Оглавление
Блог AWS пишет, что интеллектуальная обработка документов переходит на новый уровень с появлением масштабируемых решений для извлечения ключевой информации. Технология, известная как Key Information Extraction (KIE), становится критически важной для автоматизации бизнес-процессов в финансовом секторе, здравоохранении, юриспруденции и управлении цепочками поставок.
Проблема обработки документов в эпоху больших данных
Объемы документооборота растут экспоненциально, и традиционные методы ручной обработки становятся неэффективными. Современные системы должны не только автоматически извлекать данные, но и запускать сложные рабочие процессы с минимальным вмешательством человека. Точность обработки счетов, контрактов, медицинских записей и нормативных документов превратилась из конкурентного преимущества в бизнес-необходимость.
Датасет FATURA как эталон для тестирования
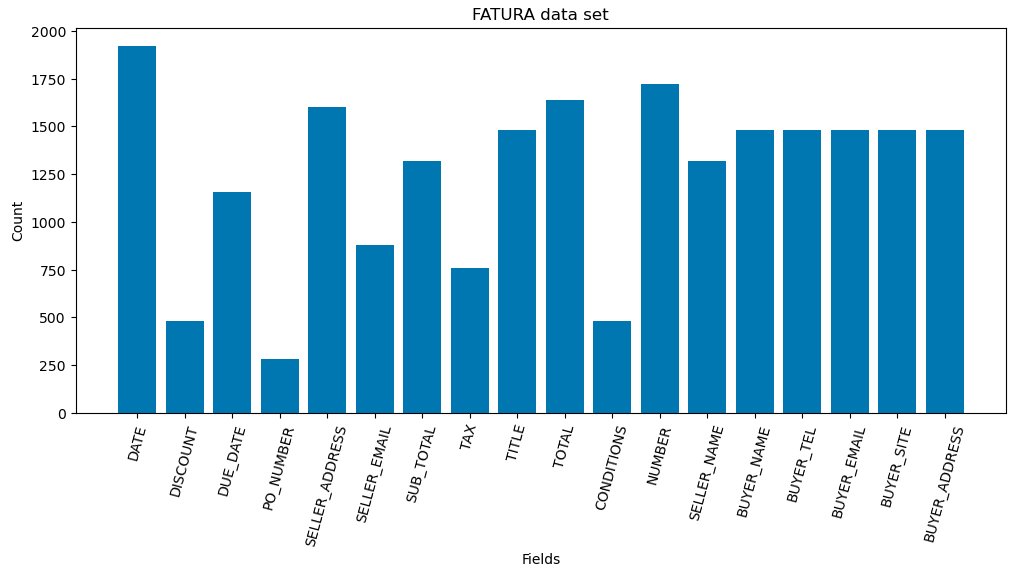
Для демонстрации возможностей KIE используется датасет FATURA, содержащий 10 000 счетов-фактур с 50 различными макетами. Каждый документ аннотирован 24 полями, что обеспечивает надежную основу для оценки точности извлечения. Однако при анализе датасета обнаружились проблемы с согласованностью аннотаций:
- Структурные несоответствия (вложенные vs плоские представления полей)
- Несогласованные форматы значений (префиксы, числовые значения как строки)
- Пропущенные поля и множественные значения
Для обеспечения честной оценки в исследовании использовали 1 960 образцов из 49 различных макетов, исключив один макет из-за несоответствий в аннотациях.
Amazon Bedrock как платформа для KIE
Amazon Bedrock упрощает обработку документов, предоставляя доступ к большим языковым моделям для извлечения структурированной информации без сложных rule-based систем.
Несмотря на кажущуюся простоту, извлечение структурированных данных из документов остается одной из самых сложных задач компьютерного зрения и NLP. Тонкие различия в форматировании, контекстные зависимости между полями и необходимость обработки отсутствующей информации требуют сложных подходов. Решения на основе LLM, такие как Amazon Nova, демонстрируют впечатляющий прогресс, но их реальная эффективность сильно зависит от качества аннотаций и методологии оценки.
Практический подход Amazon включает три критических этапа: подготовку данных, разработку решения и измерение производительности. Это комплексная методология, которая учитывает не только точность извлечения, но и скорость обработки, операционные затраты и специфические отраслевые требования.





Оставить комментарий