
Оглавление
Команда Amazon Search добилась впечатляющих результатов в оптимизации обучения машинных моделей, сообщает AWS Machine Learning Blog. Внедрение AWS Batch для Amazon SageMaker Training jobs позволило увеличить пиковую утилизацию GPU-ускоренных инстансов с 40% до более чем 80%, фактически удвоив производительность ML-обучения.
Вызовы машинного обучения в Amazon Search
В Amazon Search используется сотни GPU-ускоренных инстансов для обучения и оценки ML-моделей, которые помогают покупателям находить нужные товары. Ученые обычно обучают несколько моделей одновременно, чтобы найти оптимальные параметры, архитектуру и гиперпараметры для максимизации производительности моделей.
Ранее команда использовала FIFO-очередь для координации обучения и оценки моделей, но этого оказалось недостаточно. Требовалась более сложная система приоритизации:
- Высокий приоритет — продакшен модели
- Средний приоритет — исследовательские работы
- Низкий приоритет — подбор гиперпараметров и пакетный вывод
Также нужна была система, способная обрабатывать прерывания: если задача падает или определенный тип инстансов перегружен, задача должна автоматически перезапускаться на других совместимых инстансах, сохраняя приоритетность.
Техническое решение
После оценки нескольких вариантов команда выбрала AWS Batch для Amazon SageMaker Training jobs как наиболее подходящее решение. Эта платформа обеспечила бесшовную интеграцию AWS Batch с Amazon SageMaker и позволила запускать задачи согласно критериям приоритизации.
Ключевыми компонентами решения стали:
Сервисные окружения
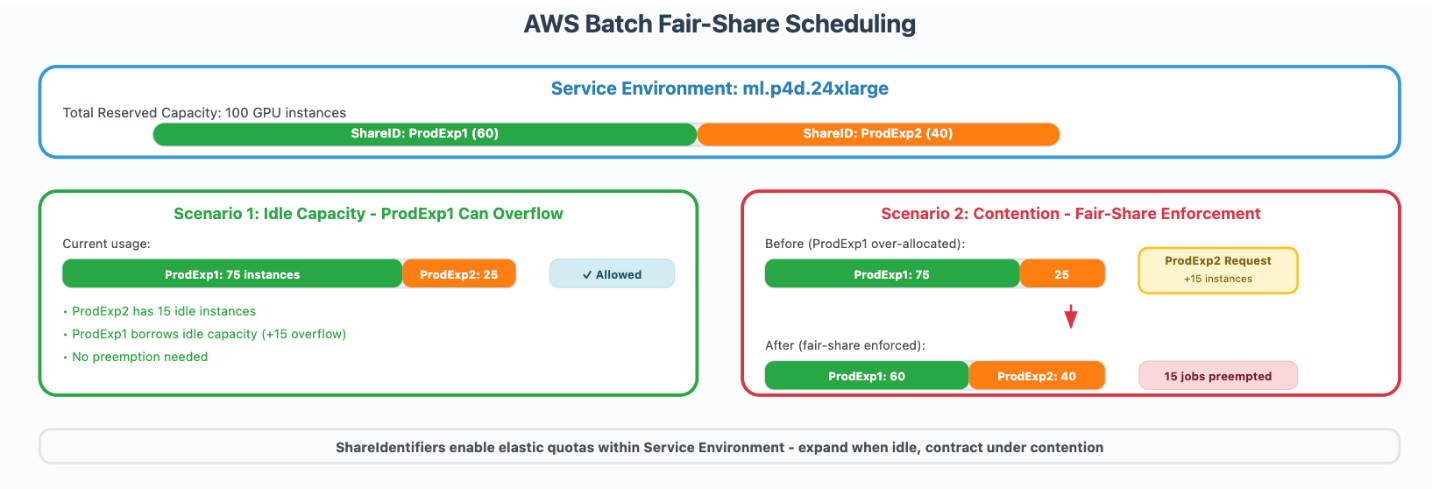
Команда настроила сервисные окружения для представления общей GPU-емкости доступной для каждого семейства инстансов, таких как P5 и P4. Каждое окружение было сконфигурировано с фиксированными лимитами, основанными на зарезервированной командой емкости в AWS Batch.
Идентификаторы долей
Идентификаторы долей использовались для распределения долей емкости сервисного окружения между продакшен-экспериментами. Эти строковые теги применялись при отправке задач, и AWS Batch использовал их для отслеживания использования и обеспечения справедливого планирования.
