
Оглавление
Исследователи Google разработали систему машинного обучения, которая значительно улучшает эффективность размещения виртуальных машин в дата-центрах. Решение основано на непрерывном прогнозировании времени жизни VM и позволяет снизить потери ресурсов на 4,5% за счет сокращения миграций.
Проблема облачного тетриса
Представьте себе игру в тетрис, где фигуры постоянно появляются и исчезают с разной скоростью. Именно такую задачу решают облачные дата-центры несколько раз в секунду, пытаясь оптимально разместить виртуальные машины на физических серверах. Проблема усугубляется тем, что время жизни VM изначально неизвестно — некоторые работают минуты, другие дни.
На крупных масштабах эффективное использование ресурсов критически важно как по экономическим, так и по экологическим причинам. Плохое распределение VM приводит к «застреванию ресурсов» — когда на сервере остаются слишком маленькие или несбалансированные ресурсы, непригодные для размещения новых VM. Это фактически означает потерю мощности.
Классическая задача упаковки в контейнеры становится значительно сложнее из-за неполной информации о поведении виртуальных машин. Традиционные подходы с единичным прогнозом при создании VM часто терпят неудачу — одна ошибка предсказания может заблокировать целый хост на длительное время.
От точечных прогнозов к вероятностным распределениям
Ключевое открытие исследования заключается в том, что время жизни виртуальных машин часто непредсказуемо и следует длиннохвостому распределению. Например, подавляющее большинство VM (88%) живут менее часа, но потребляют лишь 2% от всех ресурсов. Это означает, что размещение небольшого количества долгоживущих VM оказывает непропорционально большое влияние на общую эффективность.
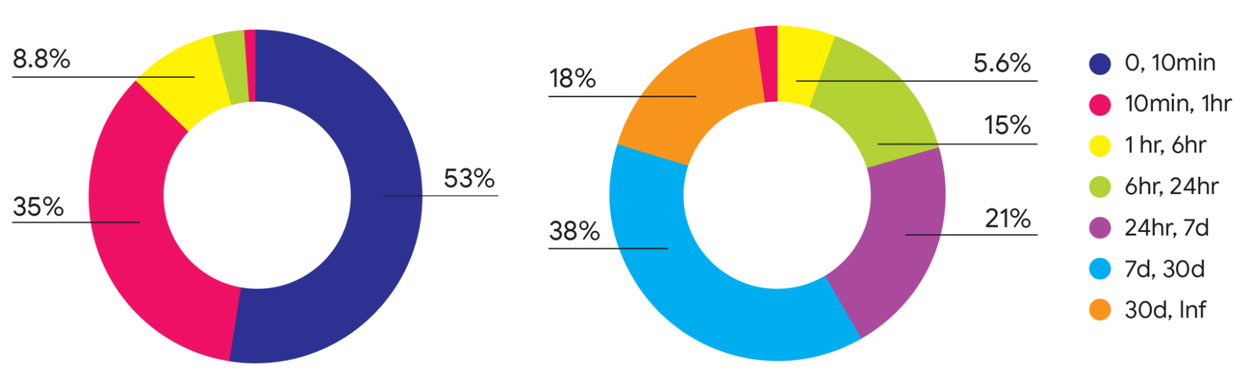
Распределение времени жизни запланированных VM ( слева ) в сравнении с их потреблением ресурсов ( справа ). Короткие задачи (0–10 мин, темно-синий), составляющие 53% по количеству, занимают незначительную долю ресурсов. В то же время самые долгие задачи (>30 дней, оранжевый), потребляющие значительные ресурсы (18%), составляют ничтожную долю по количеству.
Вместо попыток предсказать среднее время жизни, что может быть обманчиво для VM с бимодальным или сильно варьирующимся временем работы, исследователи создали ML-модель, предсказывающую вероятностное распределение времени жизни VM. Этот подход, вдохновленный анализом выживаемости, позволяет модели учитывать присущую VM неопределенность.
Система использует это распределение для постоянного обновления прогнозов. Вопрос формулируется так: «Если VM работает уже пять дней, каково её ожидаемое оставшееся время жизни?» По мере продолжения работы VM система получает больше информации, и её прогноз становится точнее.
