
Оглавление
Когда команда ServiceNow AI столкнулась с необходимостью сделать свою 15-миллиардную модель рассуждений более эффективной, они обнаружили парадоксальный факт: интуитивный подход к выбору данных для дистилляции оказался ошибочным. Ключом к успеху стали не обучающие данные общего назначения, а специально отобранные трассы рассуждений.
Что получилось построить
Семейство моделей Apriel-H1 включает семь версий с 25-40 слоями Mamba из 50 возможных. Флагманская модель Apriel-H1-15b-Thinker-SFT демонстрирует увеличение пропускной способности в 2,1 раза при минимальной потере качества: показатели MATH500 и MTBench улучшились (0,90 → 0,92 и 8,30 → 8,58 соответственно), тогда как GSM8k (0,97 → 0,95), GPQA (0,59 → 0,55) и AIME24 (0,70 → 0,65) немного снизились. Общий объем обучения составил 76,8 миллиардов токенов.
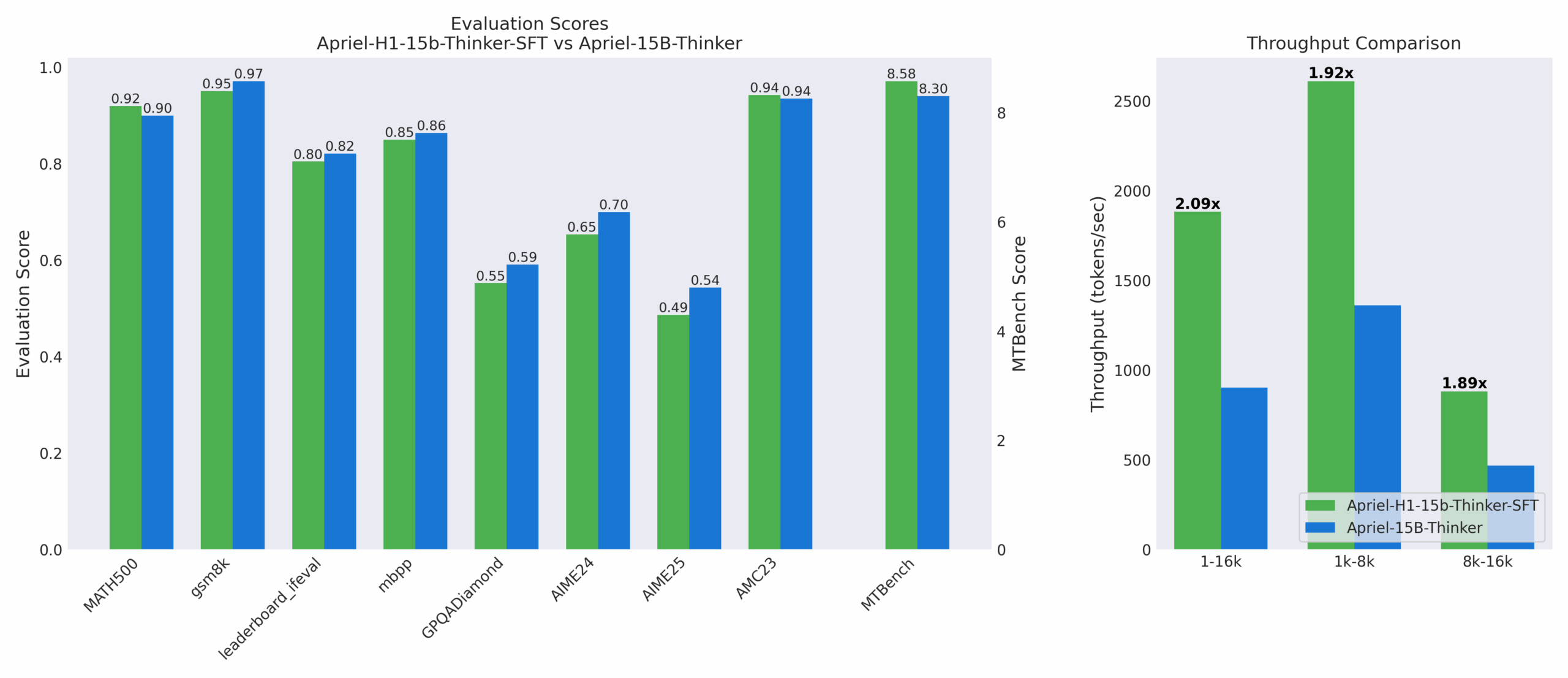
Сравнение Apriel-H1-15b-Thinker-SFT (зеленый) с полным учителем внимания (синий). Качество рассуждений остается практически неизменным при увеличении пропускной способности в 1,89-2,09 раза в зависимости от длины контекста.
