
Оглавление
Бенчмарки функциональной корректности давно стали стандартом для оценки ИИ-моделей, генерирующих код. Они эффективно измеряют, проходит ли сгенерированный код тесты. По мере эволюции языковых моделей они становятся все лучше в решении этих задач. Однако для инженеров, внедряющих такой код в продакшн, функциональная корректность — лишь половина дела.
Чтобы понять реальную эффективность ИИ-кодеров, необходимо оценить также структурное качество, безопасность и поддерживаемость их кода. Несколько месяцев назад компания Sonar начала анализировать качество, безопасность и поддерживаемость кода, созданного ведущими языковыми моделями, тестируя их на более чем 4000 различных Java-задач с помощью статического анализатора SonarQube.
Теперь все результаты оценки доступны в новом Sonar LLM leaderboard, где представлены свежие данные по GPT-5.2 High, GPT-5.1 High, Gemini 3.0 Pro, Opus 4.5 Thinking и Claude Sonnet 4.5.
Визуализация компромиссов
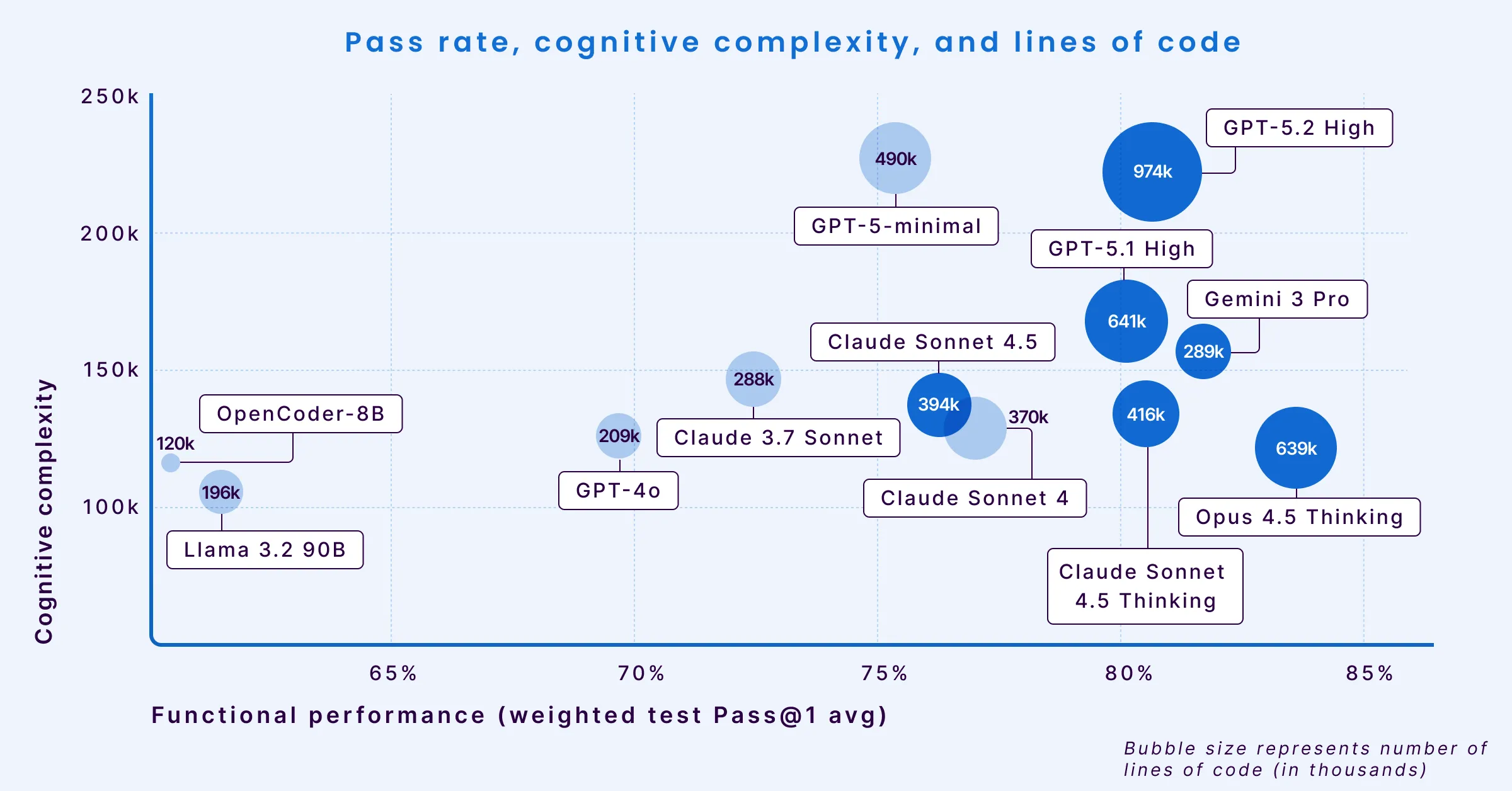
Чтобы понять компромиссы и поведение разных моделей, их разместили на трех ключевых измерениях: процент прохождения тестов (ось X), когнитивная сложность кода (ось Y) и многословность (размер пузыря).
По мере того как модели становятся более «производительными» и смещаются вправо, их выводы становятся многословнее и сложнее, налагая более высокую нагрузку на инженеров, которые этот код проверяют и используют.
