
Оглавление
Компания Together AI анонсировала революционную систему ATLAS — адаптивный спекулятор, который автоматически улучшает производительность языковых моделей во время работы без ручной настройки. Это первый в своем роде подход к спекулятивному декодированию, который динамически обучается на реальных данных.
Проблема статических спекуляторов
Традиционные спекуляторы, используемые для ускорения вывода LLM, имеют фундаментальное ограничение — они статичны. Обучаясь на фиксированном наборе данных, такие модели не могут адаптироваться к изменяющимся рабочим нагрузкам. Когда кодовая база растет, паттерны трафика смещаются или распределение запросов меняется, даже самые оптимизированные спекуляторы начинают отставать.
ATLAS решает эту проблему через непрерывное обучение на исторических паттернах и живом трафике. Система автоматически подстраивается под поведение целевой модели в реальном времени, что означает: чем больше вы используете сервис вывода, тем лучше работает ATLAS.
Архитектура двойного спекулятора
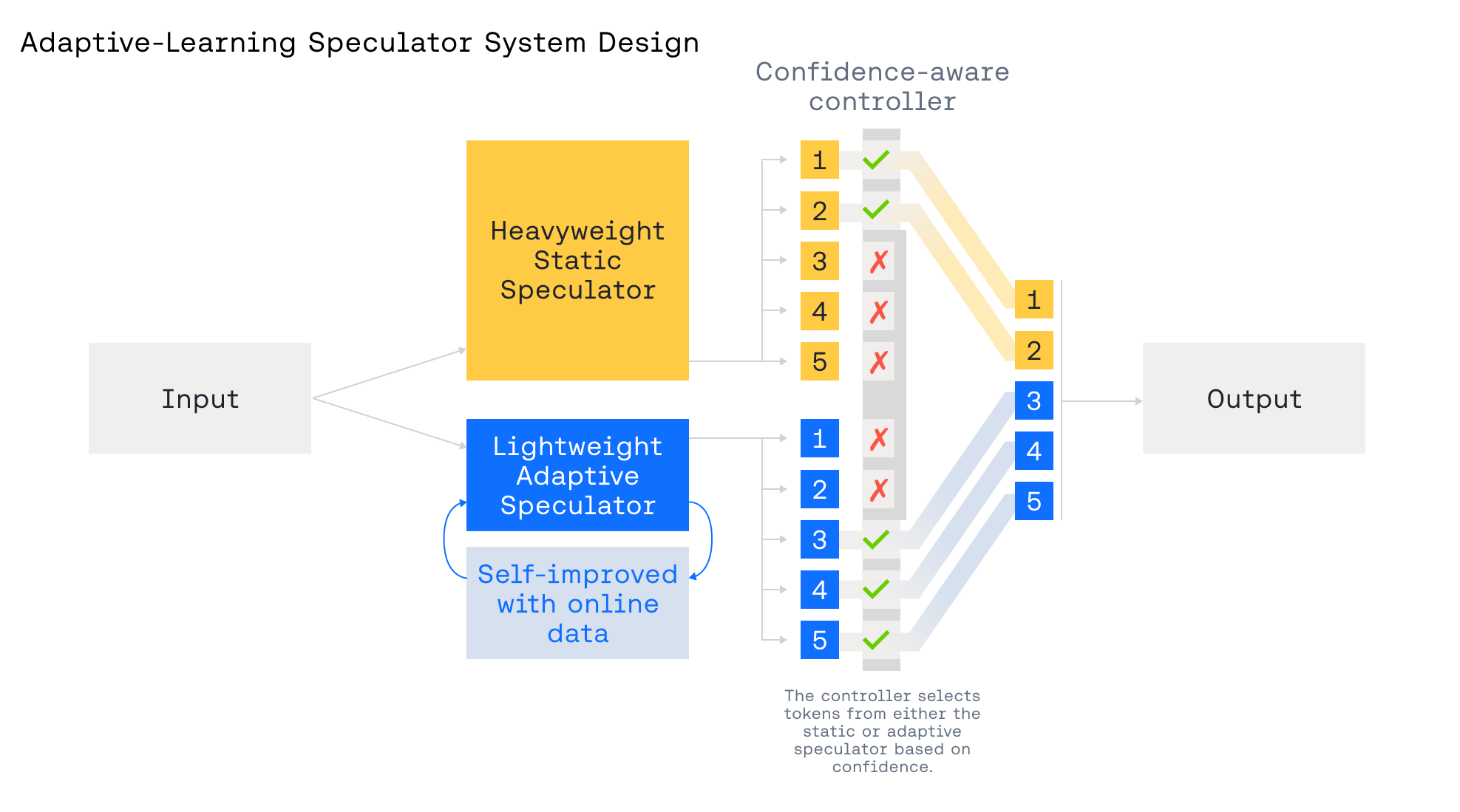
Система построена на двух взаимодействующих спекуляторах:
- Статический спекулятор — тяжеловесная модель, обученная на обширном корпусе, обеспечивающая надежную базовую производительность
- Адаптивный спекулятор — легковесная модель, которая быстро обновляется на основе реального трафика, специализируясь на новых доменах
- Контроллер с оценкой уверенности — выбирает, какому спекулятору доверять на каждом шаге и определяет оптимальную глубину предсказания
Статический спекулятор служит страховочным механизмом — он обеспечивает стабильную производительность даже при резких изменениях трафика или когда адаптивный путь еще не обучен.
