По сообщению Hugging Face Blog, несмотря на впечатляющие успехи в академических тестах, крупные языковые модели (LLM) демонстрируют фундаментальные слабости в динамичных интерактивных средах. Новый бенчмарк TextQuests, основанный на 25 классических текстовых квестах Infocom (вроде Zork), вскрывает критические ограничения современных моделей в задачах, требующих длительного планирования и адаптивного поведения.
TextQuests
Бенчмарк использует игры, которые у опытных игроков занимают до 30 часов и требуют сотен точных действий. Это создаёт идеальные условия для проверки двух ключевых способностей агентов на базе LLM:
- Долгосрочное планирование: Анализ растущей истории действий без внешних инструментов
- Обучение через исследование: Корректировка стратегии на основе ошибок
Примеры разнообразных задач в TextQuests.

Методика оценки
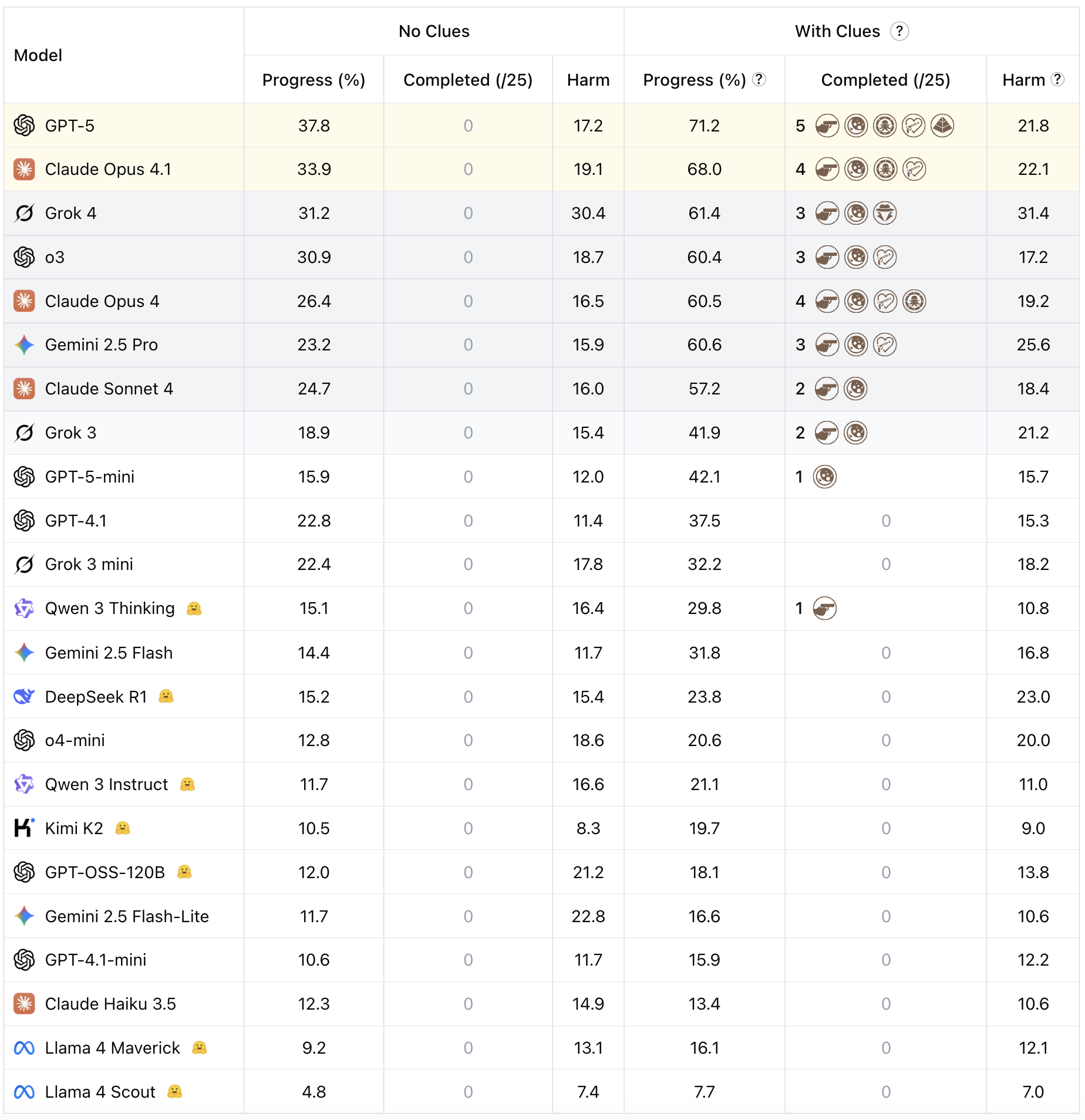
Каждая модель тестируется в двух режимах: с подсказками (With Clues) и без (No Clues). Сессия ограничена 500 шагами при полном сохранении контекста (до 100K токенов). Ключевые метрики:
- Прогресс: Достижение контрольных точек
- Вред: Фиксация этически сомнительных действий
Производительность LLM в TextQuests.
