
Оглавление
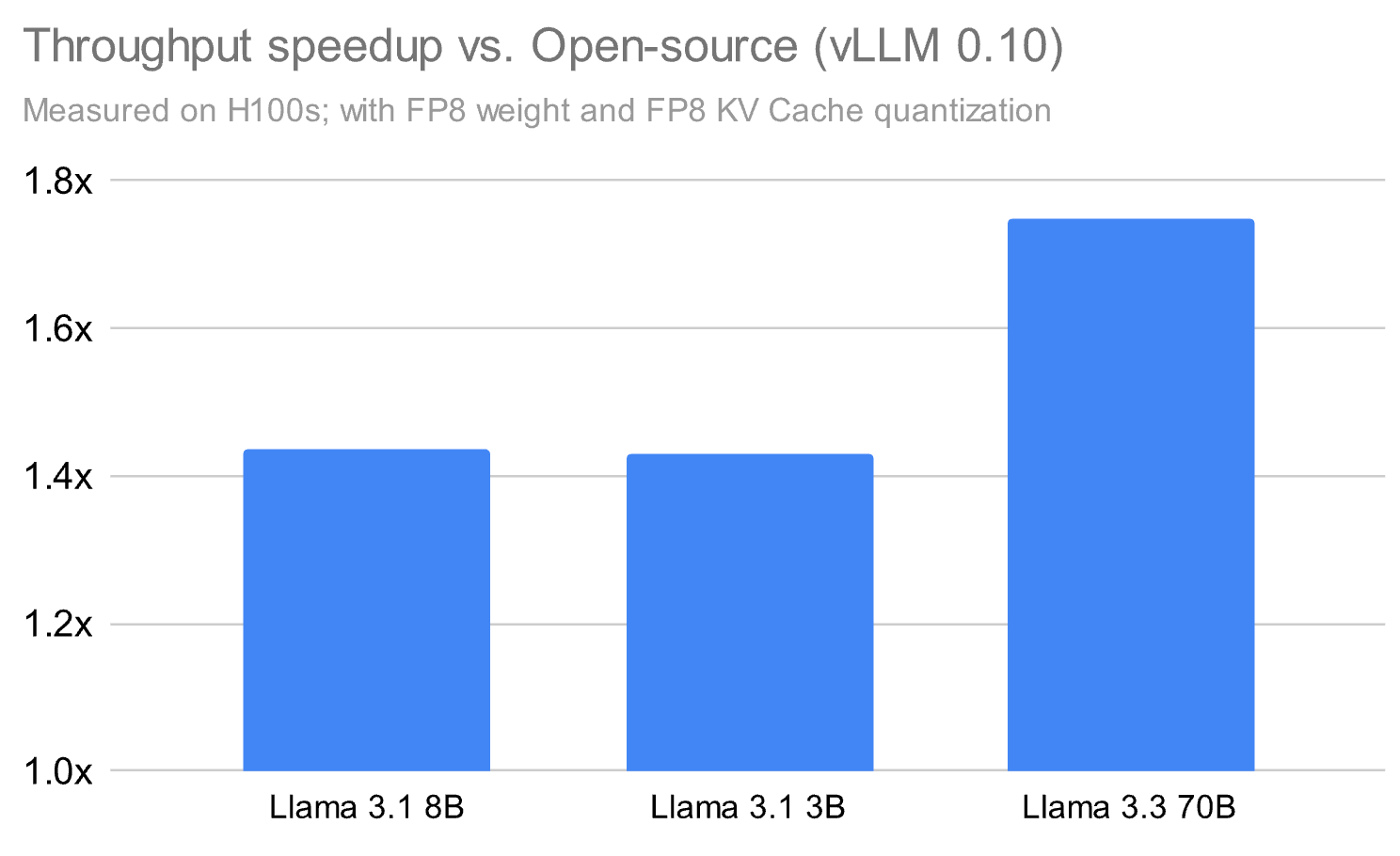
Создание высокопроизводительной системы вывода для машинного обучения — это не просто вопрос скорости, а решение реальных проблем клиентов, работающих с производственными нагрузками. Компания Databricks представила проприетарный движок вывода, который демонстрирует до 1.8x преимущество в производительности по сравнению с открытыми решениями вроде vLLM.
