Оглавление
Исследователи Google разработали CTCL — новый метод генерации дифференциально приватных синтетических данных, избегающий ресурсоёмкой тонкой настройки миллиардных языковых моделей. Работа представлена на ICML 2025.
Проблема существующих подходов
Традиционные методы синтеза данных с дифференциальной приватностью (DP) сталкиваются с трилеммой: строгая приватность ухудшает качество данных, требует гигантских вычислений или сложной ручной работы с промптами. Попытки обойти тонкую настройку LLM, вроде Aug-PE и Pre-Text, остаются зависимыми от ручного контекста и неэффективно используют приватную информацию.
Архитектура CTCL
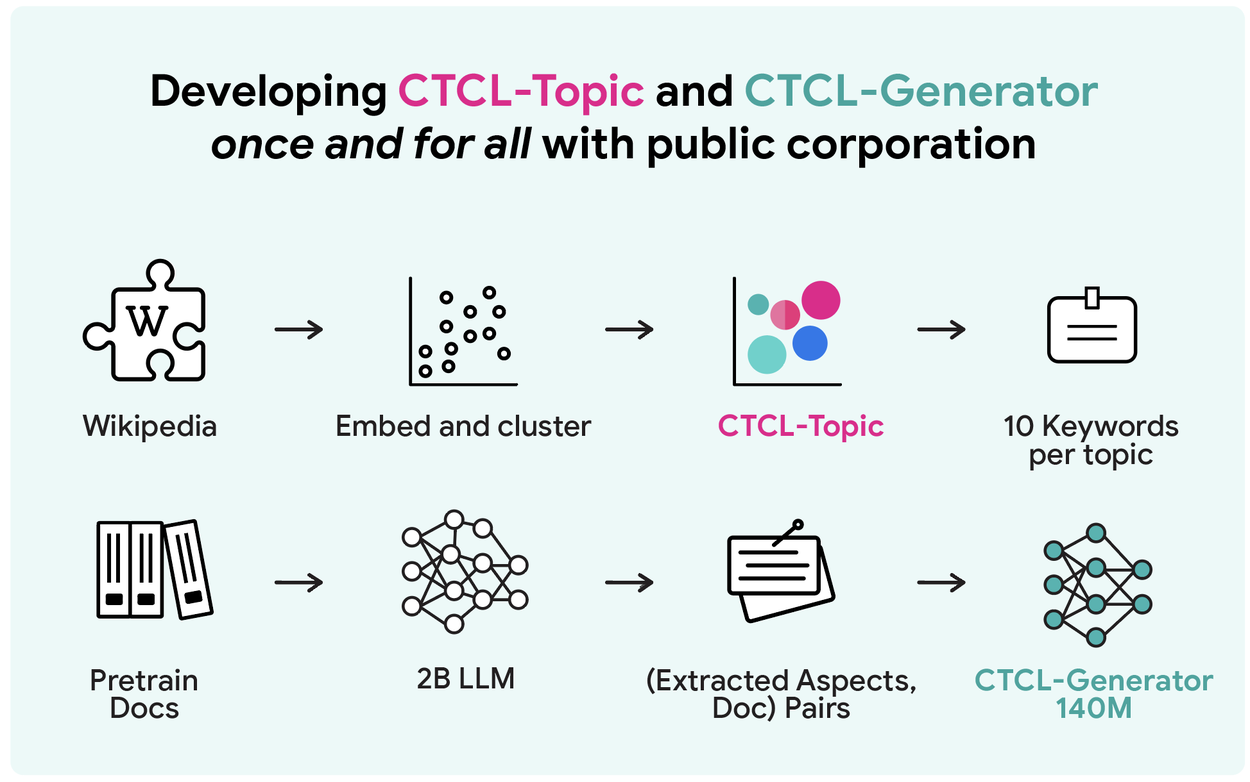
Фреймворк использует два предобученных на публичных данных компонента:
- CTCL-Topic: универсальная тематическая модель (1 000 кластеров на базе Wikipedia)
- CTCL-Generator: 140-миллионный условный языковой модель, дообученный на 430 млн пар «описание-документ» из SlimPajama
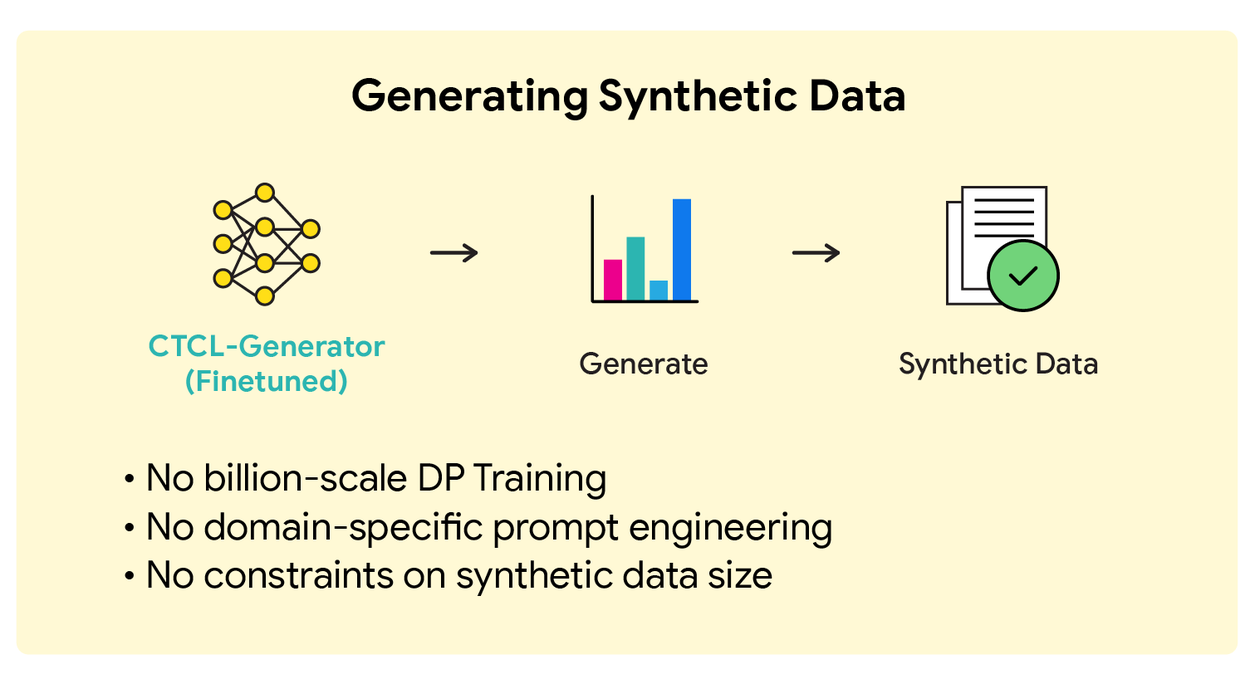
Трёхэтапный процесс
Шаг 1: Анализ приватных данных
CTCL-Topic строит DP-гистограмму тематического распределения данных. Каждый документ ассоциируется с 10 ключевыми словами своей темы.
