
Оглавление
Как пишет Google Cloud Blog, BigQuery ML получил значительное расширение функционала для работы с текстовыми эмбеддингами. Теперь платформа поддерживает не только собственные модели text-embedding-004/005 и text-multilingual-embedding-002, но и флагманскую Gemini embedding model, а также более 13 тысяч открытых моделей из экосистемы Hugging Face.
Выбор модели под конкретные задачи
Новые возможности предоставляют разработчикам гибкость в выборе между качеством, стоимостью и масштабируемостью. Gemini embedding model демонстрирует самое современное качество и лидирует в Massive Text Embedding Benchmark, но требует более высоких затрат. Модели с открытым исходным кодом предлагают широкий спектр вариантов — от топовых решений вроде Qwen3-Embedding до компактных и экономичных multilingual-e5-small.
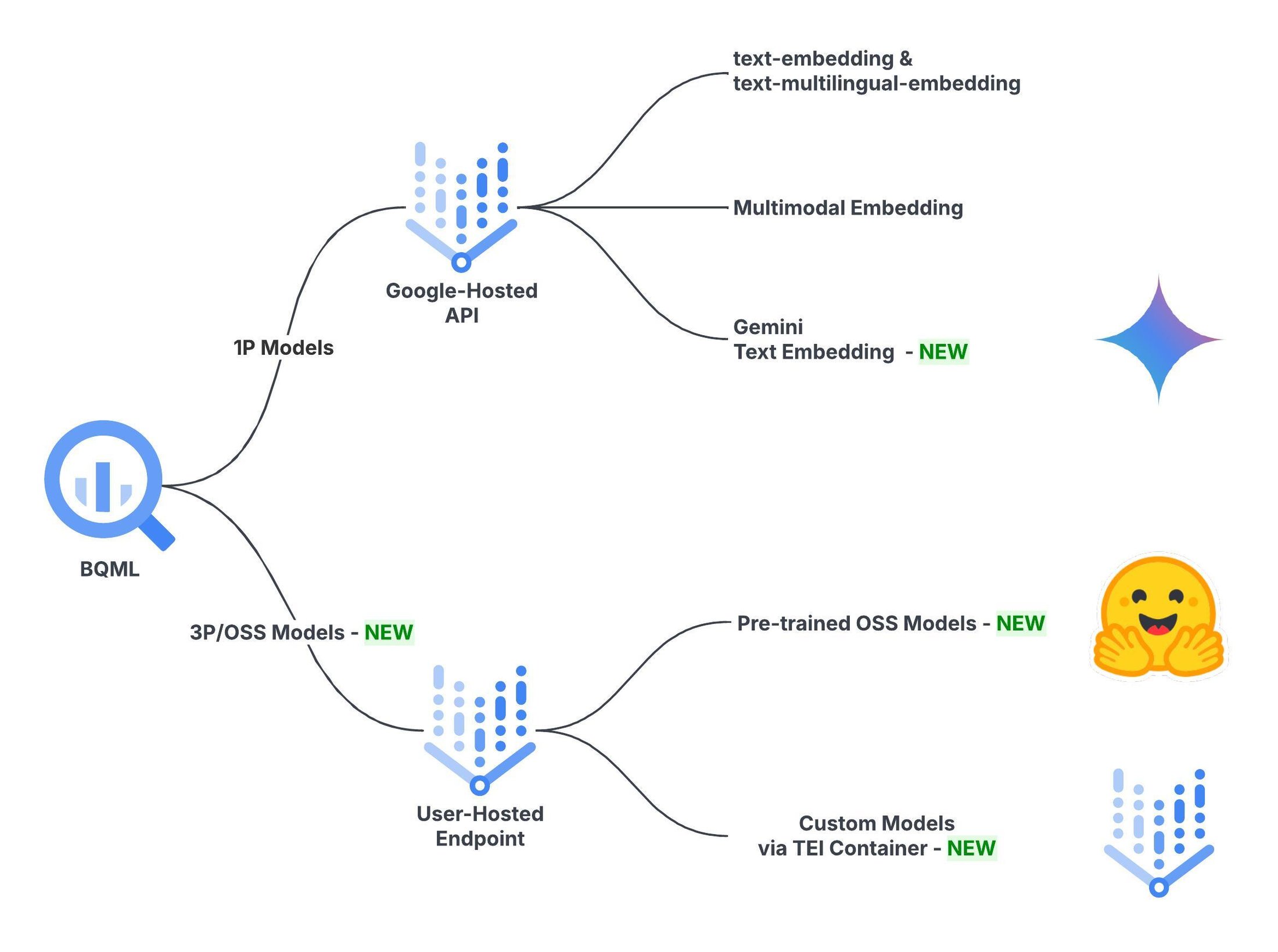
Ключевые характеристики различных категорий моделей:
- text-embedding-005 & multilingual-embedding-002: очень высокое качество, умеренная стоимость, масштабируемость до 100 млн строк за 6 часов
- Gemini Text Embedding: самое современное качество, высокая стоимость, масштабируемость до 10 млн строк за 6 часов
- OSS модели: широкий диапазон качества, стоимость зависит от размера модели, максимальная масштабируемость при резервировании дополнительных машин
Практическое использование Gemini в BigQuery
Для работы с Gemini embedding model достаточно выполнить несколько SQL-команд:
CREATE OR REPLACE MODEL bqml_tutorial.gemini_embedding_model REMOTE WITH CONNECTION DEFAULT OPTIONS(endpoint='gemini-embedding-001');
Генерация эмбеддингов для датасета:
SELECT * FROM ML.GENERATE_EMBEDDING( MODEL bqml_tutorial.gemini_embedding_model, ( SELECT text AS content FROM bigquery-public-data.hacker_news.full WHERE text IS NOT NULL LIMIT 10000 ) );
Важной особенностью является новая система квот на основе Tokens Per Minute (TPM) с лимитом до 20 миллионов токенов без ручного одобрения.
Работа с открытыми моделями
Интеграция с Hugging Face открывает доступ к тысячам моделей. Процесс включает развертывание модели на Vertex AI endpoint и последующее использование через BigQuery ML:
- Выбор модели на Hugging Face и деплой через Vertex AI Model Garden
- Создание удаленной модели в BigQuery
- Генерация эмбеддингов SQL-запросами
- Обязательное удаление endpoint после завершения работы для избежания лишних затрат
Производительность впечатляет: даже с одной репликой модели multilingual-e5-small обработка 38 миллионов строк датасета hacker_news занимает около 2 часов 10 минут. Масштабирование до 10 реплик позволяет обрабатывать миллиарды строк за шестичасовое окно выполнения запроса.
Расширение BigQuery ML — это важный шаг для экосистемы Google Cloud. Теперь разработчики могут открыть инструмент для каждой задачи, не выходя из привычной SQL-среды. Особенно ценно то, что можно работать как с топовыми коммерческими моделями вроде Gemini, так и с нишевыми решениями с открытым исходным кодом. Главное — не забыть о возникновении: конечные точки в Vertex AI тарифицируются поминутно, поэтому пакетную обработку необходимо построить как непрерывный рабочий процесс с обязательным отменой развертывания после завершения работы.
Новые возможности BigQuery ML существенно упрощают построение семантического поиска, классификации и RAG-систем, позволяя генерировать эмбеддинги прямо там, где хранятся данные, без сложных ETL-процессов и интеграций.





Оставить комментарий