
Оглавление
Исследовательские университеты, занимающиеся крупномасштабными проектами в области искусственного интеллекта и высокопроизводительных вычислений, сталкиваются с серьезными инфраструктурными вызовами, которые тормозят инновации и задерживают получение результатов. Традиционные локальные HPC-кластеры характеризуются длительными циклами поставки GPU, жесткими ограничениями масштабирования и сложными требованиями к обслуживанию.
Решение для ускорения исследований
Amazon SageMaker HyperPod устраняет рутинные задачи по построению моделей ИИ. Сервис позволяет быстро масштабировать задачи разработки моделей, включая обучение, тонкую настройку и вывод, используя кластеры из сотен или тысяч AI-ускорителей (NVIDIA GPU H100, A100 и других), интегрированных с предварительно настроенными HPC-инструментами и автоматическим масштабированием.
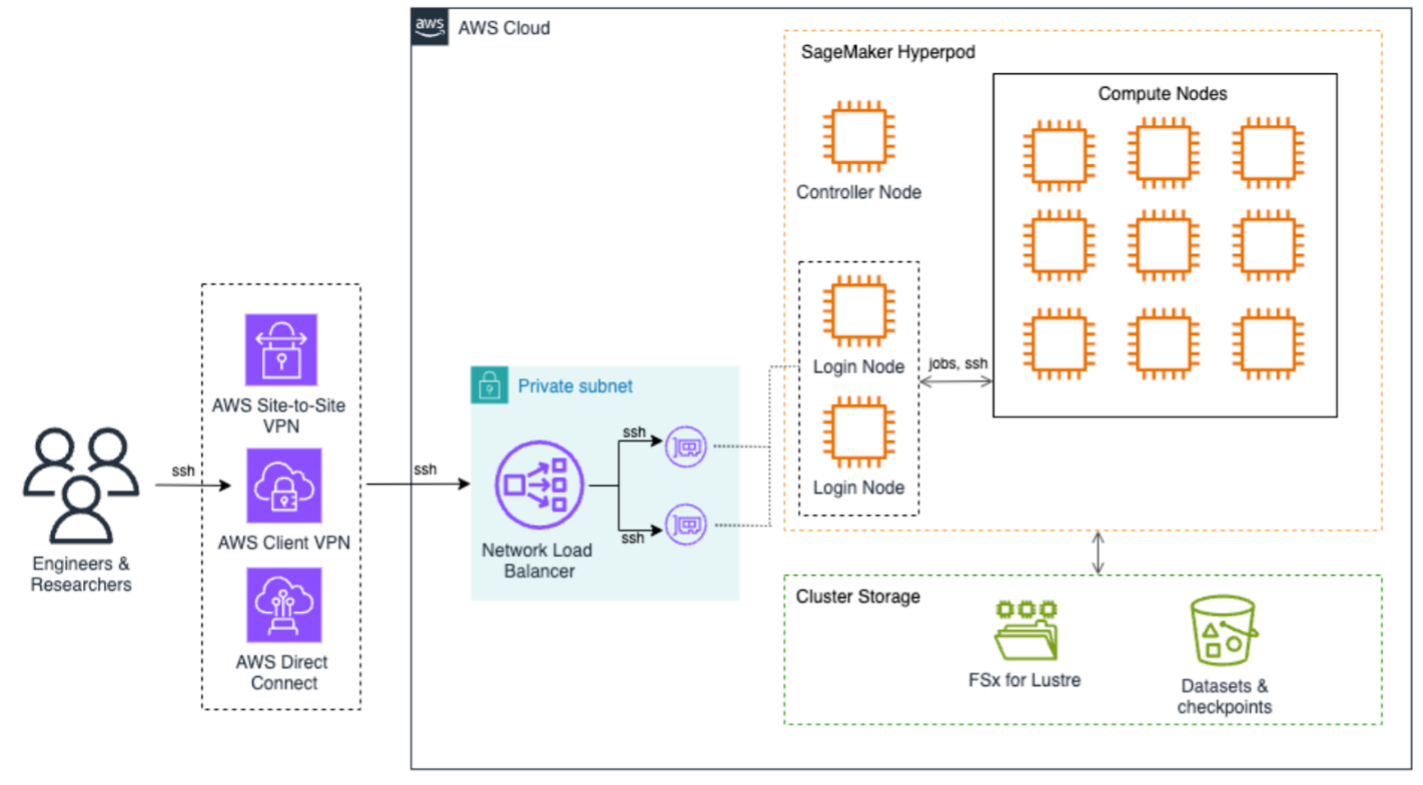
Архитектура решения
Amazon SageMaker HyperPod предназначен для поддержки крупномасштабных операций машинного обучения для исследователей и ML-ученых. Сервис полностью управляется AWS, что устраняет операционные накладные расходы при сохранении корпоративной безопасности и производительности.
Конечные пользователи могут использовать AWS Site-to-Site VPN, AWS Client VPN или AWS Direct Connect для безопасного доступа к кластеру SageMaker HyperPod. Эти подключения завершаются на Network Load Balancer, который эффективно распределяет SSH-трафик на узлы входа, являющиеся основными точками для отправки заданий и взаимодействия с кластером.
В основе архитектуры находится SageMaker HyperPod compute, управляющий узел, который оркестрирует операции кластера, и несколько вычислительных узлов, расположенных в конфигурации сетки. Эта настройка поддерживает эффективные распределенные тренировочные нагрузки с высокоскоростными соединениями между узлами, все содержится в приватной подсети для повышенной безопасности.
Предварительные требования
Перед развертыванием Amazon SageMaker HyperPod необходимо обеспечить следующие предварительные условия:
- Конфигурация AWS:
- Настроенный AWS Command Line Interface с соответствующими разрешениями
- Подготовленные файлы конфигурации кластера:
cluster-config.jsonиprovisioning-parameters.json
- Сетевая настройка:
- Виртуальное частное облако (VPC), настроенное для ресурсов кластера
- Группы безопасности с включенной коммуникацией Elastic Fabric Adapter (EFA)
- Файловая система Amazon FSx for Lustre для общего высокопроизводительного хранилища
Облачные HPC-решения вроде SageMaker HyperPod — это не просто очередной маркетинговый ход. Они реально решают фундаментальную проблему академических исследований: доступ к современному железу без необходимости содержать собственный дата-центр. Ирония в том, что университеты, которые десятилетиями были центрами инноваций, теперь вынуждены арендовать вычислительные мощности у коммерческих провайдеров. Но факт остается фактом: за те же деньги исследователи получают доступ к инфраструктуре, которую иначе бы просто не смогли себе позволить.
Процесс развертывания
Мы запустили AWS CloudFormation стек для подготовки необходимых компонентов инфраструктуры, включая VPC и подсеть, файловую систему FSx for Lustre, S3 bucket для скриптов жизненного цикла и тренировочных данных, а также IAM роли с ограниченными разрешениями для работы кластера.
Для выравнивания вычислительных ресурсов с исследовательскими потребностями отделов мы создали SLURM partitions, отражающие организационную структуру — например, команды NLP, компьютерного зрения и глубокого обучения. Мы использовали SLURM partition configuration для определения slurm.conf с пользовательскими разделами.
По материалам AWS Machine Learning Blog





Оставить комментарий