
Оглавление
Традиционные системы поиска документов превратились в сложные многоступенчатые конвейеры, требующие распознавания текста, анализа структуры и семантического кодирования. ColPali предлагает радикальное упрощение — использовать прямое изображение страницы документа как основу для поиска, обходя большинство промежуточных шагов.
Проблемы традиционного подхода
Стандартный пайплайн поиска по PDF-документам включает до семи последовательных этапов:
- Распознавание текста (OCR) для сканированных PDF
- Детектирование структуры документа для сегментации на абзацы, изображения, заголовки
- Восстановление порядка чтения страницы
- Генерация описаний для таблиц и изображений специализированными моделями
- Стратегии разбиения текста на логические фрагменты
- Векторизация текстовых фрагментов с помощью нейросетевых эмбеддингов
- Создание векторного индекса для будущего поиска
Хотя существуют инструменты для автоматизации этого процесса, такие как Unstructured и Surya, вся цепочка остается медленной, подверженной накоплению ошибок и плохо учитывает визуальные элементы страницы.
Архитектура ColPali
Идея ColPali кажется простой: использовать изображения страниц документов напрямую.
Однако техническая реализация требует современных достижений в области Vision Language Models, в частности модели PaliGemma от команды Google Zürich, и механизмов многомерного поиска через late interaction, предложенных в ColBERT Омаром Хаттабом.
Системы поиска обычно делятся на две фазы: индексация документов в офлайн-режиме и поиск по запросу с низкой задержкой. Ключевые требования — высокая производительность поиска, разумная скорость индексации и низкая задержка при запросах.
В отличие от стандартных би-энкодеров, ColPali работает иначе. При индексации Vision LLM (PaliGemma-3B) кодирует изображение, разбивая его на патчи, которые передаются в vision transformer (SigLIP-So400m). Эти эмбеддинги патчей проецируются и подаются как «мягкие» токены в языковую модель (Gemma 2B), чтобы получить контекстуализированные эмбеддинги патчей в пространстве языковой модели.
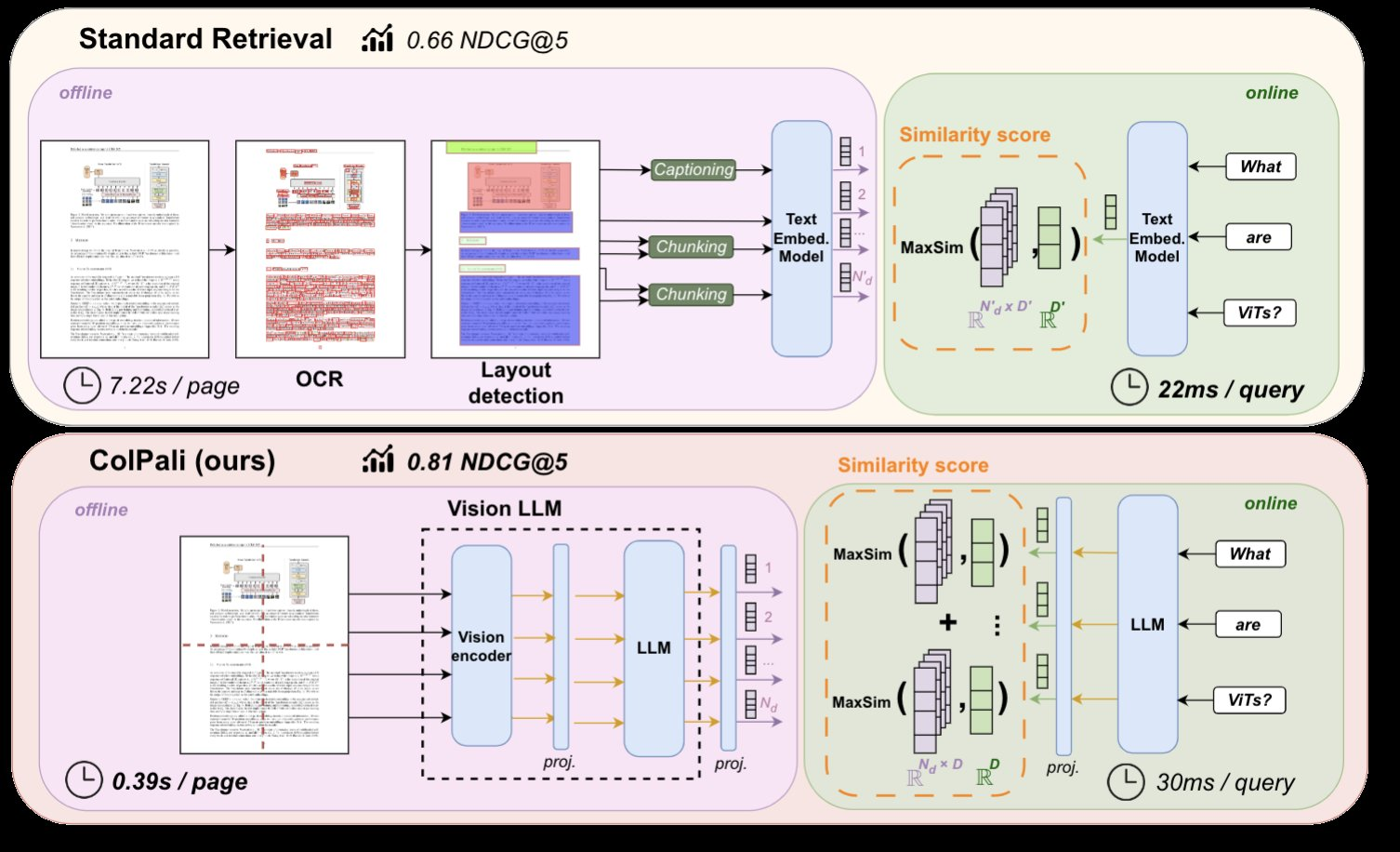
