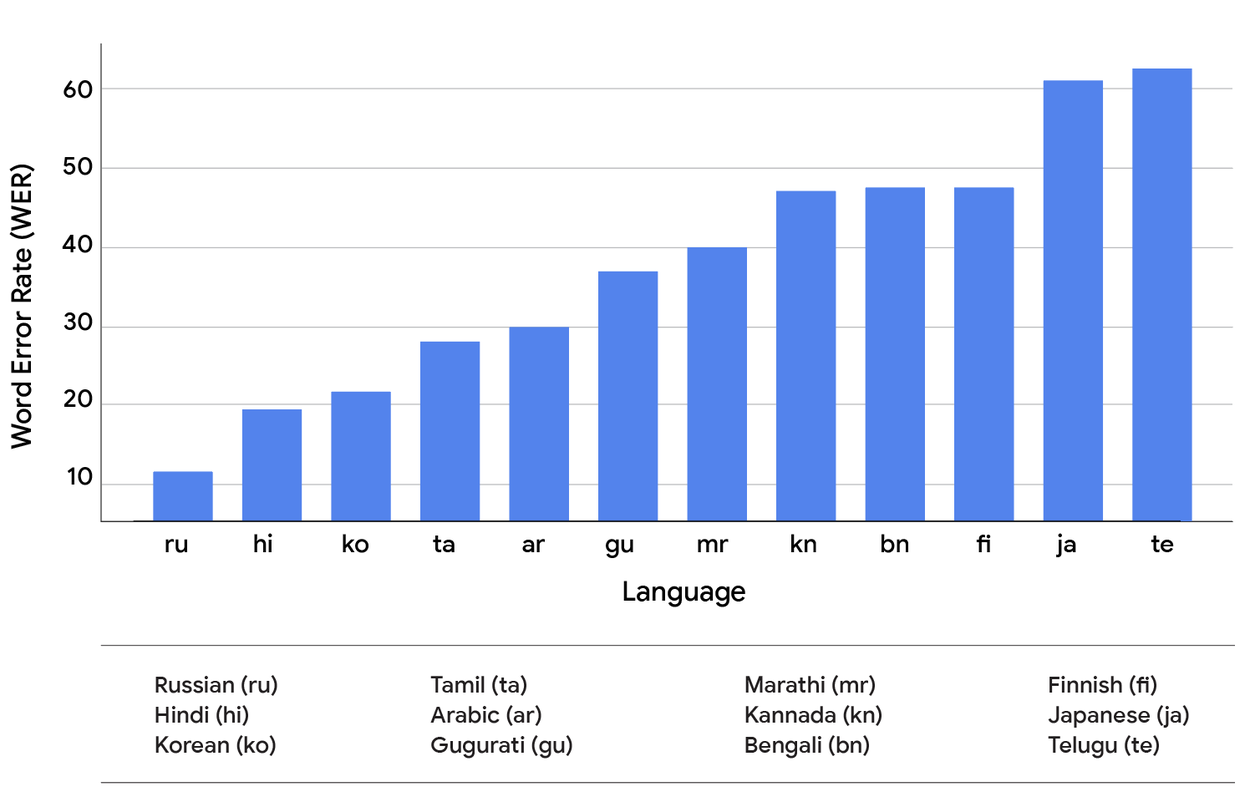
MRR текущих реальных моделей («Cascade ASR»; синий) против эталонной истины (т.е. идеальной; «Cascade Groundtruth»; зеленый).
Результаты этого сравнения приводят к двум критическим наблюдениям. Во-первых, как видно из сравнения обеих диаграмм выше, мы обнаружили, что более низкий WER не надежно приводит к более высокому MRR в разных языках. Взаимосвязь сложна, что предполагает, что влияние ошибок транскрипции на последующие задачи полностью не захватывается метрикой WER. Конкретная природа ошибки — не просто её существование — оказывается критическим, зависящим от языка фактором. Во-вторых, и что более важно, существует значительная разница в MRR между двумя системами во всех протестированных языках. Это раскрывает существенный разрыв в производительности между текущими каскадными конструкциями и тем, что теоретически возможно с идеальным распознаванием речи. Этот разрыв представляет собой явный потенциал для моделей S2R фундаментально улучшить качество голосового поиска.
Архитектура S2R: от звука к смыслу
В основе модели S2R лежит архитектура с двойным кодировщиком. Эта конструкция включает две специализированные нейронные сети, которые обучаются на огромных объемах данных, чтобы понимать взаимосвязь между речью и информацией. Аудио-кодировщик обрабатывает исходное аудио запроса, преобразуя его в богатое векторное представление, которое захватывает его семантическое значение. Параллельно кодировщик документов изучает аналогичное векторное представление для документов.
