Оглавление
Исследователи из Калифорнийского университета в Беркли, Стэнфорда и Databricks представили новый метод оптимизации GEPA, который значительно превосходит традиционные методы обучения с подкреплением (RL) для адаптации больших языковых моделей к специализированным задачам, сообщает VentureBeat.
Высокая стоимость оптимизации современных AI-систем
Современные корпоративные AI-приложения редко представляют собой единый вызов LLM. Чаще это сложные workflows, объединяющие несколько модулей LLM, внешние инструменты вроде баз данных или интерпретаторов кода, и custom-логику для выполнения сложных задач, включая многоэтапные исследования и анализ данных.
Популярный метод оптимизации таких систем — обучение с подкреплением, например Group Relative Policy Optimization (GRPO), используемый в таких моделях как DeepSeek-R1. Главный недостаток RL — неэффективность использования данных: методы требуют десятки или сотни тысяч пробных запусков («rollouts»), что делает процесс непомерно дорогим для реальных enterprise-приложений.
Для многих команд RL непрактичен из-за стоимости и сложности — их стандартный подход часто сводился к ручному prompt engineering
Оптимизатор, который учится на языке
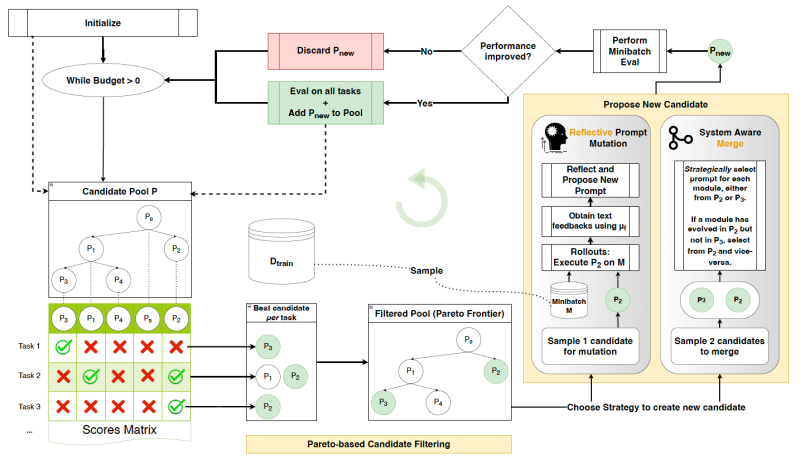
GEPA (Genetic-Pareto) решает эту проблему, заменяя скудные rewards богатой обратной связью на естественном языке. Методология строится на трех столпах:
- Генетическая эволюция промптов — GEPA рассматривает популяцию промптов как генетический пул, итеративно «мутируя» их для создания новых версий
- Рефлексия с NLP-фидбеком — после нескольких запусков LLM анализирует полный trace выполнения и outcome, диагностируя проблемы и создавая улучшенные промпты
- Парето-селекция — вместо фокуса на единственном лучшем промпте, GEPA поддерживает разнообразный ростер «специалистов», обеспечивая лучшее обобщение
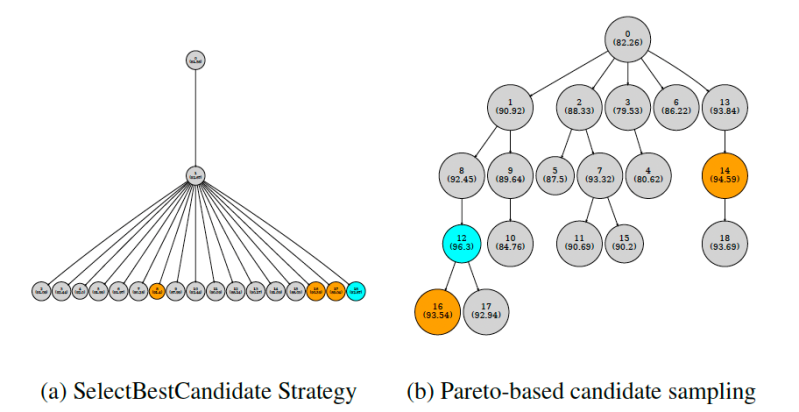
GEPA в действии
Исследователи протестировали GEPA на четырех различных задачах, используя как open-source (Qwen3 8B), так и проприетарные (GPT-4.1 mini) модели. Результаты впечатляют:
- До 19% рост производительности по сравнению с GRPO
- До 35 раз меньше пробных запусков
- 8-кратное сокращение времени разработки
- 15-кратная экономия затрат на GPU
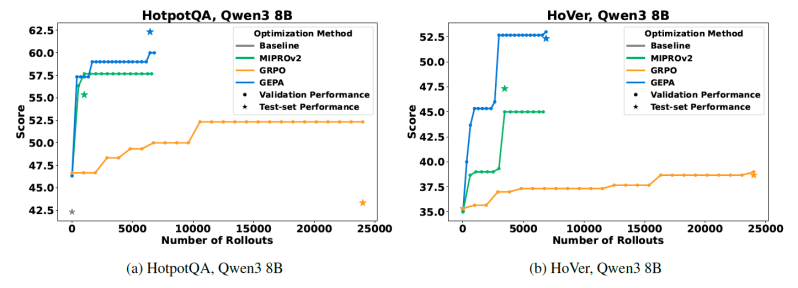
GEPA не просто дешевле — он создает более надежные системы с лучшим обобщением на новых данных. Это именно то, что нужно бизнесу: меньше хрупкости, больше адаптивности в customer-facing приложениях
Дополнительное преимущество — промпты, оптимизированные GEPA, оказываются до 9.2 раз короче, чем у аналогов вроде MIPROv2, что снижает latency и стоимость API-вызовов.





Оставить комментарий