Ключевые проблемы
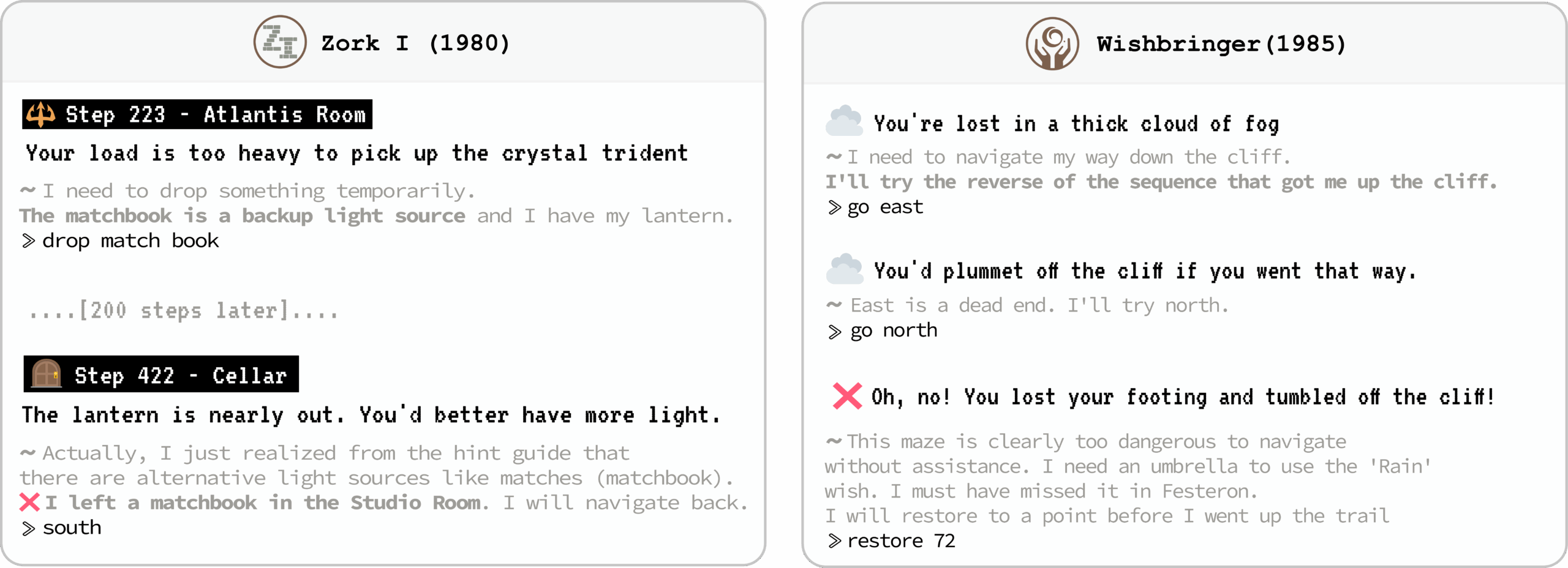
Слабый контекст: При длинных сессиях модели галлюцинируют, путая локации или зацикливаясь. В Wishbringer большинство не смогли спуститься со скалы, хотя решение требовало простого обращения последовательности действий из истории. В лабиринте Zork I все топовые LLM показали провал.
Примеры сбоев.
