Оглавление
Как сообщает PyTorch, летом 2025 года в DeepSpeed появилось новое расширение ZenFlow — движок оффлоадинга без простоев для обучения больших языковых моделей. Технология решает ключевую проблему традиционных подходов: когда мощные GPU простаивают в ожидании медленных CPU-вычислений и передач данных по PCIe.
Проблема традиционного оффлоадинга
Оффлоадинг стал стандартным подходом для масштабирования тонкой настройки больших языковых моделей за пределы ограничений памяти GPU. Фреймворки вроде ZeRO-Offload уменьшают использование памяти GPU, перенося градиенты и состояния оптимизатора на CPU. Однако они создают новый бутылочное горлышко: дорогие GPU часто простаивают в ожидании медленных CPU-обновлений и передач данных по PCIe.
Источник: pytorch.org
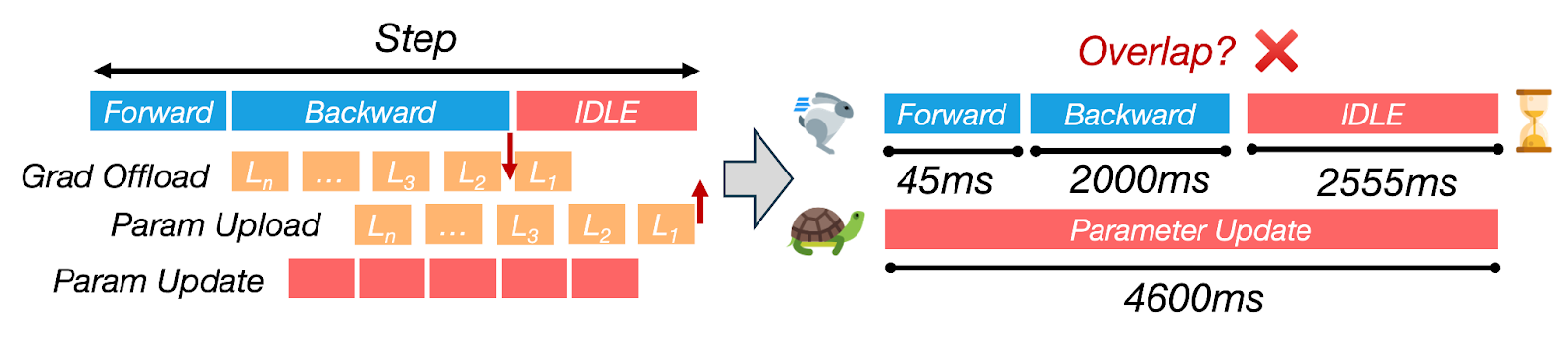
Рисунок 2: ZeRO-Offload вызывает повторяющиеся простои GPU из-за блокирующих CPU-обновлений и передач по PCIe, приводя к >60% времени прохода на шаг при обучении Llama 2-7B на 4× A100.
На практике включение оффлоадинга при обучении Llama 2-7B на 4× A100 GPU может увеличить каждый шаг с 0.5s до более чем 7s — замедление в 14 раз.
Источник: pytorch.org
Рисунок 3: В ZeRO-Offload обновления оптимизатора на стороне CPU и передачи по PCIe доминируют во времени итерации, оставляя GPU бездействующим более 5 секунд.
Как работает ZenFlow
ZenFlow решает эту проблему с помощью конвейера обучения без простоев. Он приоритизирует высокоэффективные градиенты для немедленного обновления на GPU, в то время как остальные выгружаются на CPU и применяются асинхронно. Эти отложенные CPU-обновления полностью перекрываются с вычислениями на GPU, устраняя простои и значительно улучшая пропускную способность.
