
Оглавление
Исследователи из Tencent AI Lab и Вашингтонского университета в Сент-Луисе разработали революционный фреймворк R-Zero, который позволяет большим языковым моделям самостоятельно улучшаться без какого-либо человеческого вмешательства или размеченных данных. Технология использует обучение с подкреплением для генерации собственных тренировочных данных с нуля, решая одну из главных проблем создания саморазвивающихся ИИ-систем.
Проблема самообучающихся языковых моделей
Идея саморазвивающихся ИИ-систем предполагает создание моделей, которые могут автономно генерировать, улучшать и обучаться на собственном опыте. Однако основной вызов заключается в том, что обучение таких моделей требует огромных объемов высококачественных задач и меток, которые выступают в качестве сигналов обучения.
Полная зависимость от человеческих аннотаторов не только дорога и медленна, но и создает фундаментальное ограничение — потенциальные возможности ИИ ограничиваются тем, чему могут научить люди. Существующие методы без меток все еще полагаются на предсуществующие наборы задач, что ограничивает их применимость в действительно саморазвивающихся сценариях.
Как работает R-Zero
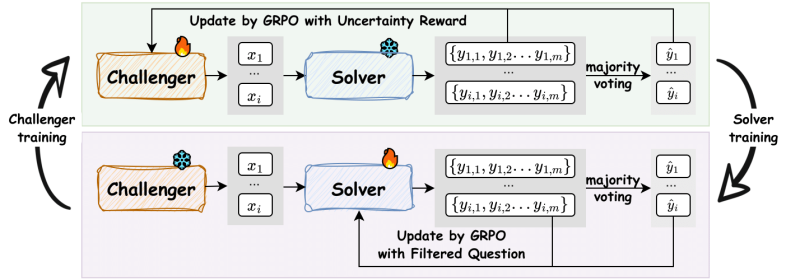
Фреймворк R-Zero предназначен для обучения языковых моделей, способных к рассуждению, которые могут развиваться с нуля без внешних данных. Процесс начинается с единственной базовой модели, которая разделяется на две роли: «Challenger» и «Solver». Эти две модели оптимизируются независимо, но развиваются вместе через непрерывный цикл взаимодействия.
Цель Challenger — создавать новые задачи, которые находятся точно на границе текущих возможностей Solver — не слишком легкие и не невозможные. Solver в свою очередь получает награду за решение этих все более сложных задач.
Как объяснил в комментариях VentureBeat Ченгсонг Хуанг, соавтор исследования и докторант Вашингтонского университета: «Мы обнаружили, что главная сложность — не в генерации ответов… а в создании высококачественных, новых и постепенно более сложных вопросов. Хорошие учителя встречаются гораздо реже, чем хорошие ученики».
После того как Challenger генерирует достаточно вопросов, они фильтруются для разнообразия и компилируются в тренировочный набор данных. На этапе обучения Solver дорабатывается на этих сложных вопросах. «Правильный» ответ для каждого вопроса определяется большинством голосов из предыдущих попыток Solver.
Результаты экспериментов
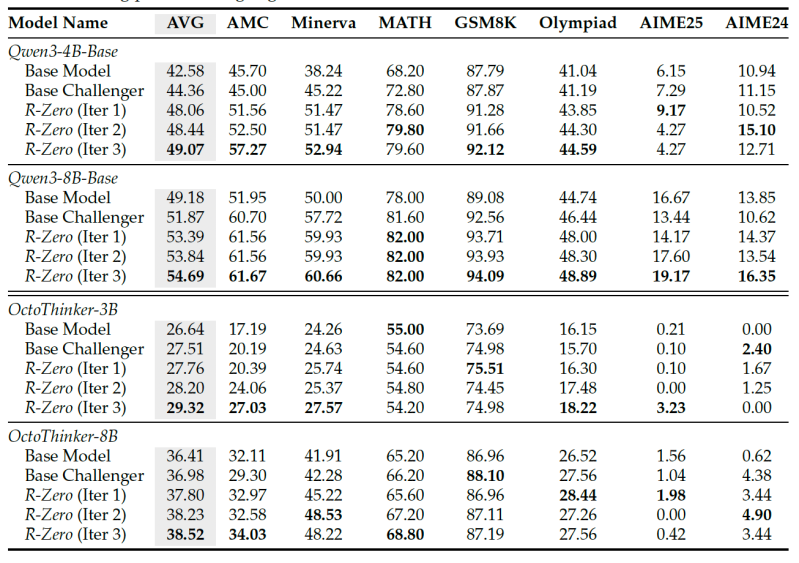
Исследователи протестировали R-Zero на нескольких открытых LLM, включая модели из семейств Qwen3 и OctoThinker. Модели сначала обучались на математических задачах, а затем проверялась возможность переноса приобретенных навыков рассуждения на другие комплексные бенчмарки:
- Модель Qwen3-4B-Base показала улучшение на +6.49 баллов в среднем на математических бенчмарках
- Более крупная модель Qwen3-8B-Base увеличила средний математический балл на +5.51 после трех итераций
- Навыки, приобретенные из математических задач, эффективно переносились на задачи общего рассуждения
Ирония в том, что мы пытаемся создать ИИ, который превзойдет человеческие возможности, но сталкиваемся с классической проблемой образования: качество обучения падает, когда ученик начинает превосходить учителя. R-Zero — это элегантное инженерное решение, но оно лишь отодвигает проблему на несколько итераций, пока качество самогенерируемых данных не начинает деградировать. Настоящий прорыв будет, когда мы найдем способ поддерживать стабильное качество «учителя» в совместно-эволюционном процессе.
Ограничения и перспективы
Исследователи выявили критическую проблему: по мере того как Challenger успешно генерирует все более сложные задачи, способность Solver производить надежные «правильные» ответы через большинство голосов начинает снижаться. Точность самогенерируемых меток упала с 79% в первой итерации до 63% к третьей по сравнению с сильной oracle LLM такой как GPT-4.
Хуанг признал, что это фундаментальная проблема для парадигмы саморазвития: «Наша работа — доказательство концепции, демонстрирующее потенциал этого подхода, но мы признаем, что поддержание стабильного долгосрочного улучшения без выхода на плато — значительное препятствие».
Текущий механизм лучше всего подходит для областей, таких как математика, где правильность может быть объективно определена. Для предприятий подход «с нулевыми данными» может стать изменяющим правила игры, особенно в нишевых областях, где высококачественные данные редки или отсутствуют.





Оставить комментарий