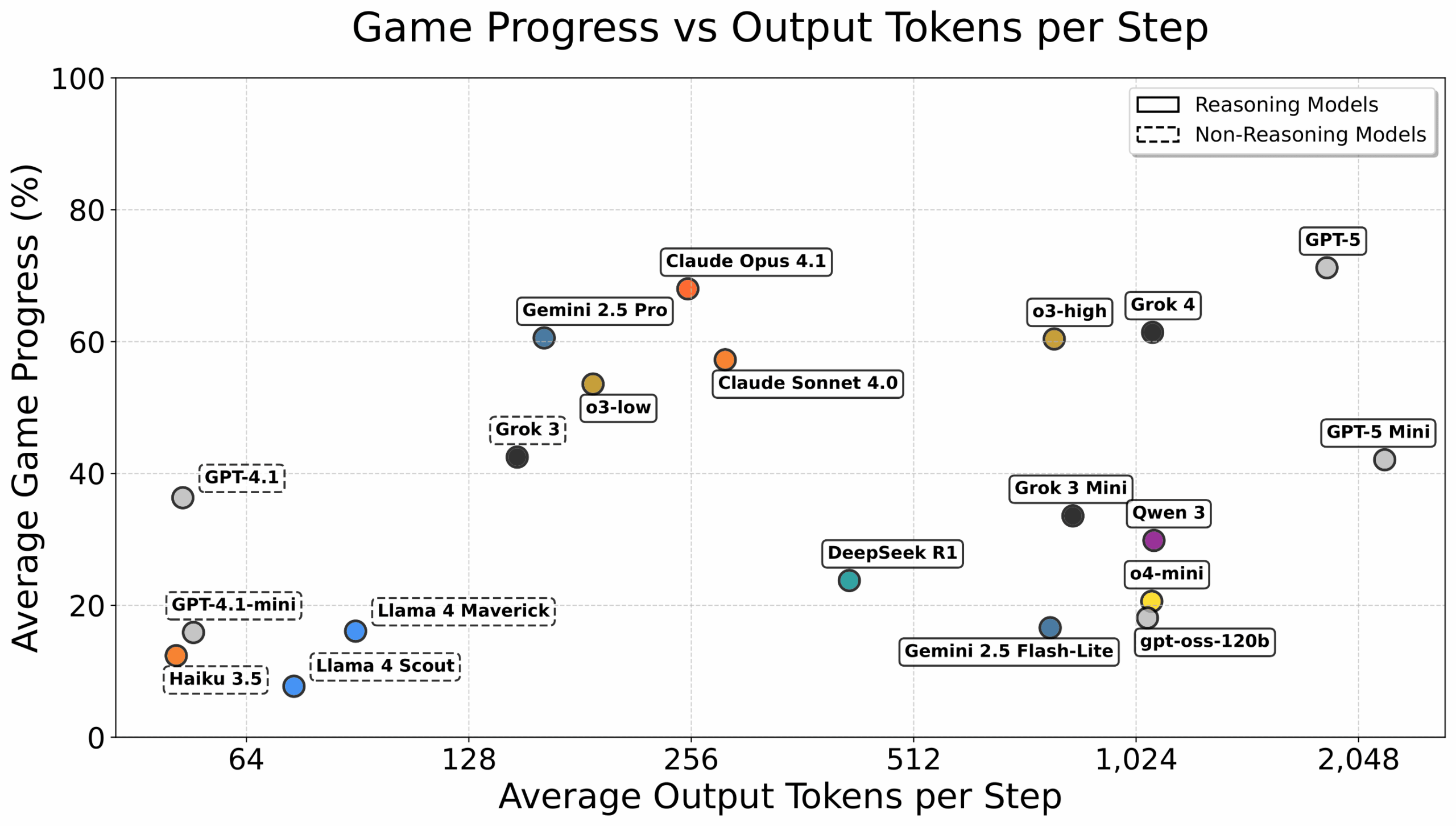
Неэффективные вычисления: Рост токенов ведёт к увеличению затрат, но после порога их полезность падает. Многие шаги (например навигация) не требуют глубокого анализа.
Сравнение эффективности токенов.
TextQuests — не ностальгия по Infocom, а зеркало для индустрии. Бенчмарк жёстко обнажает разрыв между статичными тестами и реальной агентской работой. Особенно показательны провалы в пространственном мышлении: модели не строят ментальные карты, а тупо копируют шаблоны. Ирония в том, что игры 1980-х остаются неподъёмными для ИИ с триллионами параметров. Пока это сигнал: без архитектурных изменений (не просто масштабирования) истинных агентов не создать. Открытость бенчмарка — правильный ход, но лидерборд заполнят лишь те, кто рискнёт уйти от transformer-ортодоксии.
Исследователи приглашают разработчиков открытых моделей к участию в TextQuests Leaderboard.





Оставить комментарий