При поиске запрос пользователя эмбеддируется языковой моделью для получения токен-эмбеддингов. Затем выполняется операция «позднего взаимодействия» в стиле ColBERT для эффективного сопоставления токенов запроса с патчами документа. Это позволяет богатому взаимодействию между всеми терминами запроса и патчами документа при сохранении быстрого сопоставления.
Подход ColPali напоминает ситуацию, когда вместо того чтобы описывать картину словами, вы просто показываете её целиком. Элегантное решение, которое обходит множество проблем традиционных пайплайнов, хотя и ставит новые вопросы о масштабируемости и вычислительных затратах на обработку изображений.
Бенчмарк ViDoRe
Хотя существуют отличные бенчмарки для оценки текстовых эмбеддингов, в практических сценариях качество подготовки документов часто важнее самой модели эмбеддингов. Документы часто полагаются на визуальные элементы для эффективной передачи информации, но текстовые системы почти не используют эти визуальные подсказки.
Для решения этой проблемы создан ViDoRe — Visual Document Retrieval Benchmark, оценивающий системы поиска по их способности находить визуально богатую информацию в документах. Бенчмарк охватывает различные темы, модальности (графики, таблицы, текст) и языки.
ViDoRe связан с лидербордом Hugging Face и призван стимулировать развитие парадигмы «поиска в визуальном пространстве».
Результаты и обучение
Модель инициализируется предобученными весами PaliGemma с случайной инициализацией финального проекционного слоя. Для облегчения обучения добавлены low-rank адаптеры для весов внимания языковой модели и линейных проекционных слоев.
Обучающая выборка состоит из примерно 100 тысяч пар (запрос, изображение документа), собранных из двух источников: перепрофилированных датасетов визуального ответа на вопросы и синтетически созданных запросов с помощью мощной модели Claude Sonnet Vision.
На ViDoRe ColPali превосходит все другие оцениваемые системы, включая базовые варианты, где для описания всех визуальных элементов используется очень сильная проприетарная Vision-модель (Claude Sonnet).
Разница особенно заметна на более визуально сложных задачах бенчмарка, таких как InfographicVQA, ArxivQA и TabFQuAD, представляющих инфографики, графики и таблицы соответственно. Однако текстоцентричные документы также лучше извлекаются моделью ColPali во всех оцениваемых доменах и языках.