Источник: pytorch.org
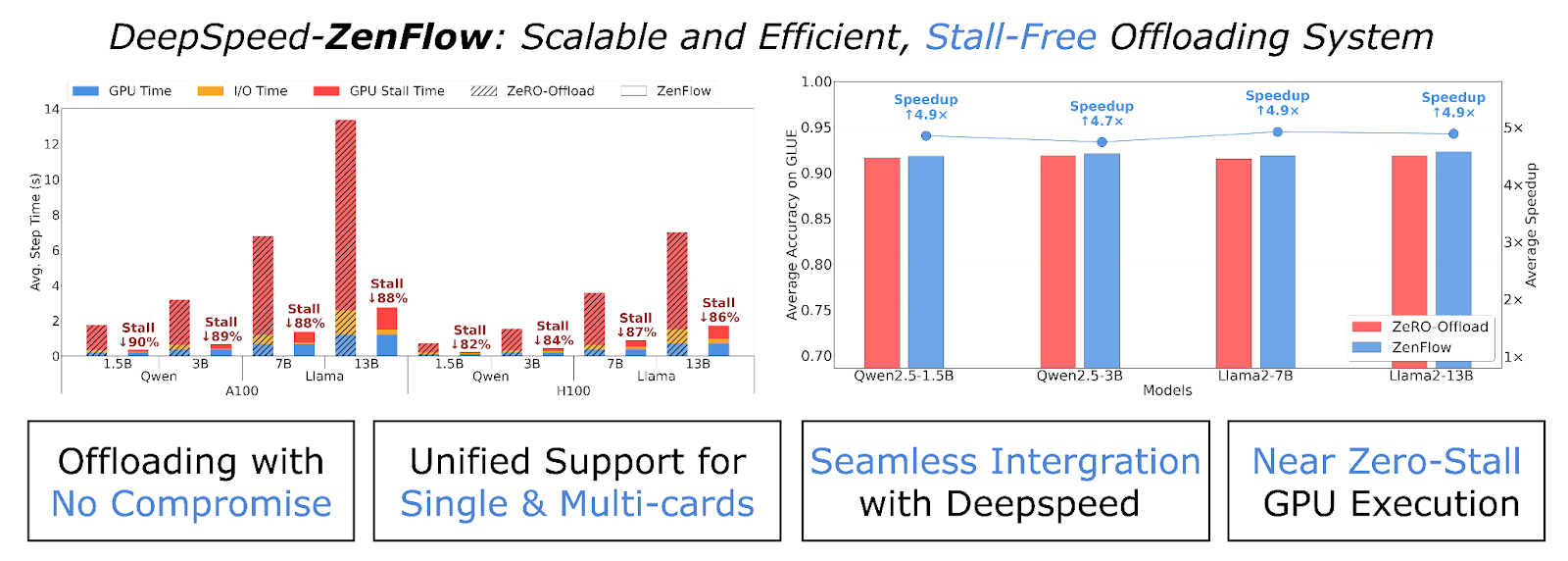
Рисунок 1: ZenFlow — это движок оффлоадинга без простоев DeepSpeed для обучения LLM. Он разъединяет обновления GPU и CPU, prioritizating важные градиенты для немедленного обновления на GPU и откладывая остальные для асинхронного накопления на стороне CPU.
Ключевые особенности ZenFlow
- Нулевые простои GPU: Топ-k важных градиентов обновляются немедленно на GPU; низкоприоритетные градиенты обрабатываются асинхронно на CPU
- Асинхронность с ограниченной устареваемостью: Стратегия сохраняет сходимость при разъединении выполнения CPU и GPU
- Автоматическая настройка: ZenFlow адаптирует интервалы обновления во время выполнения на основе динамики градиентов
Производительность
ZenFlow демонстрирует впечатляющие результаты:
- До 5× ускорения от конца к концу по сравнению с ZeRO-Offload и 6.3× по сравнению с ZeRO-Infinity
- >85% сокращение простоев GPU на узлах A100/H100