Корреляция со сложностью
Исследование выявило корреляцию между способностью модели к рассуждению и сложностью генерируемого кода. Когда модели пытаются создать сложные, stateful-решения для трудных задач, они часто отходят от простого кода. Этот сдвиг порождает инженерные проблемы, которые обнаружить сложнее, чем простые синтаксические ошибки.
Например:
- Opus 4.5 Thinking лидирует по функциональной производительности с показателем прохождения тестов 83,62% (поэтому он самый правый на диаграмме). Однако эта производительность достигается ценой высокой многословности: модель сгенерировала 639 465 строк кода для решения тестовых задач (поэтому её пузырь один из самых больших на графике). Это более чем вдвое превышает объем кода, созданного менее многословными моделями.
- Gemini 3 Pro выделяется как аномалия эффективности. Она достигает сопоставимого показателя в 81,72%, сохраняя низкую когнитивную сложность и низкую многословность (маленький размер пузыря). Такое сочетание предполагает уникальную способность решать сложные задачи с помощью лаконичного, читаемого кода. Однако у Gemini самая высокая плотность проблем по сравнению с другими современными моделями.
- GPT-5.2 High занимает третье место по функциональной производительности (80,66%), уступая Opus 4.5 и Gemini 3 Pro. Несмотря на высокий процент прохождения, модель сгенерировала самый большой объем кода в когорте — 974 379 строк. По сравнению со своим предшественником GPT-5.1 High, GPT-5.2 демонстрирует регресс в поддерживаемости и увеличение плотности багов всех уровней тяжести, хотя и показывает незначительные улучшения в общей безопасности и количестве критических уязвимостей.
- GPT-5.1 High также достигает 80% прохождения тестов, но демонстрирует рост когнитивной сложности кода (высокое положение на оси Y). Это указывает на то, что, решая задачу, модель генерирует логику, которую структурно сложнее читать и поддерживать.
Инженерная дисциплина и надежность
Хотя модели демонстрируют сильные логические способности, анализ выявил различные паттерны в том, как они справляются с основами программной инженерии, такими как управление ресурсами и потокобезопасность. Контекстуализация этих цифр показывает значительные различия в надежности между моделями, которые в остальном имеют схожие показатели прохождения тестов.
- Проблемы с параллелизмом: GPT-5.2 High демонстрирует мощные рассуждения, но более подвержена ошибкам параллелизма, чем её аналоги. Она генерирует 470 проблем с параллелизмом на миллион строк кода (MLOC) — показатель почти вдвое выше, чем у ближайшей модели, и более чем в 6 раз выше, чем у Gemini 3 Pro.
- Управление ресурсами: Claude Sonnet 4.5 показала более высокую частоту утечек ресурсов, генерируя 195 утечек на MLOC. Для сравнения, GPT-5.1 High выдала только 51 утечку на MLOC для тех же задач.
- Точность потока управления: Gemini 3 Pro продемонстрировала самую высокую частоту ошибок потока управления (200 на MLOC), что почти в 4 раза выше, чем у Opus 4.5 Thinking (55 на MLOC). GPT 5.2 High показала высокую точность, достигнув самой низкой частоты ошибок в когорте — всего 22 ошибки потока управления на MLOC.
Проверка безопасности
Безопасность остается критически важной областью для проверки. Анализ подтверждает, что модели не всегда надежно отслеживают ненадежные пользовательские данные от источника до точки использования.
Claude Sonnet 4.5 показала 198 критических уязвимостей на MLOC, включая уязвимости обхода пути и инъекций. Этот показатель выше, чем у других моделей в её классе. Opus 4.5 Thinking показал себя значительно лучше с всего 44 критическими уязвимостями на MLOC, что позволяет предположить, что его процесс «размышления» может позволить лучше проверять ограничения безопасности перед генерацией вывода. GPT 5.2 High достигла лучшего показателя безопасности в когорте — всего 16 критических уязвимостей на MLOC. Хотя другие метрики показали, что эта модель испытывает трудности с объемом кода и общей плотностью багов, её обработка критически важных точек безопасности в настоящее время является лучшей в своем классе.
Проблема поддерживаемости
Помимо критических ошибок, поддерживаемость остается основным фактором в общей стоимости владения ИИ-кодом. Проблемы типа «запах кода», которые ухудшают поддерживаемость, составили от 92% до 96% всех обнаруженных проблем в оцениваемых моделях.
GPT-5.1 High сгенерировала более 4400 общих «запахов» на MLOC. Claude Sonnet 4.5 чаще обходила лучшие практики проектирования.
Это исследование — отрезвляющий душ для тех, кто верит, что ИИ-кодеры скоро заменят инженеров. Да, они бьют рекорды по прохождению тестов, но за это приходится платить. Opus 4.5 выдает километры кода, GPT-5.2 High плодит ошибки параллелизма, а Claude Sonnet 4.5 игнорирует базовые принципы проектирования. Самый ценный вывод здесь даже не в цифрах, а в том, что «умнее» модель — не значит «аккуратнее». Gemini 3 Pro, например, показывает, что можно быть и эффективным, и лаконичным. Но в целом, эти данные — четкий сигнал для инженерных лидеров: ИИ-помощник — это не автопилот, а очень мощный, но иногда небрежный стажер, которого нужно строго контролировать. Рейтинг Sonar теперь дает для этого конкретные метрики.
По материалам Security Boulevard.





Оставить комментарий