
Оглавление
Китайская компания DeepSeek представила систему оптического распознавания текста, которая сжимает документы на основе изображений для языковых моделей, позволяя ИИ обрабатывать значительно большие объемы данных без превышения лимитов памяти.
Технология компрессии текста
Основная идея заключается в том, что обработка текста как изображения может требовать меньше вычислительных ресурсов, чем работа с цифровым текстом напрямую. Согласно техническому документу DeepSeek, их OCR способен сжимать текст до десяти раз, сохраняя 97 процентов исходной информации.
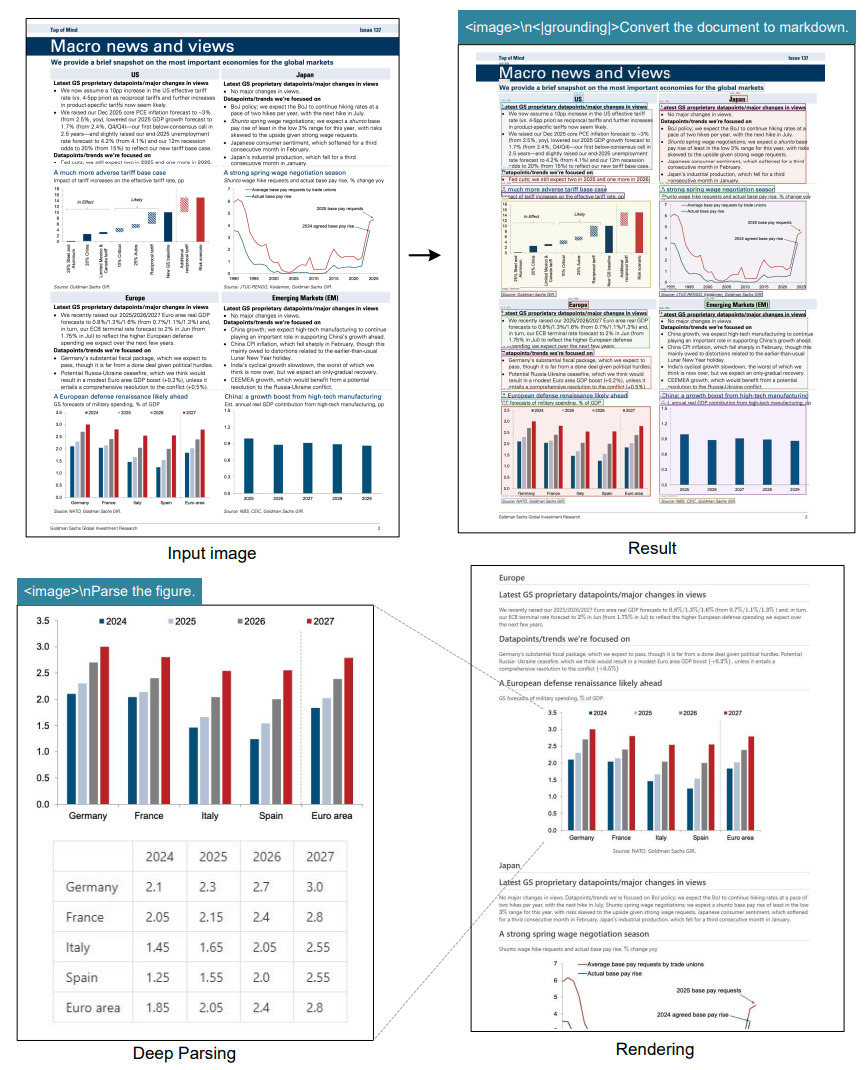
Режим глубокого анализа DeepSeek OCR может преобразовывать финансовые графики в структурированные данные, автоматически генерируя таблицы Markdown и диаграммы.
Система состоит из двух основных компонентов: DeepEncoder для обработки изображений и генератора текста на базе Deepseek3B-MoE с 570 миллионами активных параметров. Сам DeepEncoder использует 380 миллионов параметров для анализа каждого изображения и создания сжатой версии.