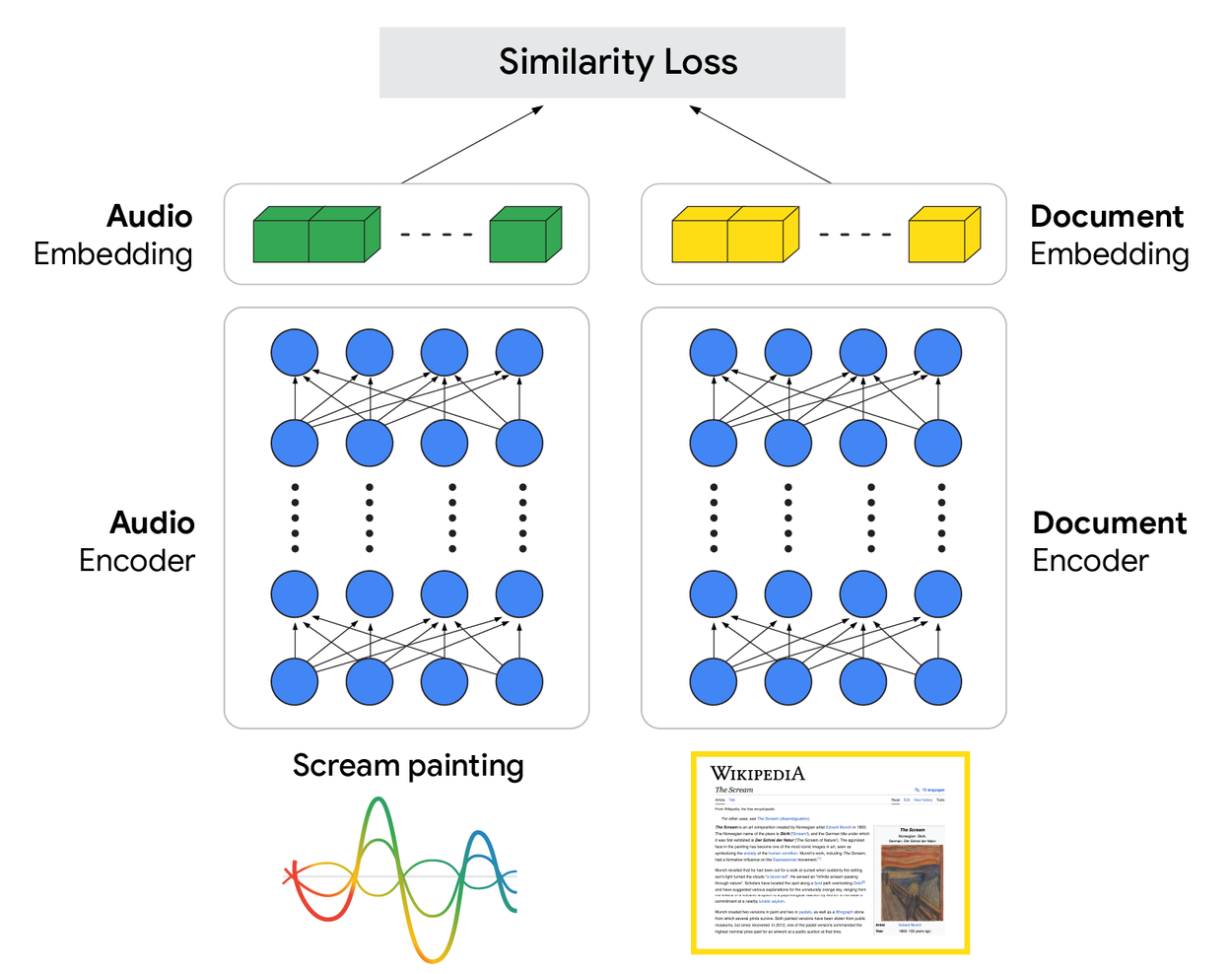
Разница в потере сходства между аудио и документным embedding.
Ключ к этой модели — как она обучается. Используя большой набор данных парных аудио запросов и релевантных документов, система учится одновременно настраивать параметры обоих кодировщиков.
Цель обучения обеспечивает, чтобы вектор для аудио запроса был геометрически близок к векторам соответствующих документов в пространстве представления. Эта архитектура позволяет модели изучать нечто ближе к существенному намерению, необходимому для извлечения непосредственно из аудио, обходя хрупкий промежуточный шаг транскрибирования каждого слова, который является главной слабостью каскадного дизайна.
Как работает модель S2R
Когда пользователь произносит запрос, аудио передается в предварительно обученный аудио-кодировщик, который генерирует вектор запроса. Этот вектор затем используется для эффективного идентификации высокорелевантного набора кандидатов результатов из нашего индекса через сложный процесс ранжирования поиска.
Технология S2R выглядит элегантно на бумаге, но реальные вызовы начинаются при масштабировании на десятки языков и миллиарды документов. Прямое сопоставление аудио с семантическим пространством требует колоссальных вычислительных ресурсов и тщательно сбалансированных обучающих данных. Интересно, сможет ли Google преодолеть классическую дилемму «точность против покрытие» — показывать блестящие результаты на демо-запросах, но спотыкаться на редких или сложных запросах в реальном мире.
По материалам Google Research.





Оставить комментарий