
Оглавление
По данным Scale AI, компания запустила SEAL Showdown — публичный рейтинг языковых моделей, основанный на оценках реальных пользователей из разных стран, возрастных групп и профессиональных сфер. Это первый подобный проект, который учитывает демографические различия вместо усредненных синтетических тестов.
Проблема традиционных бенчмарков
Современные рейтинги языковых моделей часто строятся на узкой выборке технических энтузиастов и синтетических тестах — головоломках по программированию, математических задачах. Они не отражают, как модели работают в повседневных сценариях у обычных пользователей. Ключевой недостаток — отсутствие контекста: кто оценивает модели, почему и с какими целями.
Чем отличается SEAL Showdown
Новый подход Scale основан на трех принципах:
- Глобальная репрезентативная выборка: данные собраны от миллионов пользователей из более чем 100 стран, говорящих на 70 языках и представляющих 200 профессиональных областей
- Детальная сегментация: можно увидеть, как модели работают для конкретных демографических групп — по возрасту, образованию, языку и региону
- Защита от накрутки: данные последних 60 дней не продаются и не передаются разработчикам, что предотвращает подгонку моделей под тесты
Что показали первые данные
Анализ предпочтений пользователей выявил интересные закономерности:
- Региональные различия: ChatGPT лидирует в Европе, в то время как Claude и ChatGPT делят первое место на других континентах. В Африке и Океании к ним присоединяется Gemini
- Языковой фактор: Gemini показывает лучшие результаты у неанглоязычных пользователей
- Возрастные предпочтения: ChatGPT популярен среди пользователей 30-50 лет, Claude и ChatGPT равны у 18-30 летних, а Gemini догоняет их у аудитории 50+
Наконец-то появляется инструмент, который показывает не абстрактные баллы на синтетических тестах, а реальную полезность моделей для разных групп пользователей. Особенно ценно, что система защищена от накруток — нельзя просто натренировать модель на конкретные тесты. Это заставляет разработчиков думать о реальной качестве, а не об оптимизации под метрики.
Как собираются данные
Рейтинги основаны на платформе Outlier, где пользователи добровольно сравнивают ответы разных моделей. Голосование полностью опционально — пользователи могут пропускать оценки, что обеспечивает более честные предпочтения без принуждения.
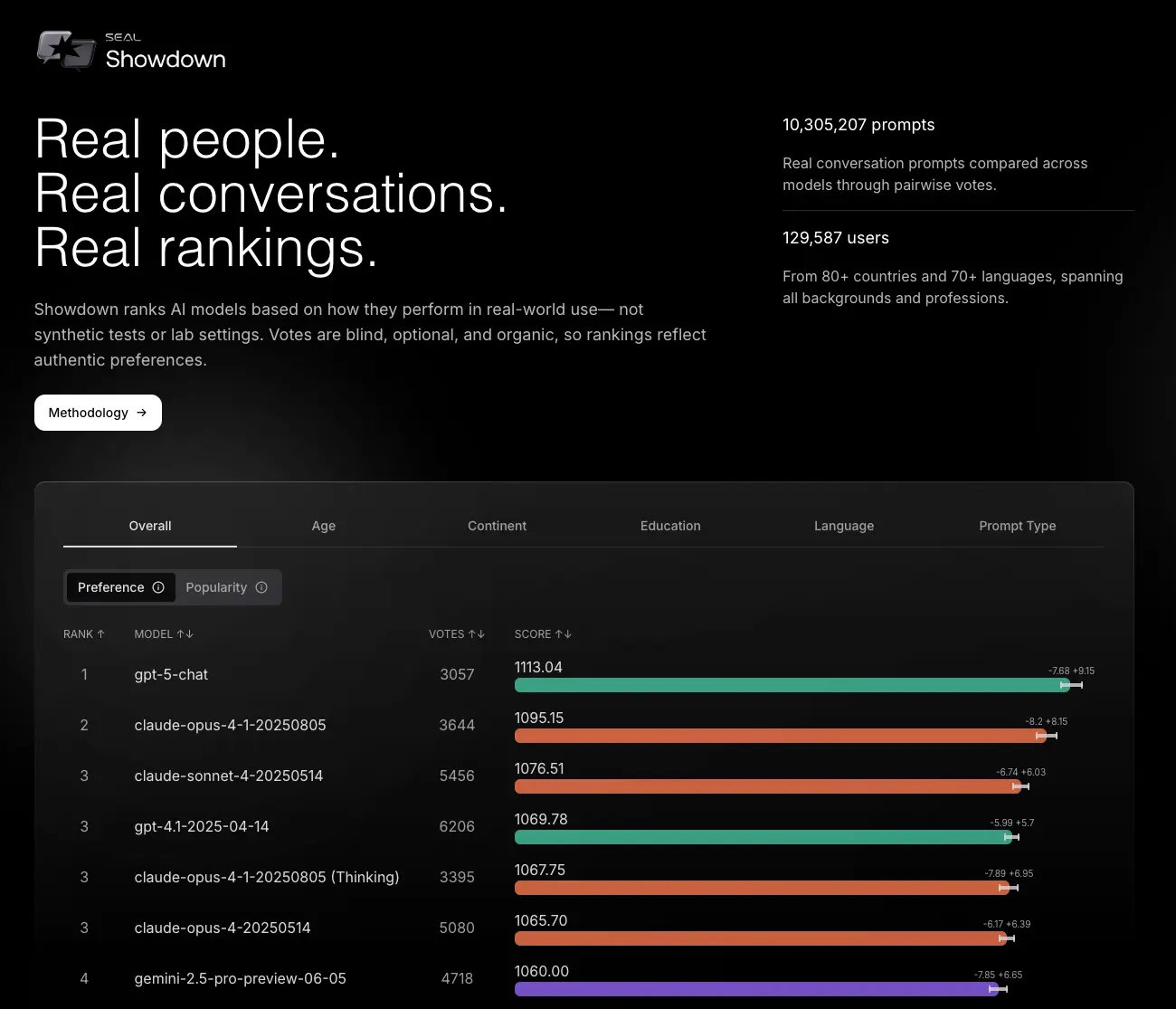
Новый стандарт для эпохи ИИ
SEAL Showdown устанавливает новый стандарт оценки языковых моделей — глобально репрезентативный, основанный на реальном использовании и защищенный от манипуляций. По мере развития экосистемы ИИ такие инструменты становятся критически важными для понимания, какие модели действительно работают для людей, а не просто показывают хорошие цифры на синтетических тестах.





Оставить комментарий