
Оглавление
Разработчики PyTorch объявили о создании единого фреймворка для разреженного вывода, который обещает революцию в эффективности работы больших языковых моделей. По сообщению PyTorch, новая технология позволяет достигать ускорения в 2-6 раз при минимальной потере точности.
Новая эра оптимизации LLM
Эпоха низкоточного квантования подходит к концу — на смену приходит разреженность. Исследования показывают, что в моделях типа OPT от Meta* до 99% весов в MLP-блоках остаются неактивными при обработке типичных входных данных.
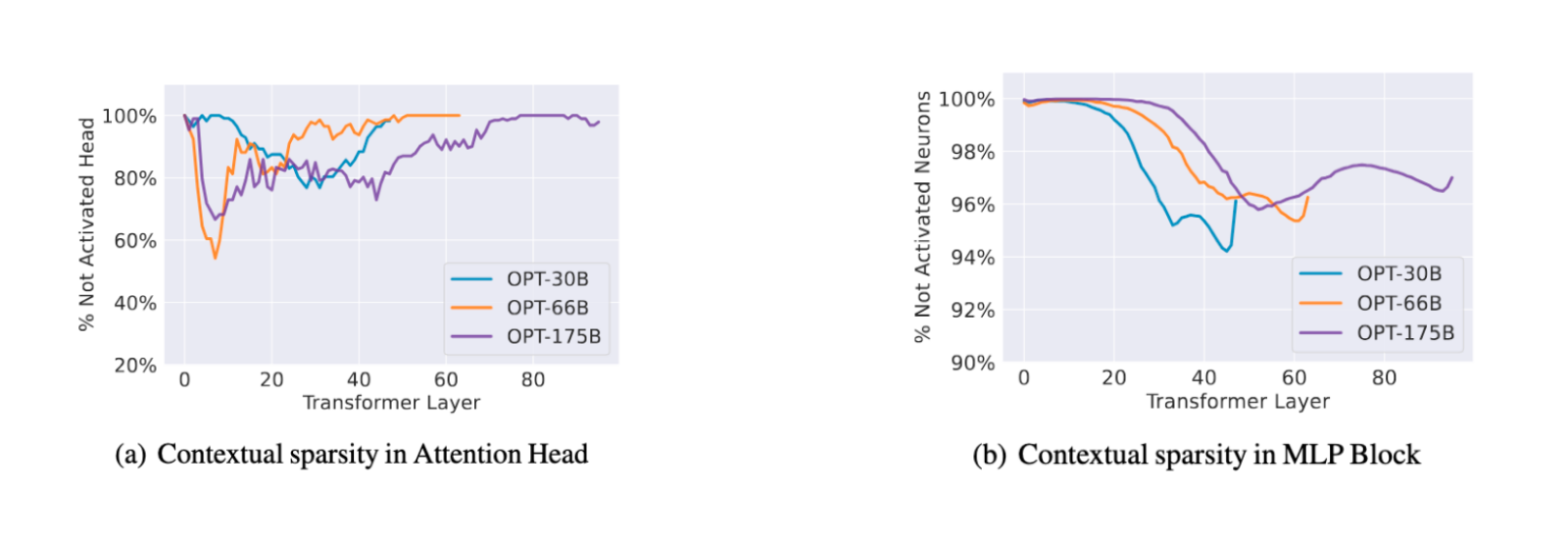
Технология «Deja Vu» использует низкоранговые предикторы для предварительного вычисления разреженных индексов, что позволяет избежать вычислений с неактивными нейронами. Асинхронное выполнение слоев-предикторов дополнительно снижает задержки.
Проблемы современных активационных функций
Современные модели вроде Llama, Mistral и Gemma перешли от ReLU к более плавным активационным функциям — SiLU и GeLU. Эти функции не обнуляют отрицательные входы, создавая «длинные хвосты», что резко снижает уровень разреженности активаций.
Наивное пороговое отсечение теперь приводит к значительной потере точности, требуя более изощренных подходов.
Два подхода к восстановлению разреженности
- Релюфикация: Замена SiLU/GeLU на ReLU с последующим дообучением. Позволяет достичь 60-90% разреженности с минимальной потерей точности
- Бездоуровневое пороговое отсечение: Методы CATS и CETT вычисляют оптимальные пороги на основе калибровочных данных, восстанавливая >60% разреженности без переобучения
Оптимизация выполнения разреженных операций
Наивная реализация разреженных операций сталкивается с узким местом памяти из-за постоянных операций index_select. Команда PyTorch разработала оператор кэширования весов, который сохраняет активные веса в кэше и загружает только разницу между последовательными масками.
Предварительные эксперименты показывают ускорение операций index_select в 6.7 раз и до 5-кратного ускорения MLP-вывода на CPU.
Разреженность перестает быть хаком оптимизации и становится архитектурной особенностью. То, что начиналось как трюк для ускорения инференса, теперь встраивается в сами модели — DeepSeek v3.2 и Google Gemma 3-n уже демонстрируют это. Ирония в том, что мы возвращаемся к идеям, которые были популярны десятилетия назад, но теперь с современным аппаратным обеспечением и пониманием transformer-архитектур.
Новые архитектурные решения
DeepSeek v3.2 внедряет DeepSeek Sparse Attention (DSA) с «молниеносным индексером» — легковесным предиктором, который сокращает контекстное окно с 100k токенов до фиксированного среза в 2048 токенов.
Google Spark Transformer предлагает альтернативный подход с разреженными предикторами как для внимания, так и для feed-forward слоев.
Эти разработки знаменуют переход от постобработки к архитектурному дизайну, где разреженность становится фундаментальным свойством, а не оптимизацией после факта.
* Meta (признана экстремистской и запрещена в РФ)





Оставить комментарий