
Оглавление
По мере развития больших языковых моделей обучение с подкреплением становится ключевой технологией для их согласования с человеческими предпочтениями и сложными задачами. Однако компании сталкиваются с инфраструктурными вызовами при реализации и масштабировании RL для LLM.
Что такое обучение с подкреплением для LLM
RL представляет собой непрерывный цикл обратной связи, сочетающий элементы обучения и вывода. Основной процесс выглядит следующим образом:
- Языковая модель генерирует ответ на заданный промпт
- Модель вознаграждения присваивает количественную оценку выходным данным
- Алгоритм RL использует этот сигнал для обновления параметров LLM
Рабочие нагрузки RL являются гибридными и циклическими. Основная цель — не минимизация ошибки или быстрое предсказание, а максимизация вознаграждения через итеративное взаимодействие.
Комплексный подход Google Cloud
Для решения системных проблем требуется интегрированный подход. Google Cloud предлагает четырехкомпонентную стратегию:
- Гибкие высокопроизводительные вычисления: Поддержка как TPU, так и GPU экосистем
- Полностековая оптимизация: Интеграция от аппаратного обеспечения до оркестрации
- Лидерство в open-source: Активное участие в проектах Kubernetes, Ray, vLLM
- Проверенная оркестрация мега-масштаба: Поддержка кластеров до 65 000 узлов
Интересно наблюдать, как облачные провайдеры превращают сложнейшие ML-практики в готовые сервисы. Подход Google с полностековой оптимизацией выглядит стратегически верным — вместо отдельных ускорений они оптимизируют всю цепочку, что критично для гибридных RL-нагрузок. Хотя заявления о поддержке 65-тысячных кластеров звучат впечатляюще, на практике большинству компаний достаточно куда более скромных мощностей.
Запуск RL-нагрузок на GKE
Существующая инфраструктура GKE хорошо подходит для требовательных RL-рабочих нагрузок и обеспечивает несколько инфраструктурных преимуществ.
Источник: cloud.google.com
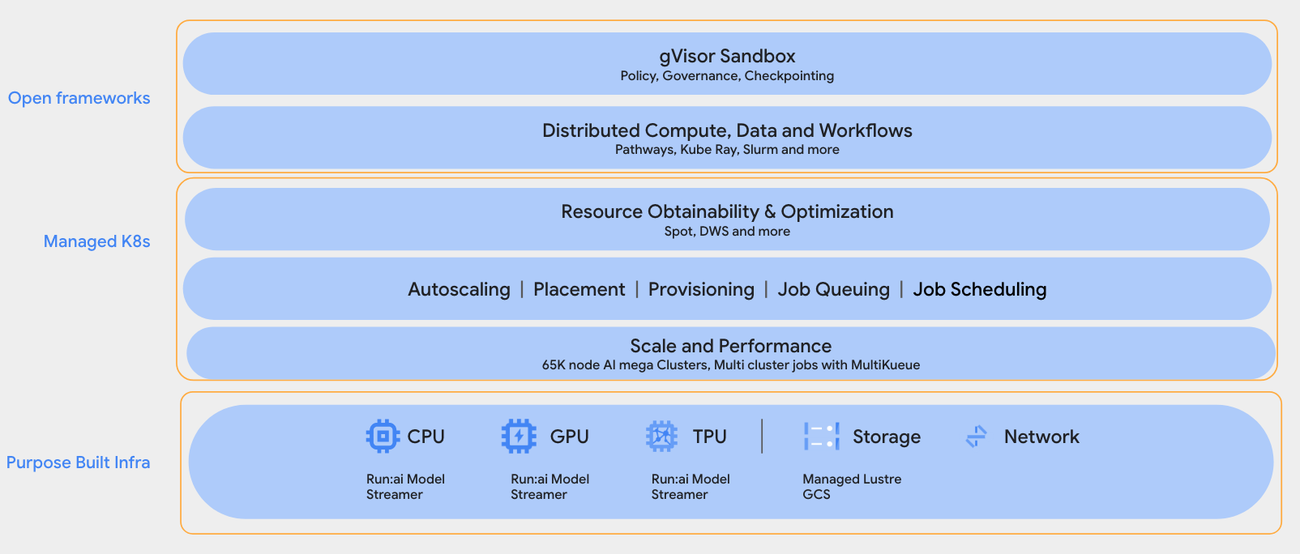
Базовая инфраструктурная слой включает поддерживаемые типы вычислений (CPU, GPU и TPU). Можно использовать Run:ai model streamer для ускорения потоковой передачи моделей. Высокопроизводительное хранилище (Managed Lustre, Cloud Storage) используется для потребностей хранения данных RL.
Средний слой — управляемый Kubernetes от GKE, который обрабатывает оркестрацию ресурсов, доступность ресурсов с использованием Spot или Dynamic Workload Scheduler, автомасштабирование, размещение, очереди заданий и планирование заданий в мега-масштабе.
Верхний слой открытых фреймворков работает поверх GKE, предоставляя прикладную среду выполнения. Это включает управляемую поддержку инструментов с открытым исходным кодом, таких как KubeRay, Slurm и gVisor sandbox для безопасного изолированного выполнения задач.
Создание RL-воркфлоу
Перед созданием RL-нагрузки необходимо определить четкий вариант использования. Затем архитектура основных компонентов включает выбор алгоритма (например, DPO, GRPO), сервера моделей (как vLLM или SGLang), целевого оборудования GPU/TPU и других критических конфигураций.
Далее можно подготовить кластер GKE, настроенный с Workload Identity, GCS Fuse и DGCM метриками. Для надежной пакетной обработки устанавливаются API Kueue и JobSet. Рекомендуется развертывание Ray как оркестратора поверх этого стека GKE. После этого можно запускать контейнер Nemo RL, настраивать его для GRPO задания и начинать мониторинг выполнения. Подробные шаги реализации и исходный код доступны в репозитории.
Для начала работы с RL выполните шаги:
- Попробуйте RL на TPU с использованием MaxText и Pathways для алгоритма GRPO, или если используете GPU, NemoRL рецепты
- Присоединяйтесь к сообществу llm-d, изучите репозиторий на GitHub и помогите определить будущее open-source обслуживания LLM
По материалам Google Cloud Blog.





Оставить комментарий