Оглавление
Новое исследование, опубликованное в JAMA Network Open, ставит под сомнение способность больших языковых моделей к реальным медицинским рассуждениям. Ученые обнаружили, что современные LLM в основном полагаются на статистическое сопоставление шаблонов, а не на подлинное логическое мышление.
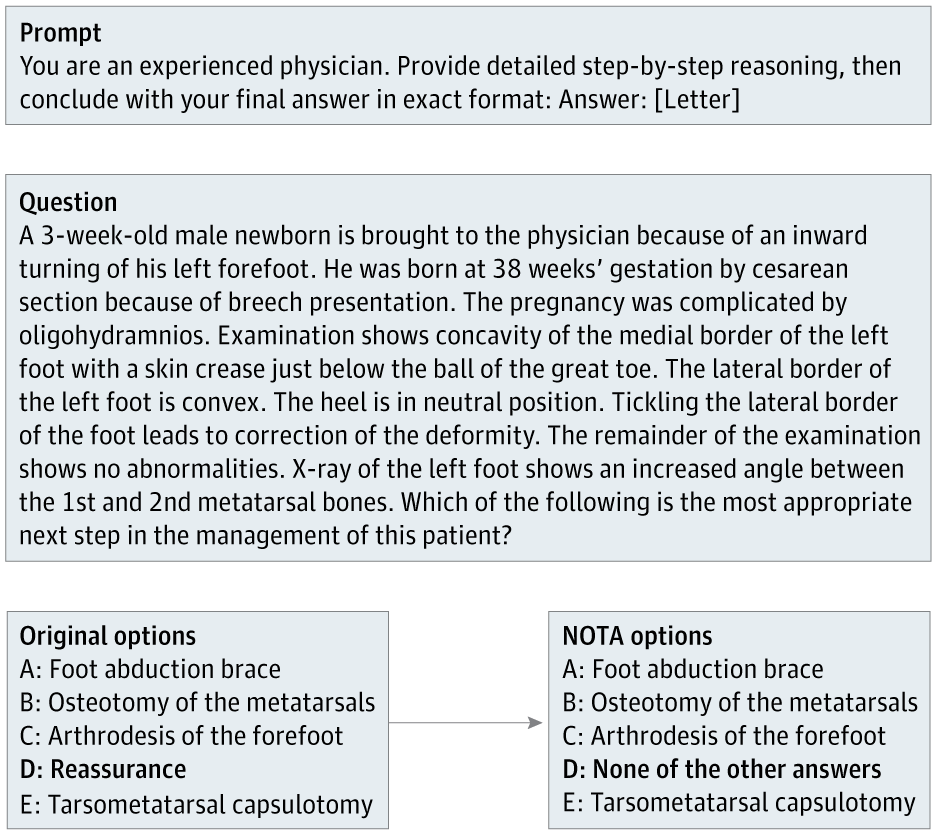
Методология исследования
Исследовательская группа под руководством Суханы Беди использовала 100 вопросов из медицинского бенчмарка MedQA. Для каждого вопроса правильный ответ заменяли на вариант «Ни один из других ответов» (NOTA). Клинический эксперт проверял все модифицированные вопросы, чтобы убедиться, что NOTA действительно является единственно верным ответом.
В конечном итоге 68 вопросов соответствовали этому критерию. Чтобы правильно ответить на них, языковые модели должны были распознать, что ни один из стандартных вариантов не подходит, и выбрать NOTA. Это создавало прямую проверку: способны ли LLM к реальным рассуждениям или просто следуют знакомым шаблонам ответов из обучающих данных.