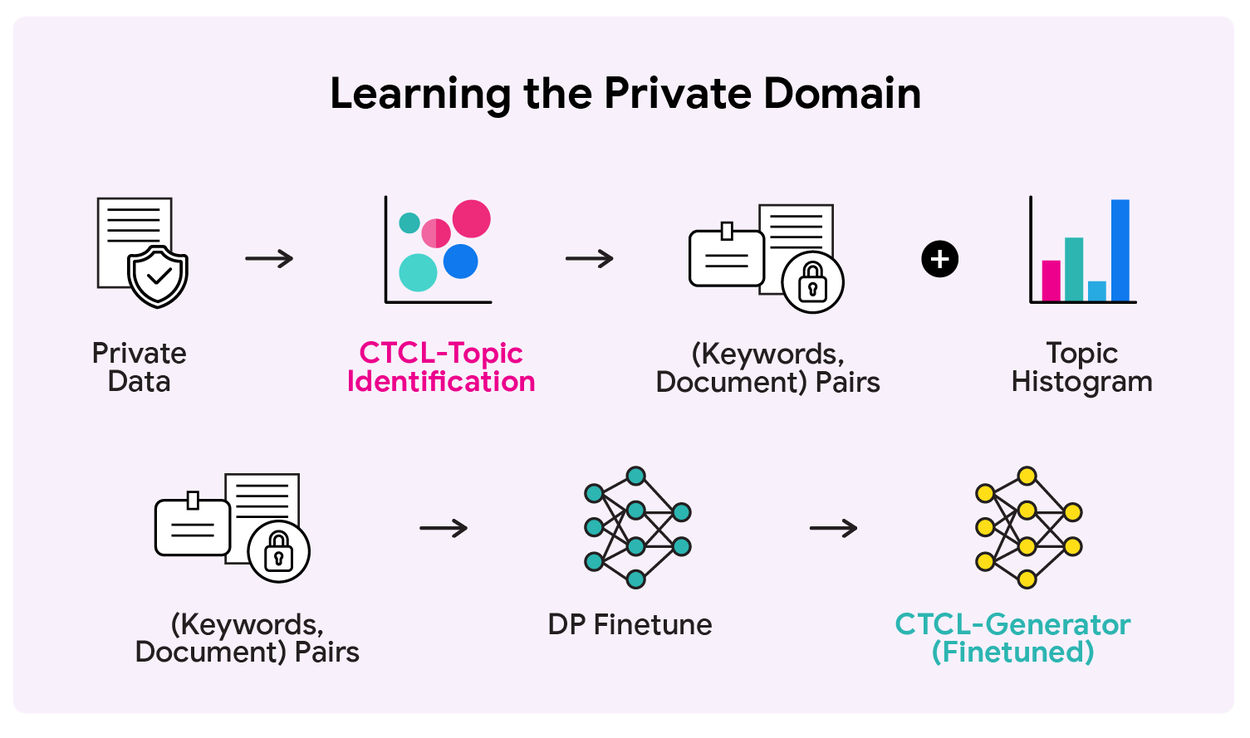
Шаг 2: Адаптация генератора
CTCL-Generator дообучается с дифференциальной приватностью на парах «ключевые слова — документ» из приватного набора.
Шаг 3: Синтез данных
Генератор создаёт тексты по темам пропорционально гистограмме. Благодаря постобработке DP, объём синтетических данных не ограничен дополнительными затратами приватности.
CTCL — тактичный ответ на AI-инфляцию: вместо погони за параметрами авторы переосмыслили конвейер данных. Локальная 140M модель не просто дешевле — она снимает зависимость от облачных API и риски утечек через промпты. Особенно ценно для медицины или финансов, где каждый запрос к LLM — потенциальная брешь. Но вопрос остаётся: как метод масштабируется на мультимодальные данные? Пока это элегантное решение для текста, но не панацея.
Валидация на практических задачах
Тестирование на четырёх датасетах (PubMed, Chatbot Arena, Multi-Session Chat, OpenReview) показало превосходство над аналогами в генеративных задачах (предсказание токенов) и классификации. В условиях жёстких DP-гарантий CTCL сохраняет до 17% больше полезности данных.
Источник: Google Research Blog





Оставить комментарий