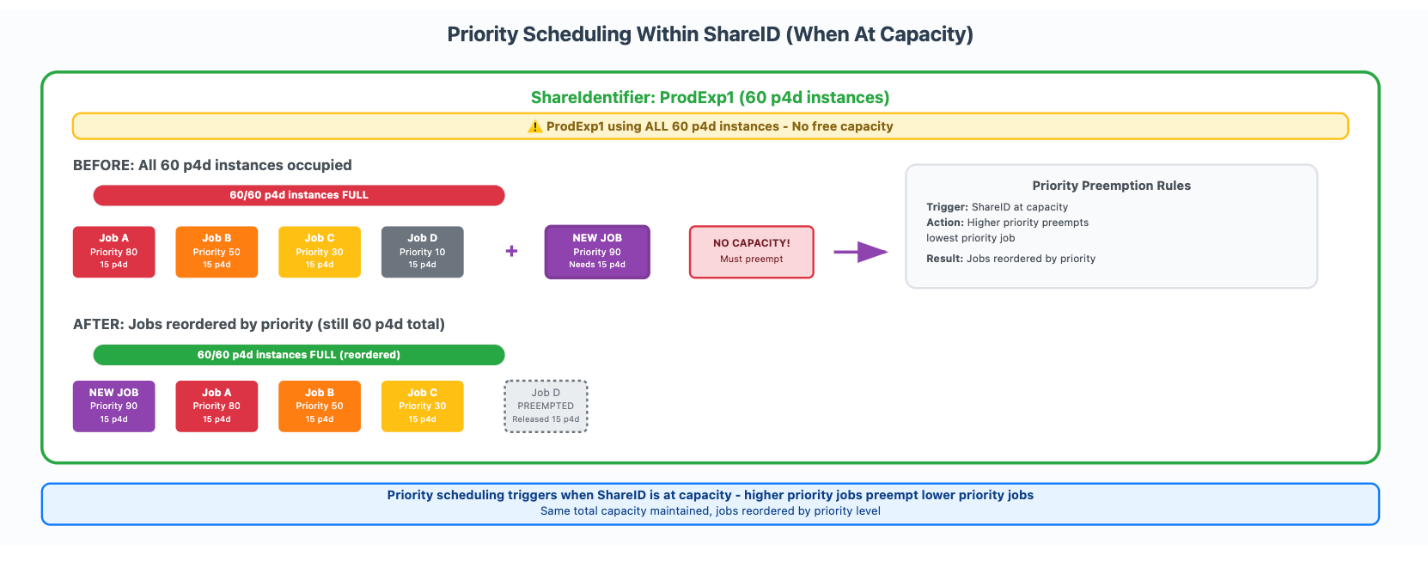
Внутри каждого Share Identifier приоритеты задач от 0 до 99 определяли порядок выполнения, но прерывание на основе приоритета срабатывало только тогда, когда ShareIdentifier достигал своего лимита выделенной емкости.
Мониторинг через Amazon CloudWatch
Команда использовала Amazon CloudWatch для мониторинга и настройки оповещений о критических событиях или отклонениях от ожидаемого поведения. Встроенная интеграция предоставила как реальную видимость, так и исторический анализ трендов, что помогло команде поддерживать операционную эффективность GPU-кластеров без создания пользовательских систем мониторинга.
Интересно наблюдать, как крупные компании решают, казалось бы, базовые проблемы оркестрации ML-обучения. Двойной рост утилизации GPU — это серьезное достижение, особенно учитывая масштабы Amazon. Однако возникает вопрос: почему такая простая, по сути, задача справедливого распределения ресурсов требовала столько времени для решения? Возможно, это говорит о том, что даже в технологических гигантах инфраструктурные проблемы ML-операций все еще находятся в зачаточном состоянии.
Операционный эффект
Внедрение AWS Batch для SageMaker Training jobs позволило исследователям запускать эксперименты без опасений о доступности ресурсов или конкуренции. Ученые могут отправлять задачи без ожидания ручного планирования, что увеличило количество экспериментов, которые могут выполняться параллельно.
Это привело к:
- Сокращению времени ожидания в очередях
- Повышению утилизации GPU
- Ускорению получения результатов обучения
- Увеличению пропускной способности исследований
- Сокращению сроков поставки
Решение особенно актуально для команд, работающих с интенсивным ML-обучением, где эффективное использование дорогостоящих GPU-ресурсов напрямую влияет на скорость инноваций и операционные расходы.





Оставить комментарий