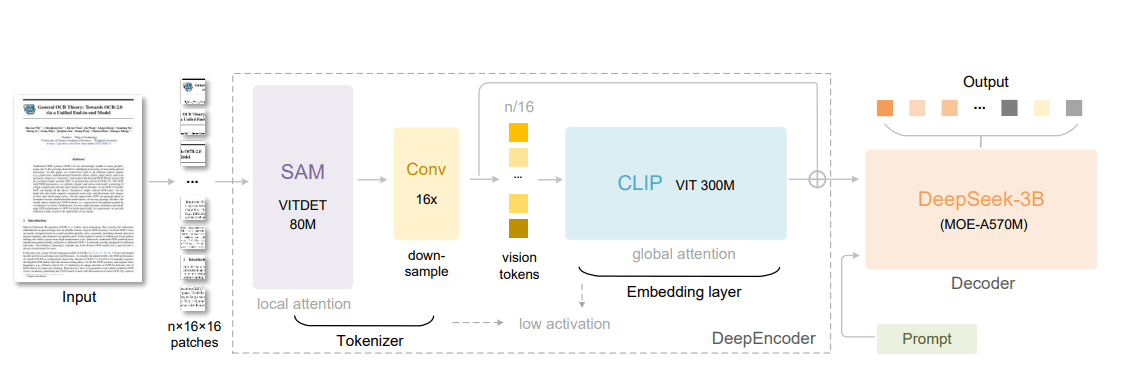
Архитектурные особенности
DeepSeek OCR объединяет локальный анализ изображений от SAM-ViTDet и глобальный контекст от CLIP ViT-300M, используя 16-кратный компрессор токенов перед декодированием распознанного текста в Deepseek 3B-MoE.
DeepEncoder сочетает 80-миллионный SAM (Segment Anything Model) от Meta* для сегментации изображений с 300-миллионным CLIP от OpenAI, который связывает изображения и текст. Между ними находится 16-кратный компрессор, значительно сокращающий количество токенов изображений. Изображение размером 1024×1024 пикселя начинается с 4096 токенов. SAM обрабатывает их, а компрессор сокращает это количество до всего 256 токенов, которые затем передаются ресурсоемкой модели CLIP.
DeepSeek OCR может работать с различными разрешениями изображений. При низких разрешениях требуется всего 64 «визуальных токена» на изображение; при высоких разрешениях — до 400. Для сравнения, традиционные OCR-системы часто требуют тысячи токенов для той же задачи.
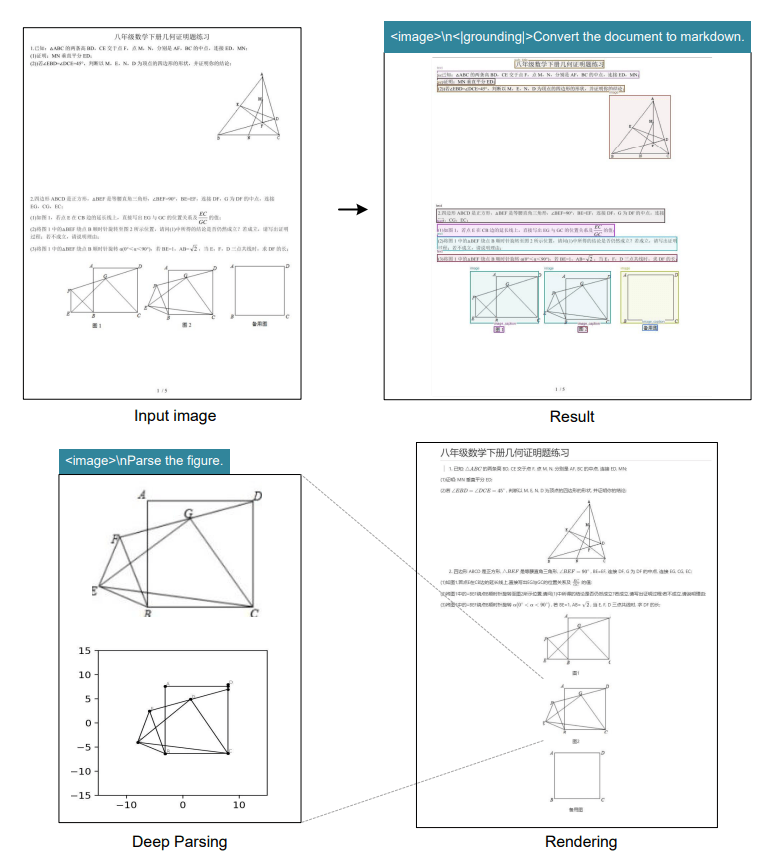
Производительность и тестирование
Даже простые векторные графики остаются сложной задачей для DeepSeek OCR.