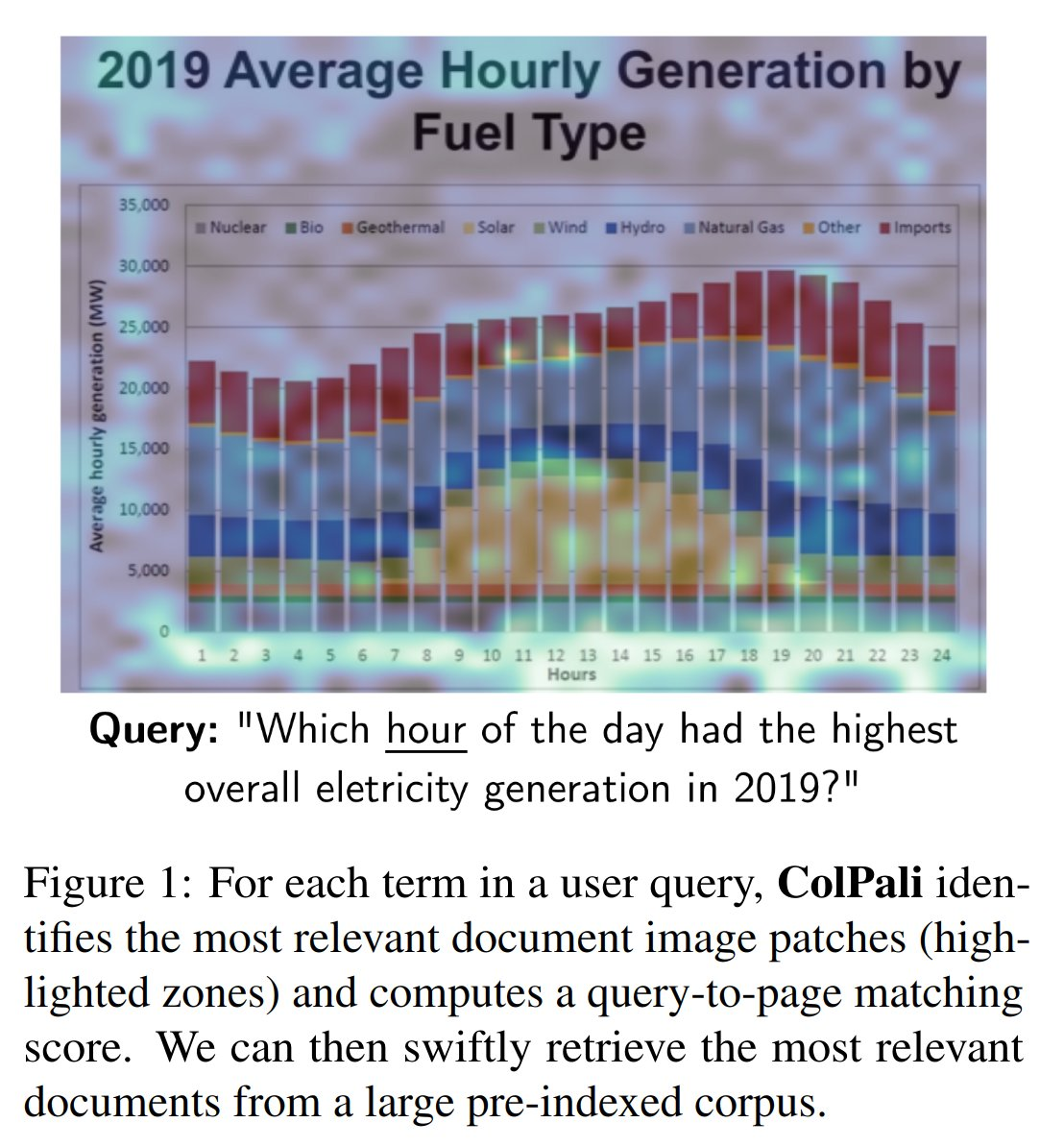
Интерпретируемость
Помимо скорости и производительности, ColPali позволяет визуализировать, какие патчи документа выделяются относительно данного запроса. Например, термин «час» соответствует патчам, содержащим слова типа «почасово», но также и оси X, представляющей время, демонстрируя хорошее понимание графиков.
По материалам Hugging Face.





Оставить комментарий