- ≈2× меньше трафика PCIe (1.13× размера модели на шаг против 2× в ZeRO)
- Сохраняет или улучшает точность на GLUE (OPT-350M → Llama-13B)
Технически это прорывное решение, которое наконец-то позволяет использовать оффлоадинг без катастрофических потерь производительности. Важность-ориентированный подход к градиентам — это то, что индустрия ждала давно, и реализация в ZenFlow выглядит чрезвычайно грамотной с инженерной точки зрения.
Мотивация проектирования
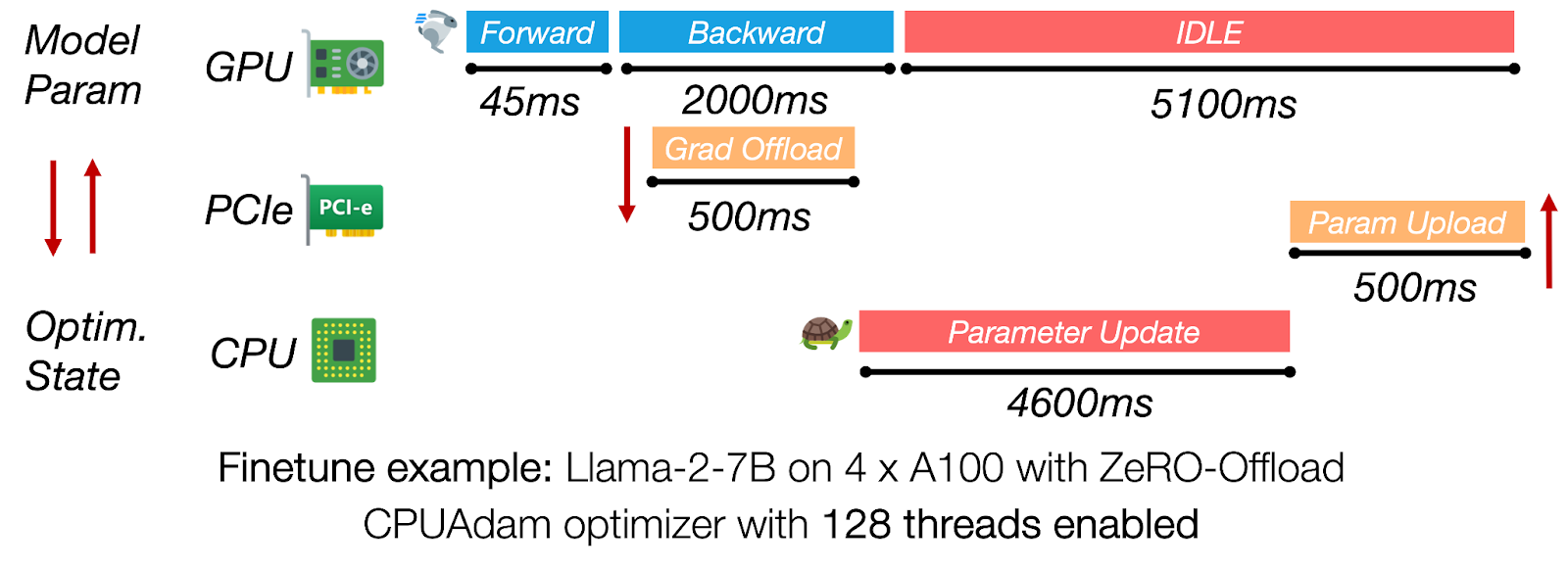
Обучение больших моделей с оффлоадингом может экономить память GPU, но часто ценой производительности. Синхронные фреймворки оффлоадинга оставляют GPU бездействующим, пока CPU выполняет полный шаг оптимизатора и передает обновленные параметры обратно на GPU.
Источник: pytorch.org
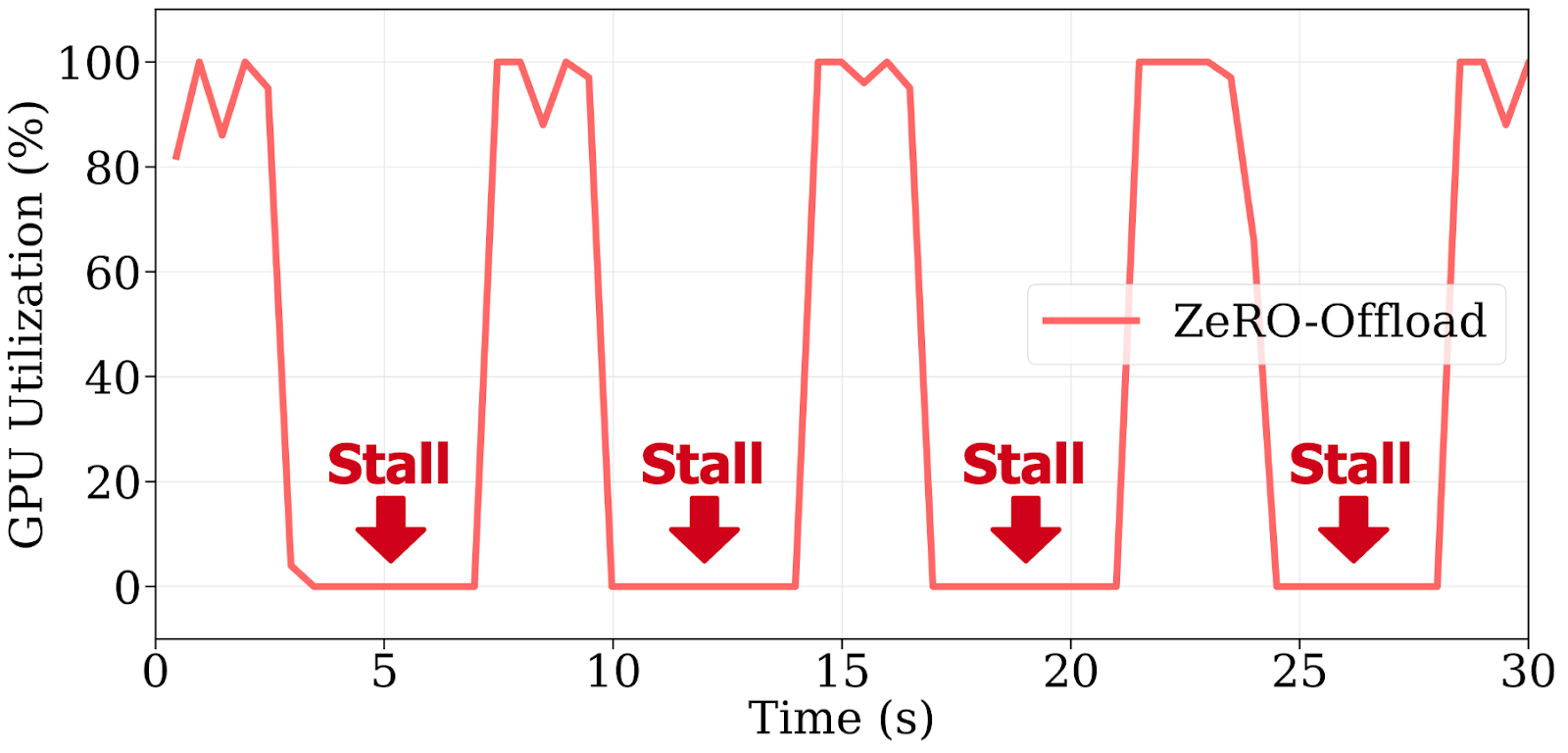
Рисунок 4: Обновления CPU доминируют во времени шага, вызывая >60% простоя GPU из-за плохого перекрытия с вычислениями.