В тестах OmniDocBench DeepSeek OCR превзошла GOT-OCR 2.0, используя всего 100 визуальных токенов против 256. С менее чем 800 токенами она также обошла MinerU 2.0, которой требуется более 6000 токенов на страницу.
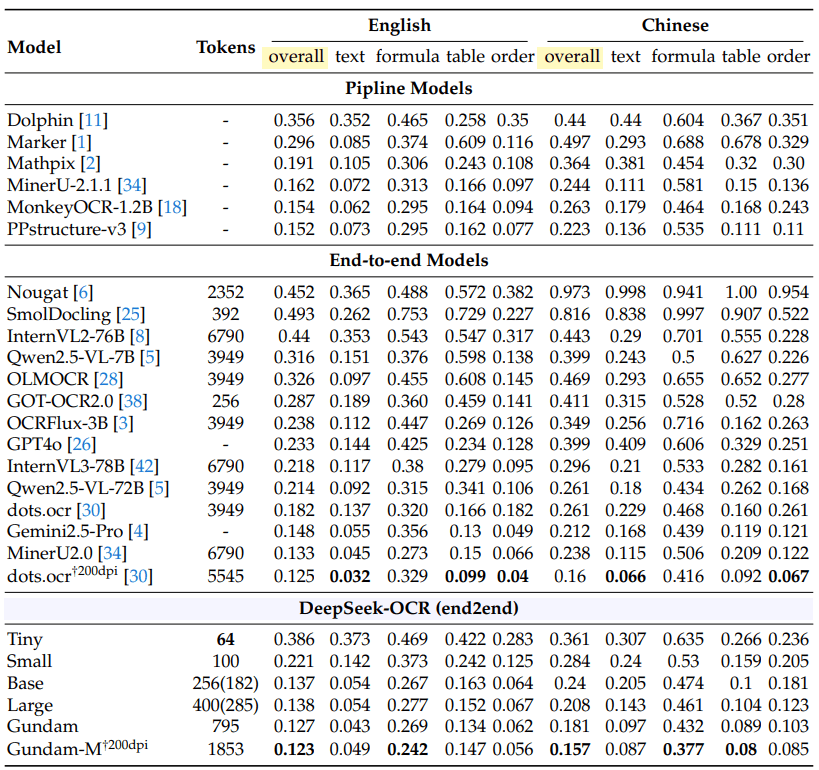
На OmniDocBench DeepSeek OCR соревнуется с dots.ocr от Xiaohongshu и Rednote.
Требования к токенам зависят от документа. Простые презентации используют 64 токена. Книги и отчеты требуют около 100. Сложные газеты нуждаются в «режиме Gundam» DeepSeek с до 800 токенами.
DeepSeek OCR регулирует коэффициенты сжатия и количество токенов с помощью масштабирования, заполнения, а также методов многократного просмотра страниц или скользящего окна для повышения эффективности и точности.
Возможности системы
Система поддерживает широкий спектр типов документов, от простого текста до диаграмм, химических формул и геометрических фигур. Она работает примерно на 100 языках, может сохранять исходное форматирование, выводить обычный текст и при этом предоставлять общие описания изображений.
Для обучения исследователи использовали 30 миллионов страниц PDF примерно на 100 языках, включая 25 миллионов на китайском и английском, а также 10 миллионов синтетических диаграмм, 5 миллионов химических формул и 1 миллион геометрических фигур.
Производительность в реальных условиях
В реальных условиях DeepSeek OCR может обрабатывать более 200 000 страниц в день на одной видеокарте Nvidia A100. С 20 серверами, каждый из которых работает с восемью A100, производительность возрастает до 33 миллионов страниц ежедневно.
Исследователи предлагают использовать DeepSeek OCR для сжатия историй чат-ботов, сохраняя старые обмены сообщениями с более низким разрешением — аналогично тому, как человеческая память ослабевает — чтобы ИИ мог обрабатывать более длинные контексты без резкого увеличения вычислительных затрат.
Такой уровень производительности открывает интересные возможности для создания обучающих наборов данных для других моделей ИИ. Технология особенно важна в контексте растущих требований к контекстным окнам языковых моделей — если раньше 4K токенов казалось прорывом, то сейчас и 128K начинает выглядеть ограничением. Китайские компании демонстрируют, что могут не просто догонять западных конкурентов, но и предлагать оригинальные технические решения для фундаментальных проблем индустрии.
Сообщает The Decoder.
* Meta (признана экстремистской и запрещена в РФ)





Оставить комментарий