Поразительно, но инженеры ServiceNow доказали, что эффективность и качество в языковых моделях — не взаимоисключающие понятия. Их подход к дистилляции напоминает скорее хирургическую операцию, чем грубую замену компонентов: вместо того чтобы пытаться переучить всю модель с нуля, они точечно сохранили самые ценные способности — сложные цепочки рассуждений. Это демонстрирует зрелость подхода к оптимизации больших моделей, когда эффективность достигается не за счет компромиссов, а через более глубокое понимание архитектурных ограничений.
Неочевидное открытие
Первоначальная гипотеза казалась логичной: использовать для дистилляции данные предварительного обучения, дополненные некоторым количеством SFT-данных. Логика была проста — новые линейные слои Mamba никогда не видели данных и должны научиться общему смешиванию токенов с нуля.
Но этот подход не сработал. Гибридные модели теряли качество рассуждений, иногда катастрофически.
Что сработало на самом деле: высококачественные трассы рассуждений из SFT-датасета учителя.
Дистилляция модели рассуждений — это не перенос общего предсказания следующего токена. Базовая модель уже обладает этой способностью. Что действительно нужно сохранить — это многошаговые паттерны рассуждений учителя.
Эти паттерны возникают из сложных механизмов внимания. Когда вы заменяете внимание целиком линейной рекуррентной моделью Mamba, эти вычислительные механизмы нарушаются. Гибрид должен найти новые пути к тем же результатам рассуждений.
Для этого требуются явные примеры, где структура рассуждений видна и корректна:
- Многошаговые математические доказательства
- Задачи программирования с четкими логическими зависимостями
- Научный анализ с детальными объяснительными цепочками
Данные предварительного обучения слишком зашумлены и разнородны. Сигнал рассуждений теряется. Нужны концентрированные примеры конкретной способности, которую вы пытаетесь сохранить.
Как это применять: поэтапная дистилляция
Простая замена 40 слоев внимания на Mamba не работает. Команда разработала поэтапную процедуру дистилляции для надежного достижения результата.
Этап 1: Определение наименее важных слоев
Использовался анализ «исключи-один» (Leave-One-Out) на MMLU: удаляли каждый слой, заменяли на идентичность, затем измеряли падение производительности. Сортировали по важности, заменяли нижние 25 слоев на микшеры Mamba-in-Llama (MIL) с инициализацией. Дистиллировали сквозным образом. Это сработало для контрольной точки H-25.
Этап 2: Прогрессивная конверсия за пределами 25 слоев
Анализ LOO перестал работать после 25 слоев, потому что слои, неважные по отдельности, становились критичными в комбинации. Для решения этой проблемы разработали динамическую эвристику MIL-Mamba-Replacement (MMR). Для каждого оставшегося слоя внимания инициализировали микшер Mamba с MIL, запускали 100 шагов обучения и записывали потери дистилляции. Слои, сходящиеся к меньшим потерям, было «легче» заменить.
Прогрессировали инкрементально: 25 → 27 → 30 → 34 → 37 → 40 слоев Mamba, группируя замены по оценкам MMR. Каждая контрольная точка дистиллировалась из предыдущей.