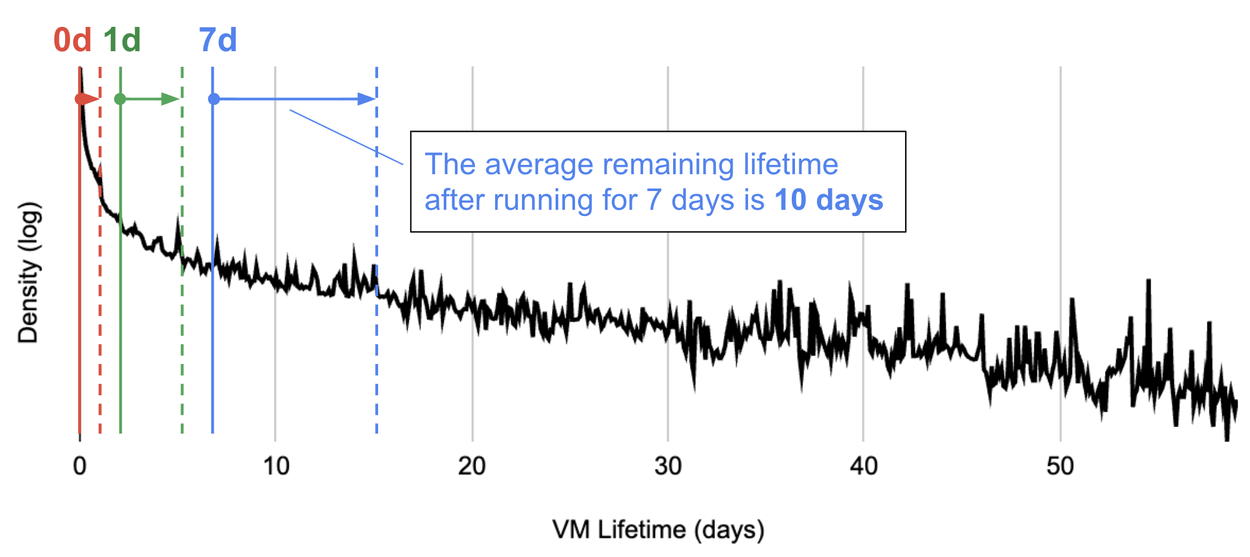
Распределение времени жизни VM. Когда VM планируется, ожидаемое время жизни составляет 0,2 дня. После работы в течение 1 дня ожидаемое оставшееся время жизни составляет 4 дня. После 7 дней — 10 дней.
Три алгоритма для оптимальной упаковки
С новой, более надежной моделью прогнозирования были разработаны три новых алгоритма для улучшения распределения VM.
1. Неинвазивное планирование с учетом времени жизни (NILAS)
NILAS — неинвазивный алгоритм, который встраивает прогнозы времени жизни в существующую функцию оценки. Он ранжирует потенциальные хосты для новой VM, учитывая перепрогнозированное время выхода всех существующих VM на этом хосте. Приоритезируя хосты, где все VM ожидаемо завершатся примерно в одно время, NILAS стремится создавать больше пустых машин.
2. Распределение VM с учетом времени жизни (LAVA)
LAVA представляет собой более фундаментальный отход от существующих механизмов планирования. В то время как NILAS стремится упаковывать VM с похожим временем жизни, LAVA делает противоположное: размещает короткоживущие VM на хостах с одной или несколькими долгоживущими VM. Цель — заполнить пробелы в ресурсах короткоживущими VM, которые завершаются значительно раньше, чем ожидаемое время жизни хоста.
3. Перепланирование с учетом времени жизни (LARS)
LARS использует прогнозы времени жизни для минимизации нарушений работы VM во время дефрагментации и обслуживания. Когда хост нужно дефрагментировать, LARS сортирует VM на этом хосте по прогнозируемому оставшемуся времени жизни и мигрирует сначала самые долгоживущие VM. Короткоживущие VM завершаются естественным образом до миграции.
Подход с непрерывным перепрогнозированием — это тот редкий случай, когда инженерная элегантность встречается с практической эффективностью. Вместо того чтобы пытаться один раз угадать судьбу виртуальной машины, система постоянно пересматривает свои предположения, становясь умнее с каждым днем работы VM. Особенно впечатляет решение с компиляцией модели прямо в бинарник планировщика — это не просто технический трюк, а философский подход к надежности распределенных систем.
Масштабирование без циклических зависимостей
Разработка мощных моделей и алгоритмов — лишь часть решения. Для работы в крупном масштабе потребовалось переосмыслить подход к развертыванию моделей.
Обычная практика — обслуживание моделей машинного обучения на выделенных серверах вывода. Однако это создало бы циклическую зависимость, поскольку сами эти серверы работали бы в системе планирования кластеров. Сбой в уровне обслуживания моделей мог вызвать каскадный сбой в самом планировщике.
Решение заключалось в компиляции модели непосредственно в бинарник планировщика Borg. Этот подход устранил циклическую зависимость и обеспечил, что модель тестировалась и развертывалась по тому же строгому процессу, что и любое другое изменение кода планировщика.
Дополнительным преимуществом стала скорость: медианная задержка модели составляет всего 9 микросекунд, что в 780 раз быстрее подхода с использованием отдельных серверов моделей. Такая низкая задержка критически важна для частого выполнения перепрогнозов и использования модели в задачах, чувствительных к производительности.
По материалам Google Research.





Оставить комментарий