Для Llama-2-7B с 4× A100, путь CPU может занимать более 4s, в то время как обратный проход занимает примерно 2s, поэтому более 60% каждой итерации — это чистое время ожидания GPU.
Источник: pytorch.org
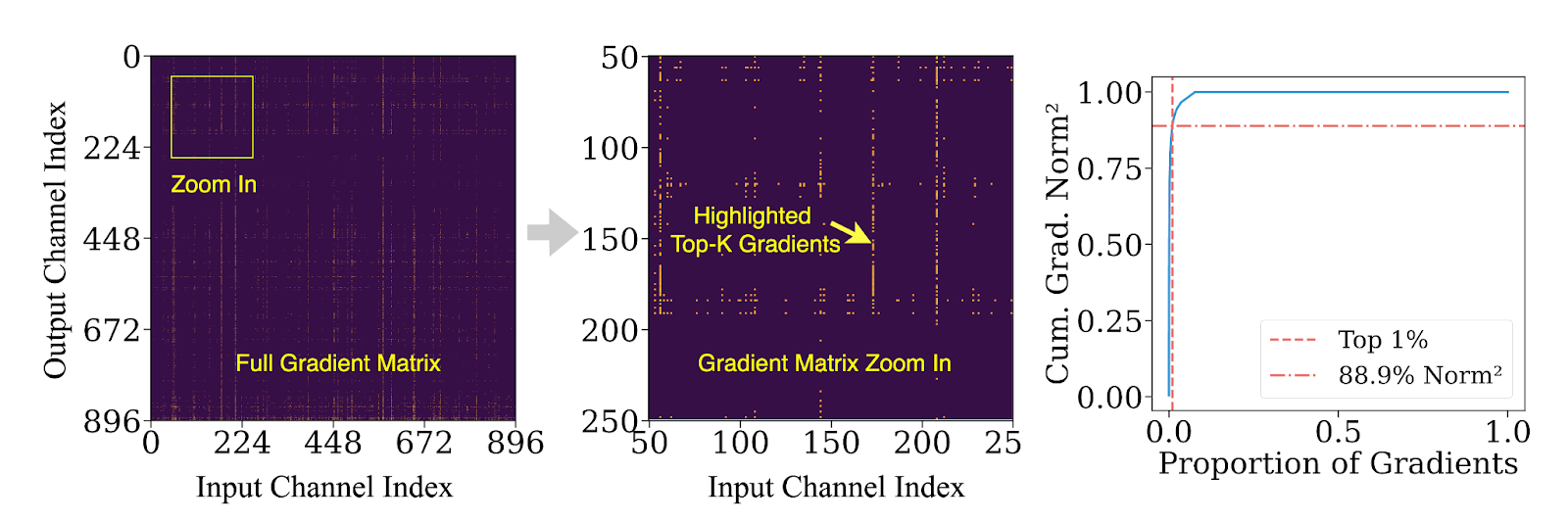
Рисунок 5: Топ 1% градиентов может составлять более 85% норм градиентов.
Архитектурные решения ZenFlow
ZenFlow построен вокруг трех ключевых идей, которые разделяют критические и некритические обновления градиентов при минимизации коммуникационных бутылочных горлышек.
Идея 1: Importance-Aware Top-k Gradient Update
Не все градиенты одинаково влияют на обучение. ZenFlow вводит важность-ориентированный дизайн, который приоритизирует обновления для топ-k наиболее значимых градиентов. Эти градиенты обновляются непосредственно на GPU, используя его высокую пропускную способность вычислений.
Идея 2: Bounded-Asynchronous CPU Accumulation
Асинхронное накопление позволяет CPU оставаться занятым, пока GPU выполняет другие вычисления. Применяется окно накопления для некритических градиентов, позволяя им накапливаться в течение нескольких итераций перед обновлением.
Больше деталей в статье на arXiv.





Оставить комментарий