Оглавление
По данным блога AWS, платформа для машинного обучения SageMaker HyperPod теперь поддерживает автоматическое масштабирование вычислительных узлов с использованием Karpenter. Это позволяет динамически адаптировать кластеры под изменяющуюся нагрузку при выводе и обучении моделей, устраняя необходимость ручного управления ресурсами.
Решение для продакшен-нагрузок
Реализация вывода в продакшене требует мгновенного реагирования на скачки трафика. Традиционные подходы к масштабированию часто не успевают за резкими изменениями нагрузки, что приводит либо к простоям дорогостоящих GPU-ресурсов, либо к нарушению SLA при пиковой активности.
Новое решение интегрирует открытый инструмент Karpenter, разработанный AWS, в управляемую среду SageMaker HyperPod. Ключевое отличие от самостоятельных развертываний Karpenter — полное устранение операционных затрат на установку, настройку и поддержку контроллеров.
Ключевые возможности
- Полностью управляемый жизненный цикл — AWS берет на себя установку, обновления и техническое обслуживание Karpenter
- Провизионинг по требованию — система отслеживает ожидающие поды и выделяет необходимые вычислительные ресурсы из пула инстансов по требованию
- Масштабирование до нуля — возможность полного освобождения ресурсов без необходимости содержания инфраструктуры контроллера
- Интеллектуальный подбор инстансов — автоматический выбор оптимальных конфигураций на основе требований подов, зон доступности и цен
- Консолидация рабочих нагрузок — регулярная оптимизация распределения нагрузок для избежания недогрузки узлов
- Интеграция с отказоустойчивостью HyperPod — использование встроенных механизмов восстановления узлов
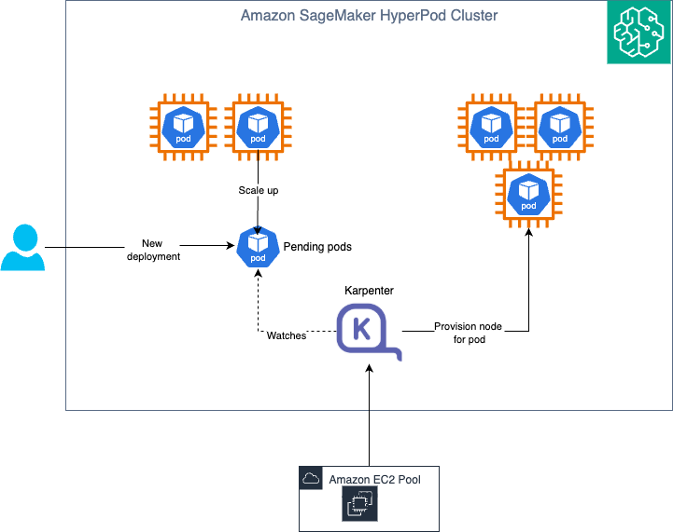
Архитектура решения
Karpenter работает как контроллер в кластере через четыре основных этапа: мониторинг непланируемых подов через Kubernetes API, оценка требований к ресурсам, провизионирование новых узлов через вызовы SageMaker HyperPod API и удаление неиспользуемых узлов для оптимизации затрат.
Автоматическое масштабирование в ML-инфраструктуре — это не роскошь, а необходимость для любого серьезного продакшена. AWS наконец-то доделали то, что должно было быть в HyperPod изначально. Интересно, сколько команд уже написали свои костыли вокруг этой проблемы и теперь будут мигрировать на нативное решение. Главный плюс — избавление от головной боли с самостоятельным поддержанием Karpenter, особенно в многокомандных средах.
Практическая значимость
Компании типа Perplexity, HippocraticAI и Articul8 уже используют SageMaker HyperPod для тренировки и развертывания моделей. Для них переход от экспериментов к реальному продакшену означает необходимость автоматического масштабирования GPU-ресурсов под продакшен-нагрузку.
Решение особенно актуально для организаций, которые работают с нестабильными паттернами трафика — сервисы с суточной сезонностью, продукты с виральным распространением или B2B-решения с пиковыми нагрузками в рабочие часы.
Важно отметить, что функция доступна только для кластеров SageMaker HyperPod на базе EKS и требует предварительной проверки квот на необходимые инстансы в Service Quotas консоли.





Оставить комментарий