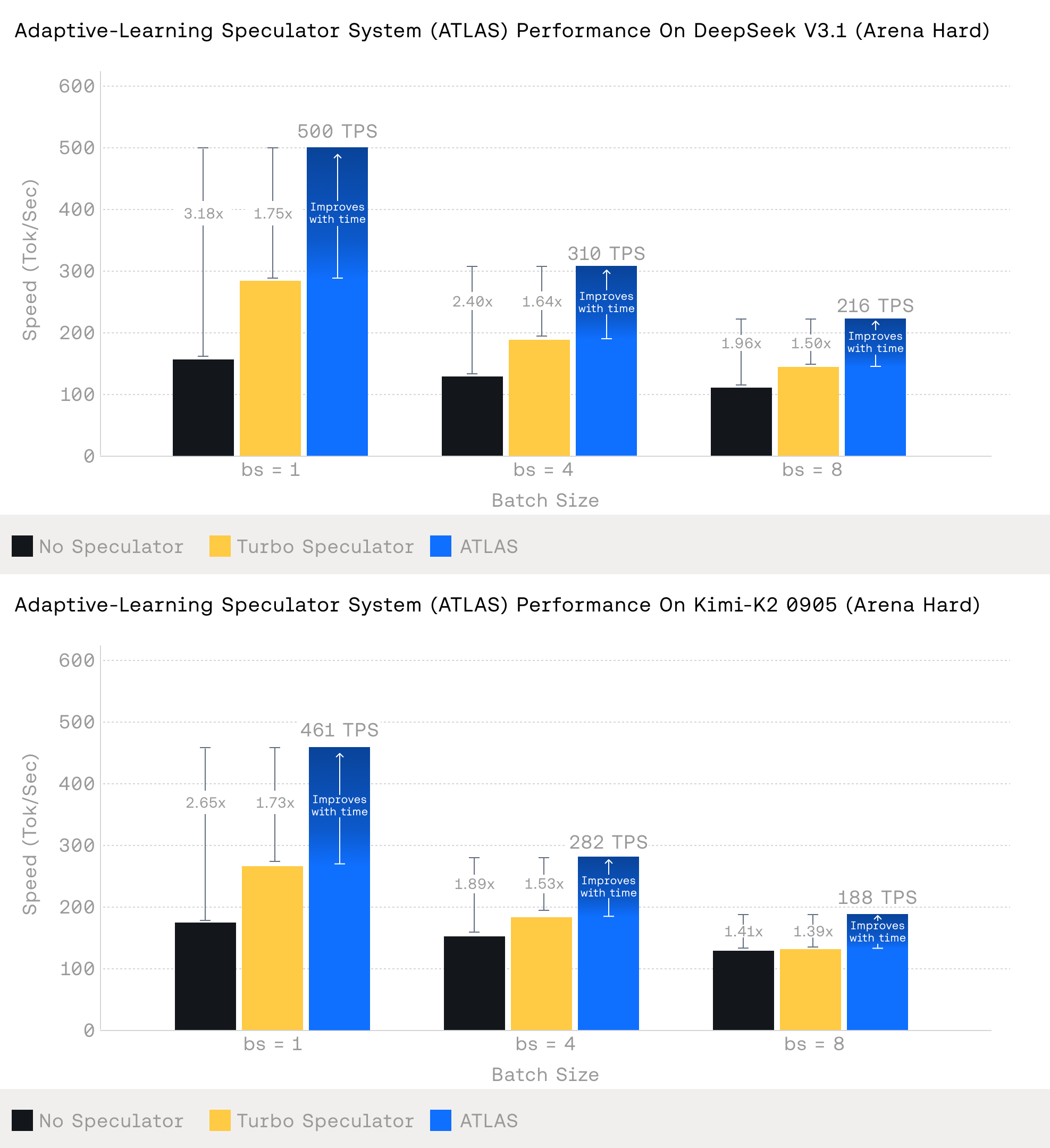
Производительность и результаты
На платформе NVIDIA HGX B200 с полностью адаптированной системой ATLAS демонстрирует впечатляющие результаты:
- До 500 TPS на модели DeepSeek-V3.1
- До 460 TPS на модели Kimi-K2
- Ускорение в 2.65 раза по сравнению со стандартным декодированием
Система превосходит даже специализированное железо вроде Groq при работе с Arena Hard трафиком.
Адаптивное спекулятивное декодирование — это тот редкий случай, когда инженерная элегантность встречается с практической полезностью. Вместо того чтобы замораживать оптимизацию в момент обучения, ATLAS превращает сам процесс инференса в обучающую среду. Особенно впечатляет применение в RL-тренинге, где статические спекуляторы быстро теряют синхронизацию с изменяющейся политикой. Правда, возникает закономерный вопрос: насколько устойчива такая система к аномальным паттернам запросов, которые могут «сломать» адаптивный компонент?
Применение в реальных сценариях
Система особенно эффективна в сценариях, где рабочие нагрузки постоянно эволюционируют. Например, во время сессии программирования адаптивный спекулятор может специализироваться на конкретных файлах кода, которые редактируются и не были видны во время обучения. Это дополнительно увеличивает rate принятия токенов и скорость декодирования.
В reinforcement learning, где фаза генерации траекторий занимает до 70% общего времени, ATLAS сохраняет выравнивание с целевой политикой даже при ее смещении в процессе обучения.
По материалам Together AI.





Оставить комментарий