Высокопроизводительная инфраструктура вывода
Продукт Model Serving от Databricks обрабатывает огромные объемы данных как в реальном времени, так и в пакетном режиме. Разработчики компании обнаружили, что для достижения максимальной производительности на рабочих нагрузках клиентов необходимо выходить за рамки существующих open-source решений.
Результаты на Рисунке 1 демонстрируют конкурентное преимущество против vLLM 0.10 на различных сценариях использования — от обслуживания базовых моделей до работы с PEFT. Все сравнения проводились против vLLM с FP8 квантованием весов и кэша на GPU H100.
Помимо самого движка вывода, была создана комплексная инфраструктура обслуживания, решающая задачи масштабируемости, надежности и отказоустойчивости. Это потребовало решения сложных проблем распределенных систем, включая автоматическое масштабирование и балансировку нагрузки, развертывание в нескольких регионах, мониторинг работоспособности, интеллектуальную маршрутизацию запросов и управление состоянием.
Оптимизация для PEFT и LoRA
Среди множества методов параметрически-эффективной тонкой настройки (PEFT) LoRA стал наиболее популярным подходом благодаря балансу между сохранением качества и вычислительной эффективностью. Недавние исследования, включая «LoRA Without Regret» и собственную работу Databricks «LoRA learns less, forgets less», подтвердили ключевые принципы эффективного использования LoRA: применение ко всем слоям (особенно MLP/MoE) и обеспечение достаточной емкости адаптеров.
Однако достижение хорошей вычислительной эффективности при выводе требует значительно большего, чем простое следование этим принципам. Теоретические преимущества LoRA в FLOP не всегда переводятся в реальные выигрыши производительности из-за многочисленных накладных расходов во время вывода.
Существует компромисс между рангом LoRA, который влияет на качество финальной модели, и производительностью вывода. Эксперименты показали, что для большинства клиентов необходим более высокий ранг 32, чтобы не ухудшать качество модели во время обучения. Но это создает дополнительную нагрузку на систему вывода.
Интересно наблюдать, как крупные вендоры переходят от простого использования open-source решений к созданию собственных оптимизированных систем. Это говорит о том, что рынок корпоративного ИИ созрел до уровня, где производительность на реальных рабочих нагрузках становится критически важной, и стандартные решения уже не справляются. Особенно впечатляет акцент на сохранении качества модели при использовании квантования — многие команды жертвуют точностью ради скорости, но Databricks демонстрирует, что можно иметь и то, и другое.
Ключевые принципы оптимизации
Разработчики Databricks сформулировали несколько ключевых принципов, которые легли в основу их работы:
- Фреймворк прежде ядер: Самые эффективные оптимизации возникают при рассмотрении всей системы — понимании взаимодействия планирования, памяти и квантования на всех уровнях стека.
- Квантование должно сохранять качество модели: Использование FP8 может обеспечить значительное ускорение, но только в сочетании с гибридными форматами и объединенными ядрами, сохраняющими точность.
- Перекрытие как множитель пропускной способности: Максимальное использование GPU является ключом к максимальной пропускной способности.
- Накладные расходы CPU часто становятся скрытым узким местом: Особенно для небольших моделей производительность вывода все чаще ограничивается скоростью подготовки и отправки работы на GPU.
Реальные результаты
За последний год команда разработала движок вывода для решения этих проблем и, как показано на Рисунке 1, достигла до 1.5x ускорения при обслуживании LoRA в реалистичных условиях по сравнению с open-source решениями. Например, в тестах с моделью Meta Llama 3.1 8B с использованием распределения Zipf для адаптеров LoRA со средним количеством 4 адаптера.
Движок вывода Databricks демонстрирует до 1.5x более высокую пропускную способность, чем популярные open-source альтернативы, как для рабочих нагрузок с преобладанием предварительного заполнения, так и для декодирования. Разрыв в производительности сокращается, но остается существенным при более высоких нагрузках.
Для достижения этих улучшений команда сфокусировалась на нескольких компонентах: максимизации производительности с сохранением качества модели на ключевых тестах, разделении ресурсов GPU как между, так и внутри мультипроцессоров для лучшей обработки небольших матричных умножений в GEMM, и оптимизации перекрытия выполнения ядер для минимизации узких мест в системе.
По материалам Databricks.





Оставить комментарий