Оглавление
Пока мультимодальные модели вроде Gemini 2.5 Pro и GPT-4o пытаются стать универсальными решениями для всех задач компьютерного зрения, PP-OCRv5 от Baidu демонстрирует мощь специализированного подхода. Эта оптимизированная система оптического распознавания текста обходит крупные VLMs в точности определения границ текста и эффективности работы на CPU.
Преимущества специализированной архитектуры
В отличие от сквозных моделей, которые могут «галлюцинировать» и генерировать текст, отсутствующий в исходном изображении, PP-OCRv5 использует классический двухэтапный конвейер: сначала детектирование текста, затем распознавание. Такой подход обеспечивает предсказуемость и точность координат ограничивающей рамки — критически важную функцию для задач структурированного извлечения данных.
Ключевые характеристики модели:
- Эффективность: Всего 0.07 миллиарда параметров и скорость обработки свыше 370 символов в секунду на Intel Xeon Gold 6271C
- Многоязычная поддержка: Распознавание 40+ языков с акцентом на китайский, английский, японский и пиньинь
- Точная локализация: Четкое определение границ текстовых блоков даже в плотных документах
- Производительность: Превышает результаты Gemini 2.5 Pro, Qwen2.5-VL и GPT-4o в специализированных OCR-бенчмарках
Результаты тестирования
В бенчмарке OmniDocBench PP-OCRv5 показала наивысший средний балл по расстоянию в 1 правку для различных типов текста, включая рукописный и печатный китайский и английский.
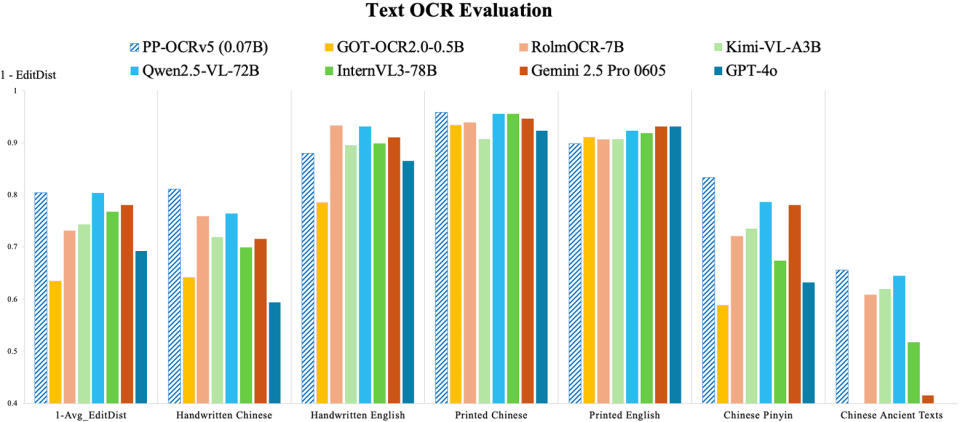
Интересно наблюдать, как «старый добрый» модульный подход с четким разделением детекции и распознавания оказывается эффективнее монолитных VLMs в специфических задачах. Пока все восхищаются размером моделей, PP-OCRv5 демонстрирует, что иногда лучше сделать одну вещь, но сделать ее идеально — особенно когда речь идет о промышленном применении, где важны предсказуемость и точность координат.
Архитектурные особенности
Модель состоит из четырех последовательных компонентов:
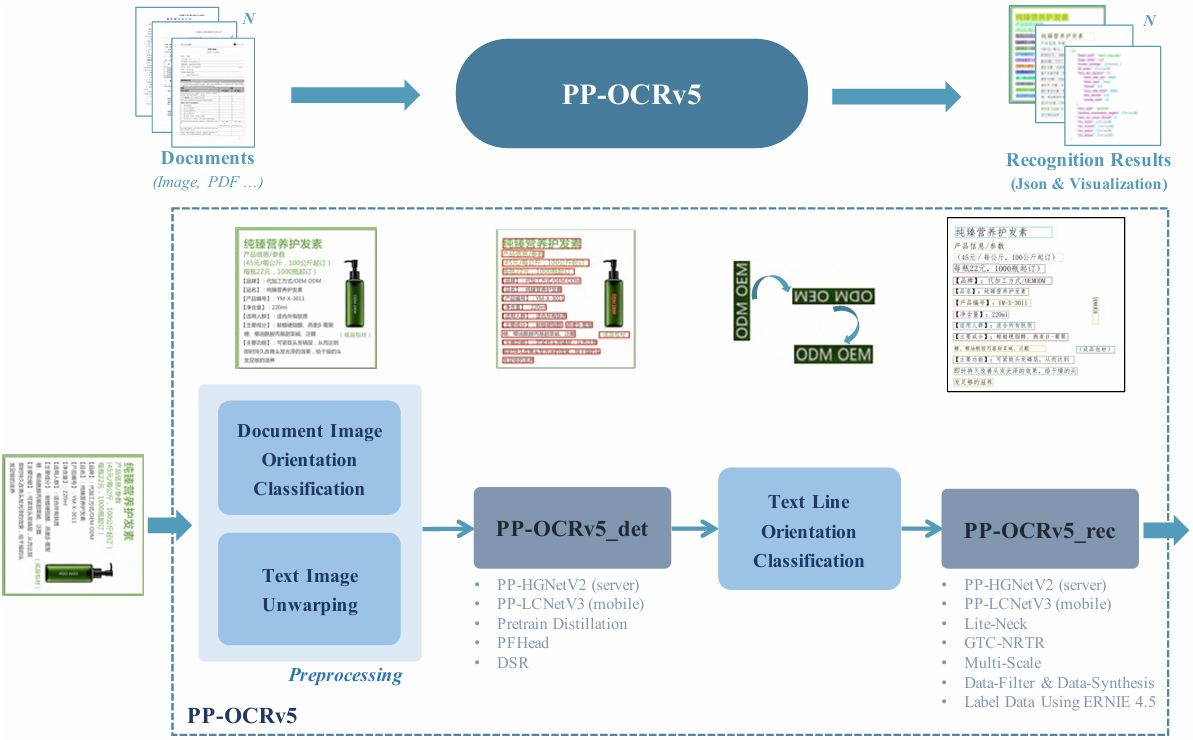
- Предобработка изображения (коррекция искажений и поворотов)
- Детектирование текстовых линий
- Определение ориентации текста
- Непосредственное распознавание символов
Практическое применение
Для тестирования доступен онлайн-демо на Hugging Face Spaces, поддерживающий многоязычные документы, рукописный текст и сканы низкого качества.
Локальная установка требует сначала фреймворк PaddlePaddle, затем библиотеку PaddleOCR:
pip install paddlepaddle==3.0.0 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/ pip install paddleocr
Пример кода для базового использования:
from paddleocr import PaddleOCR
ocr = PaddleOCR(use_doc_orientation_classify=False)
result = ocr.predict(input="sample.png")
for res in result:
res.print()
res.save_to_json("output")
Как сообщает Hugging Face, PP-OCRv5 представляет собой сфокусированное решение для задач, где важны точность локализации текста и эффективность работы на ограниченных ресурсах — в противовес универсальным, но менее предсказуемым мультимодальным моделям.





Оставить комментарий