Оглавление
По сообщению AWS Machine Learning Blog, Amazon SageMaker HyperPod получил радикально упрощенный процесс развертывания кластеров для распределенного обучения и инференса больших моделей. Вместо многоэтапной ручной настройки десятков сервисов теперь достаточно одного клика.
Что изменилось в SageMaker HyperPod
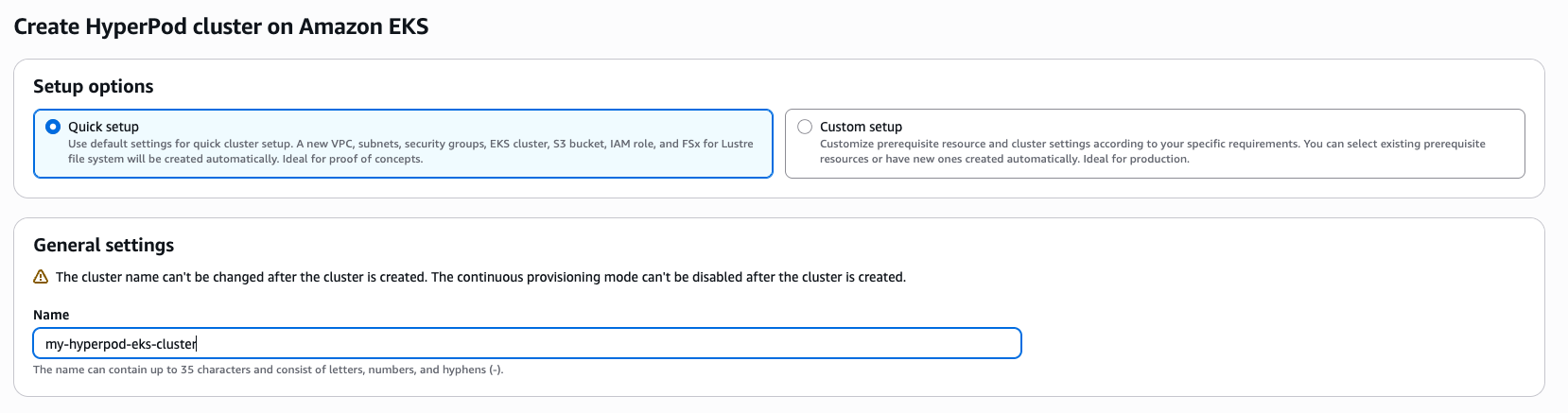
Новый интерфейс создания кластеров предлагает два варианта:
- Быстрая настройка — автоматическое развертывание со стандартными конфигурациями
- Пользовательская настройка — детальный контроль над каждым параметром
Оба варианта используют AWS CloudFormation для декларативного описания инфраструктуры, что обеспечивает воспроизводимость и согласованность между окружениями.
Автоматизация критической инфраструктуры
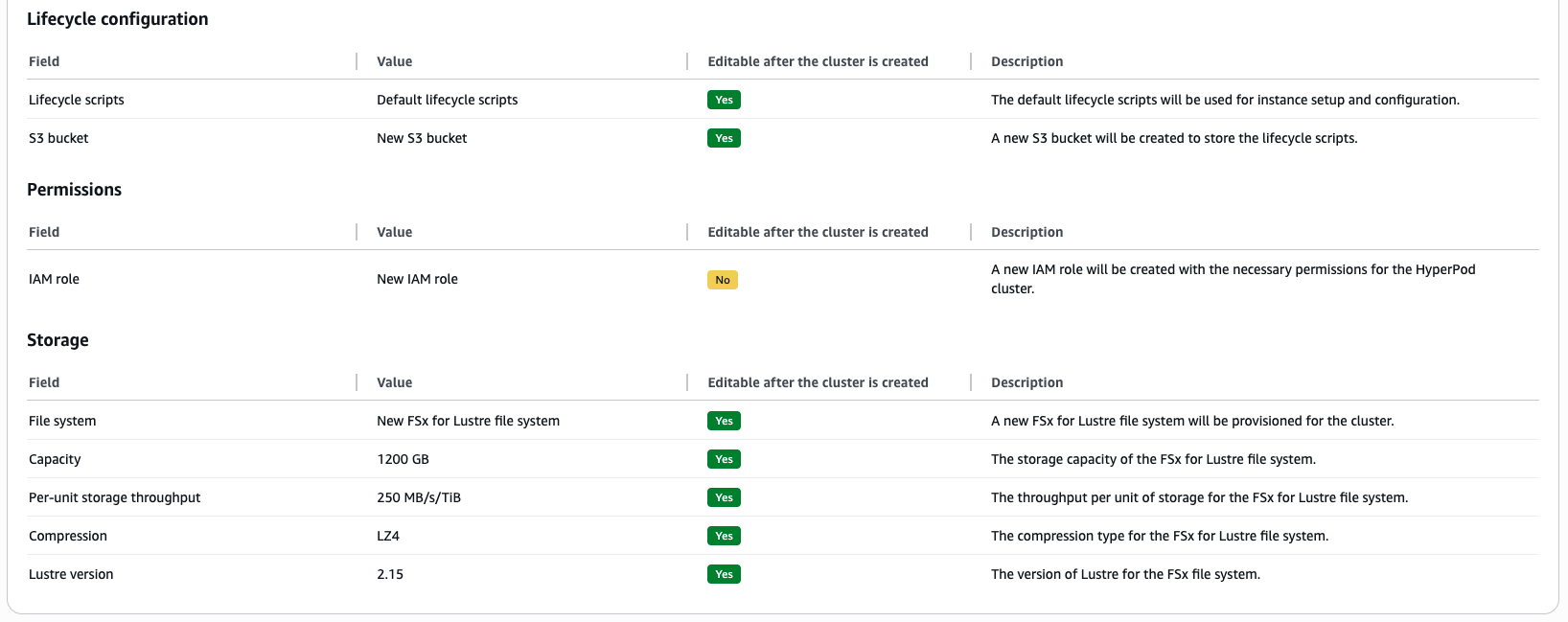
При выборе быстрой настройки система автоматически создает:
- Новую VPC с правильно сегментированными подсетями
- Группы безопасности с предустановленными правилами для EFA и FSx for Lustre
- Полноценный EKS кластер с необходимыми операторами и плагинами
- S3 bucket для скриптов жизненного цикла
- IAM роль с соответствующими правами
- Высокопроизводительную FSx for Lustre файловую систему

