
Оглавление
Компания Black Forest Labs представила FLUX.2 — следующее поколение своей модели генерации изображений с полностью новой архитектурой и обучением с нуля. По сравнению с предыдущей версией Flux.1, новая модель предлагает существенные технические улучшения и повышенную эффективность работы.
Ключевые изменения в архитектуре
FLUX.2 сохраняет общую архитектуру multimodel diffusion transformer (MM-DiT) с параллельными DiT блоками, но вносит несколько важных усовершенствований:
- Используется единый текстовый энкодер Mistral Small 3.1 вместо двух энкодеров в предыдущей версии
- Информация о времени и управлении теперь распределяется между всеми блоками трансформера
- Полностью исключены параметры смещения (bias) во всех слоях модели
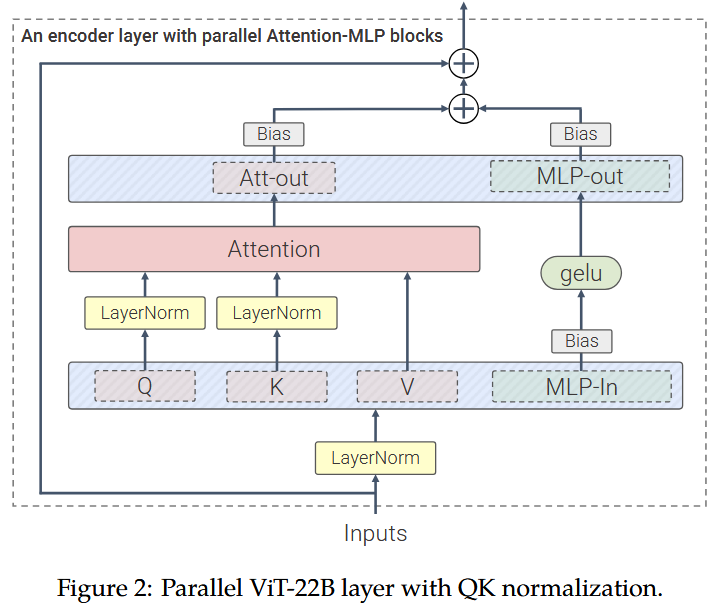
- Внедрена архитектура полностью параллельного трансформер-блока
Одним из наиболее заметных изменений стало перераспределение между двойными и одинарными потоками обработки: FLUX.2 использует 8 двойных блоков против 48 одинарных, тогда как Flux.1 имел соотношение 19/38. Это означает, что теперь основная часть параметров модели (73%) сосредоточена в одинарных блоках.
Требования к ресурсам и оптимизации
Новая модель демонстрирует существенный рост требований к вычислительным ресурсам. Без оптимизации для работы FLUX.2 требуется более 80 ГБ видеопамяти, что делает её недоступной для большинства пользователей без специальных настроек.
Разработчики предлагают несколько способов работы с моделью при ограниченных ресурсах:
Квантование 4-bit
С использованием библиотеки bitsandbytes можно загружать трансформер и текстовый энкодер в 4-битном формате, что снижает требования до ~20 ГБ свободной видеопамяти:
import torch from transformers import Mistral3ForConditionalGeneration from diffusers import Flux2Pipeline, Flux2Transformer2DModel repo_id = "diffusers/FLUX.2-dev-bnb-4bit" device = "cuda:0" torch_dtype = torch.bfloat16 transformer = Flux2Transformer2DModel.from_pretrained( repo_id, subfolder="transformer", torch_dtype=torch_dtype, device_map="cpu" ) text_encoder = Mistral3ForConditionalGeneration.from_pretrained( repo_id, subfolder="text_encoder", dtype=torch_dtype, device_map="cpu" ) pipe = Flux2Pipeline.from_pretrained( repo_id, transformer=transformer, text_encoder=text_encoder, torch_dtype=torch_dtype ) pipe.enable_model_cpu_offload()
Использование Flash Attention 3
Владельцы GPU серии Hopper могут воспользоваться Flash Attention 3 для ускорения инференса:
from diffusers import Flux2Pipeline
import torch
repo_id = "black-forest-labs/FLUX.2-dev"
pipe = Flux2Pipeline.from_pretrained(path, torch_dtype=torch.bfloat16)
pipe.transformer.set_attention_backend("_flash_3_hub")
pipe.enable_model_cpu_offload()
Модульный подход к развертыванию
Благодаря модульной архитектуре Diffusers, пользователи могут изолировать текстовый энкодер и развернуть его на Inference Endpoint, что значительно снижает требования к локальным ресурсам для работы с DiT и VAE компонентами.
При всей технической элегантности архитектурных изменений, требование 80+ ГБ видеопамяти для базового инференса выглядит как шаг назад в доступности технологий генеративного ИИ. В то время как остальной рынок движется к оптимизации и снижению барьеров входа, FLUX.2 устанавливает новые рекорды ресурсоемкости. Интересно, станет ли это новым трендом «чем больше — тем лучше» или же разработчики вскоре предложат более эффективные компактные версии для массового использования.
FLUX.2 поддерживает как текстовую генерацию изображений, так и генерацию по изображению-образцу, а также возможность использования нескольких референсных изображений одновременно. Модель доступна через библиотеку Diffusers после установки из основной ветки и авторизации в Hugging Face.
Доступ через Workers AI
Также модель доступна на платформе Workers AI от Cloudflare. Технически FLUX.2 в Workers AI использует формат multipart form data для поддержки до четырех входных изображений размером 512×512 пикселей и генерации выходных изображений до 4 мегапикселей.
В коде Workers AI поддерживает multi-reference изображения (до 4) через multipart form-data:
curl --request POST \
--url 'https://api.cloudflare.com/client/v4/accounts/{ACCOUNT}/ai/run/@cf/black-forest-labs/flux-2-dev' \
--header 'Authorization: Bearer {TOKEN}' \
--header 'Content-Type: multipart/form-data' \
--form 'prompt=take the subject of image 2 and style it like image 1' \
--form input_image_0=@/Users/johndoe/Desktop/icedoutkeanu.png \
--form input_image_1=@/Users/johndoe/Desktop/me.png \
--form steps=25
--form width=1024
--form height=1024
Доступ через Together AI
Также новая модель уже доступна на платформе Together AI. Стандартный Python SDK Together AI, те же паттерны, что и для генерации текста:
from together import Together client = Together() response = client.images.generate( model="black-forest-labs/FLUX.2-pro", prompt="A mountain landscape at sunset with golden light reflecting on a calm lake", width=1024, height=768, ) print(response.data[0].url)
Выбирайте модель, подходящую под ваш workflow: Dev для экспериментов, Pro для продакшен-скорости, Flex для контента с большим количеством текста.
По материалам Hugging Face, Cloudflare и Together.





Оставить комментарий