
Оглавление
Сообщает Hugging Face, что исследователь Майк Равкин представил революционный подход к тестированию языковых моделей, превращающий плоские метрики в трехмерные ландшафты когнитивных способностей.
Кризис традиционных бенчмарков
Традиционные системы оценки ИИ десятилетиями работали по принципу «черного ящика»: ввели запрос — получили ответ — поставили оценку. Но этот подход скрывает фундаментальную проблему: сам формат тестирования вводит в заблуждение.
Когда модель показывает результат в 73.2%, что это на самом деле означает? Она стабильно средняя во всем? Легко справляется с простыми задачами и проваливает сложные? Добавление одного элемента в список вызывает плавную деградацию или катастрофический коллапс? Традиционные бенчмарки не дают ответов на эти вопросы.
Это похоже на попытку измерить высоту горы одним числом, игнорируя все склоны, обрывы и плато. Мы десятилетиями довольствовались такими измерениями, пока не осознали, что пропускаем самое интересное — архитектуру мышления моделей.
Трехмерное измерение мышления
Вместо единого теста «может ли модель отсортировать список?» система ReasonScape использует параметрические тесты: «может ли она отсортировать список длины N с мутациями регистра C?» Каждая задача превращается в функцию с несколькими осями сложности, генерирующую детерминированные тестовые случаи.
Результат — не одно число, а полноценный ландшафт сложности: трехмерная поверхность, показывающая, как именно меняется производительность при варьировании параметров.
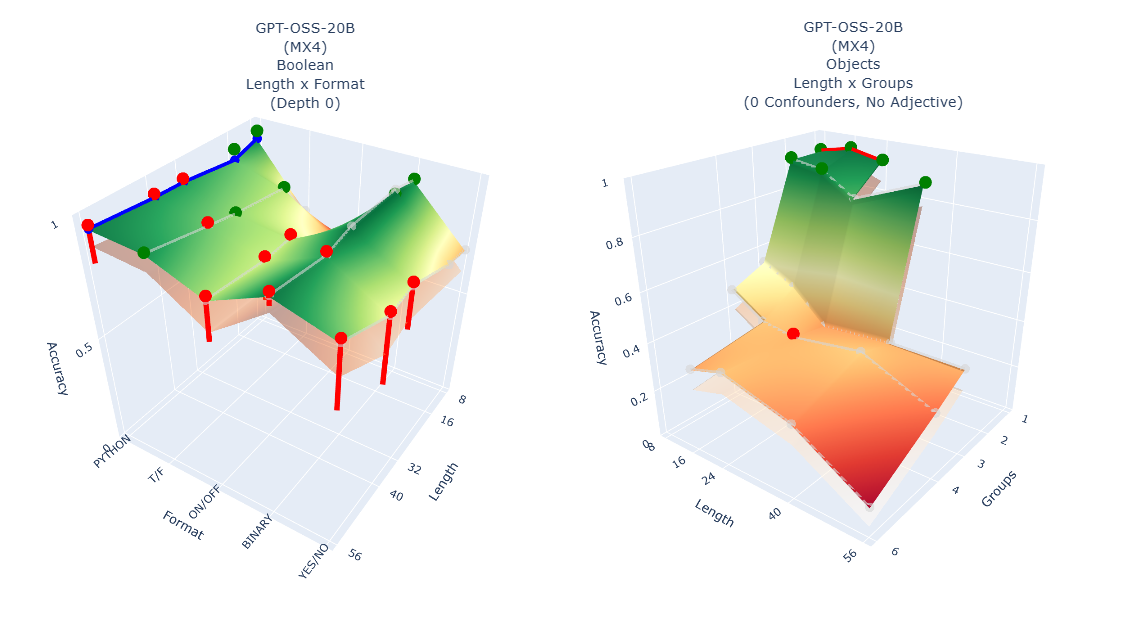
Некоторые модели демонстрируют резкие обрывы — добавление одной вложенной скобки вызывает катастрофическое падение точности. Другие показывают плавные кривые деградации. Одни преуспевают в коротких, но глубоких задачах, другие предпочитают длинные и поверхностные. Некоторые модели безразличны к формату булевых выражений, тогда как другие демонстрируют явные предпочтения.
Спектральный анализ мышления
Самый неожиданный прорыв произошел, когда исследователь применил методы обработки сигналов к задачам рассуждений. Проблемы — это просто последовательности токенов, а последовательности можно анализировать в частотной области.
Быстрое преобразование Фурье для пост-токенизированных потоков данных сработало чрезвычайно хорошо.