Особенно важно решение использовать подсеть /16 по умолчанию — это обеспечивает поддержку более 65,000 приватных IP-адресов, что критично для крупных кластеров с тысячами ускорителей.
Технические детали EKS оркестрации
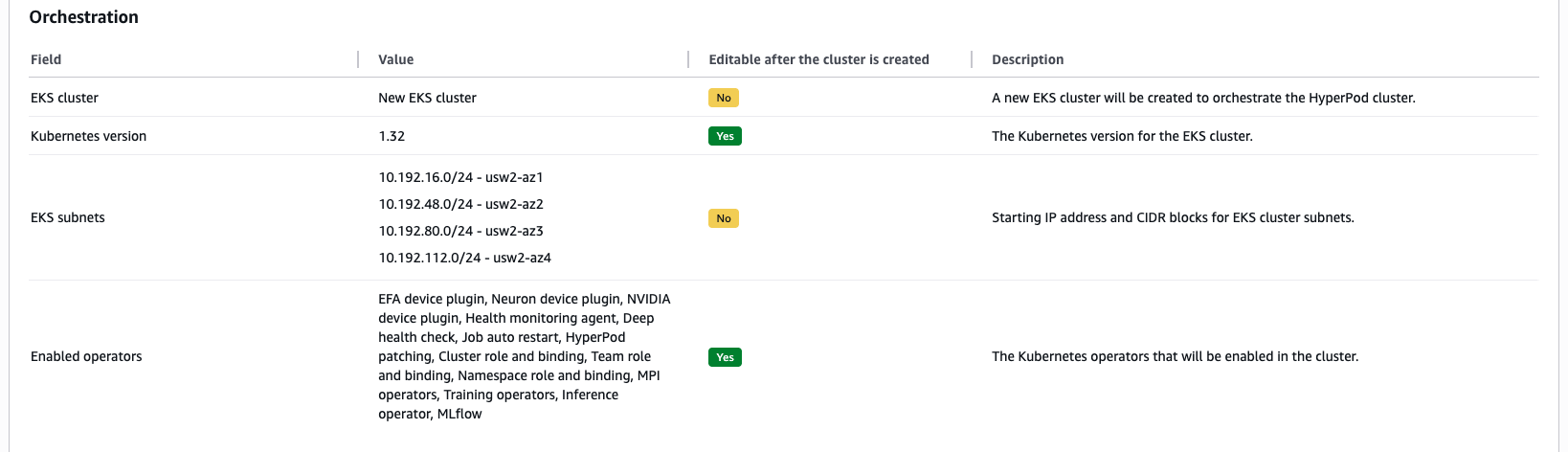
Для оркестрации EKS быстрая настройка включает:
- Последнюю поддерживаемую версию Kubernetes
- Плагины устройств EFA, Neuron и NVIDIA
- Агент здоровья (HMA)
- Обучение операторов Kubeflow
- Оператор вывода SageMaker HyperPod
Автоматизация развертывания ML-инфраструктуры — это тот самый случай, когда действительно стоит говорить о демократизации ИИ. Раньше для настройки подобного кластера требовался опытный DevOps-инженер и несколько дней работы. Теперь — буквально пять минут и один клик. Интересно, сколько компаний из сектора MLops останутся без работы благодаря таким обновлениям.
Пользовательская настройка для продвинутых сценариев
Пользовательская настройка предоставляет полный контроль над конфигурацией, включая возможность отключения автоматического восстановления узлов — полезно для отладки и тестирования специфических сценариев.
Оба варианта значительно сокращают время развертывания готовых к работе кластеров для обучения генеративных AI-моделей, их тонкой настройки и инференса.





Оставить комментарий