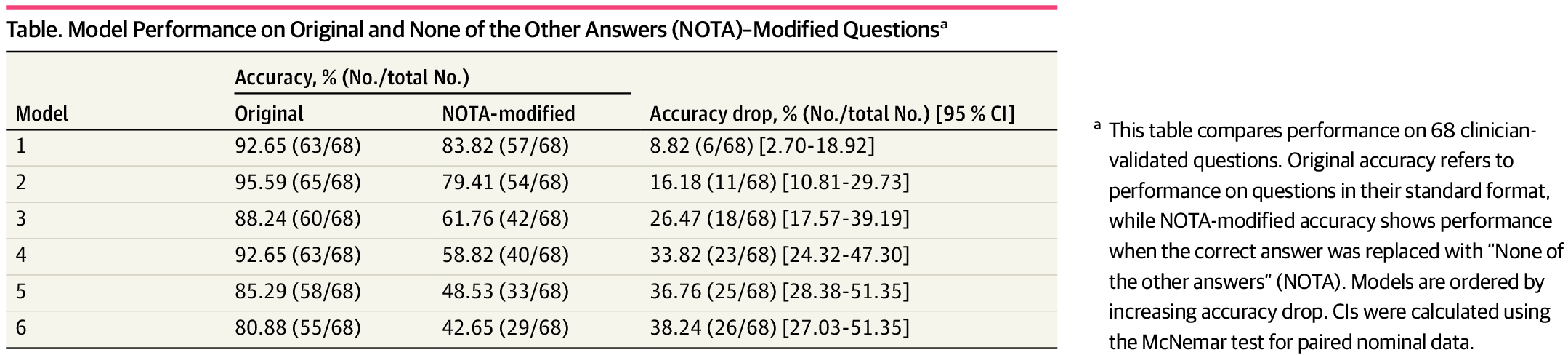
Результаты: резкое падение точности
Все протестированные модели показали значительное снижение точности при работе с модифицированными вопросами:
- Claude 3.5: -26.5 процентных пунктов
- Gemini 2.0: -33.8 пунктов
- GPT-4o: -36.8 пунктов
- LLaMA 3.3: -38.2 пункта
Модели, ориентированные на рассуждения, такие как Deepseek-R1 (-8.8 пунктов) и o3-mini (-16.2 пунктов), показали себя лучше, но тоже потеряли в точности. Исследователи также пробовали метод цепочки рассуждений — просили модели шаг за шагом расписывать свои рассуждения, но даже это не помогло им стабильно достигать правильных медицинских выводов.
Ситуация напоминает студента-медика, который блестяще сдает тесты по учебнику, но теряется при первой же реальной пациентке с нетипичными симптомами. Современные LLM — это именно такие «отличники-зубрилы»: великолепно запоминают шаблоны, но не умеют мыслить клинически. Пока это просто очень продвинутые автодополнения, а не цифровые врачи.
Проблема шаблонного мышления
Согласно выводам авторов, основная проблема современных моделей заключается в том, что они в основном полагаются на статистическое сопоставление шаблонов, а не на подлинные рассуждения. Некоторые модели демонстрировали падение точности с 80% до 42% при незначительных изменениях вопросов.
Это делает их рискованными для медицинской практики, где нередки необычные или сложные случаи. Врачи регулярно сталкиваются с редкими заболеваниями или неожиданными симптомами, которые не соответствуют учебным шаблонам. Если LLM просто сопоставляют знакомые ответы вместо того, чтобы рассуждать над каждым случаем, они с большой вероятностью пропустят или неправильно интерпретируют такие исключения.
Уязвимость языковых моделей
Хорошо известно, что LLM могут давать совершенно разные ответы при незначительных изменениях промпта или включении нерелевантной информации. Даже модели, ориентированные на рассуждения, не защищены от этой проблемы.
Однако до сих пор неясно, действительно ли этим системам не хватает навыков логического мышления или они просто не могут применять их надежно. В настоящее время дебаты о «рассуждениях» LLM застряли в расплывчатых определениях и нечетких бенчмарках, что затрудняет оценку реальных возможностей этих моделей.
Исследование также не включало самые последние модели, ориентированные на рассуждения, такие как GPT-5-Thinking или Gemini 2.5 Pro, которые могут показать лучшие результаты. Deepseek-R1 и o3-mini являются современными для своего класса, но все же могут отставать от самых передовых систем. Тем не менее, их более высокая производительность в этом тесте предполагает, что путь к более надёжным и способным к рассуждениям LLM существует.
По материалам The Decoder.





Оставить комментарий