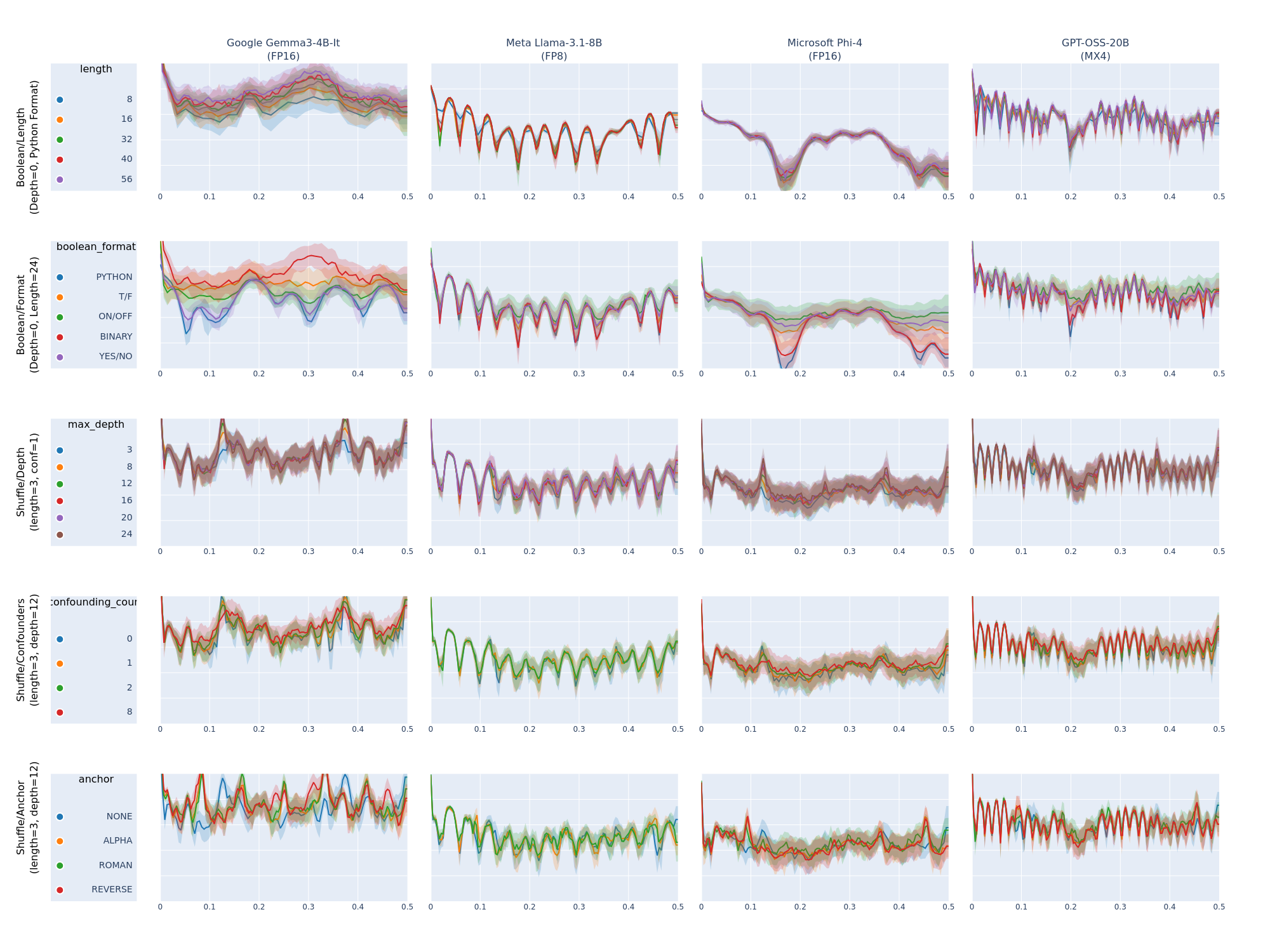
Разные типы задач рассуждений имеют уникальные спектральные сигнатуры. Математические выражения показывают высокочастотные компоненты от повторяющихся операторов, задачи естественного языка демонстрируют характерные низкочастотные паттерны грамматической структуры.
Более того: разные архитектуры моделей показывают уникальные спектральные характеристики в представлении идентичных проблем. Взаимодействие шаблонов чата и токенизации создает архитектурные различия в частотной области.
M12X: двенадцать измерений интеллекта
Из первоначального «протестируем несколько задач» выросла полноценная система M12X: двенадцать когнитивных доменов, три степени сложности, настраиваемая плотность выборки и регулируемые уровни точности.
Домены охватывают весь спектр когнитивных способностей:
- Математика и логика (арифметика, булева алгебра)
- Язык и избирательное внимание (объекты, буквы, фильмы)
- Пространственное и временное мышление (фигуры, даты, автомобили)
- Структурный парсинг (скобки, сортировка, последовательности)
- Отслеживание состояния и планирование (перемешивание, автомобили)
Каждый домен имеет тщательно спроектированные параметрические генераторы, создающие многообразия сложности — непрерывные поверхности, где можно плавно изменять уровень сложности и наблюдать, где и как ломаются модели.
Статистическая строгость как необходимость
С параметрическими тестами, генерирующими тысячи образцов по нескольким измерениям сложности, статистическая строгость перестала быть опцией и стала экзистенциальной необходимостью.
Система включает:
- Коррекцию избыточной точности для бинарных, множественных и письменных вопросов
- Доверительные интервалы Уилсона с учетом усечения
- Динамическую выборку, продолжающую генерацию тестов до достижения порогов значимости
- Иерархическую выборку, где меньшие выборки являются идеальными подмножествами больших
Последний пункт особенно изящен: каждый тест генерируется из координат в многообразии сложности. Нужно больше образцов? Просто расширьте последовательность. Нужно уменьшить выборку? Возьмите первые N случаев.
В мире, где модели рассуждений сжигают 5000+ токенов на тестовый случай, этот подход к кэшированию всего сэкономил примерно один RTX 4090 в пересчете на затраты электроэнергии. Иногда самые элегантные решения оказываются и самыми практичными.
Датасет, поглотивший жизнь
На момент публикации датасет M12X содержит:
- 41 уникальную модель (и продолжает расти)
- 2+ миллиона индивидуальных тестов
- 5.5+ миллиардов токенов ответов моделей
- Полные ландшафты сложности по всем 12 доменам
- Данные спектрального анализа для каждого тестового случая
- Полное кэширование ответов
ReasonScape представляет собой не столько систему оценки, сколько фреймворк исследования для зондирования как глубины, так и широты возможностей моделей рассуждений. Это переход от измерения высоты гор к созданию полных топографических карт когнитивных ландшафтов.





Оставить комментарий