Этап 3: Сквозное обучение на SFT-данных
После достижения целевого количества слоев Mamba выполнили финальный проход SFT до стабилизации производительности рассуждений. После 55,9 миллиардов токенов дистилляции и 20,9 миллиардов SFT-токенов получили финальную модель Apriel-H1-15b-Thinker-SFT.
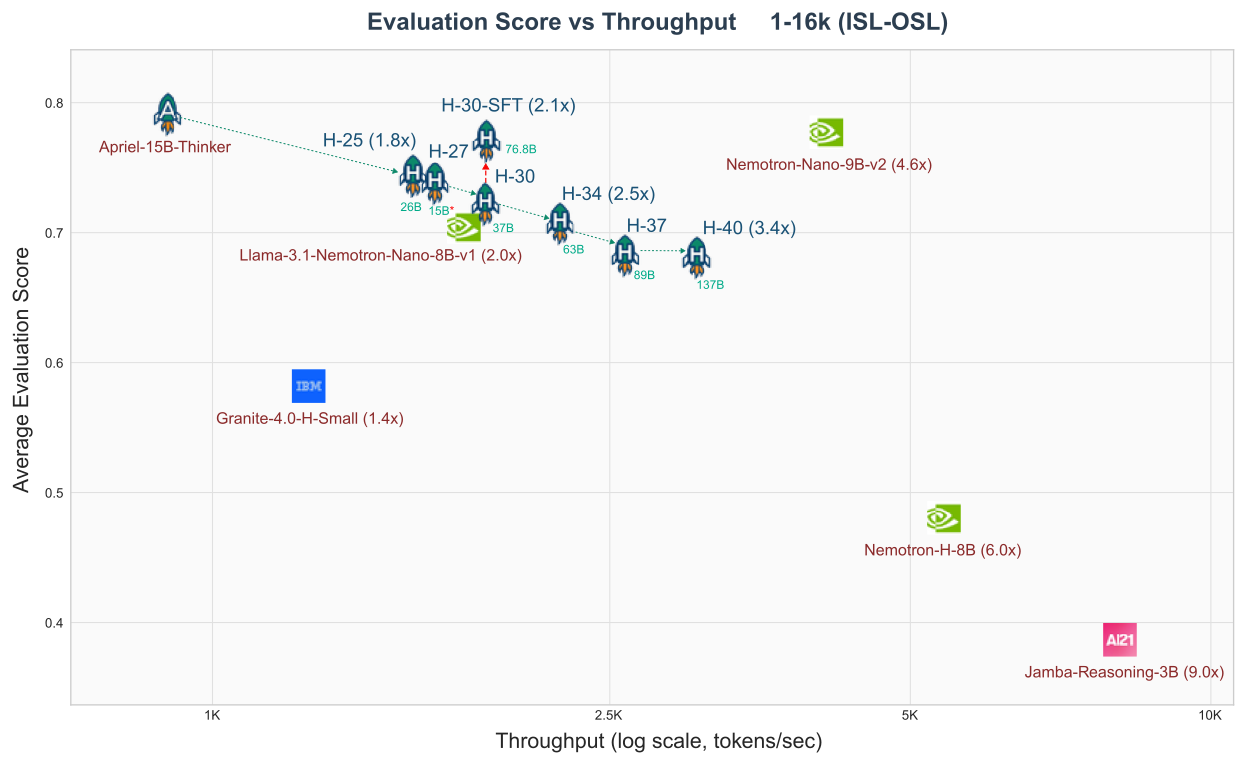
Полная граница эффективности. Каждая контрольная точка показывает кумулятивные токены обучения.
Это исследование демонстрирует, что эффективная архитектура — это не только выбор между вниманием и SSM, но и понимание того, какие данные использовать для передачи конкретных способностей.
По материалам Hugging Face.





Оставить комментарий