
PyTorch сообщает что новая версия фреймворка 2.8 приносит революционные улучшения в производительности квантованных языковых моделей на CPU Intel. Теперь разработчики могут достигать сравнимой или даже лучшей производительности по сравнению с популярным фреймворком vLLM, используя исключительно нативный стек PyTorch.
Технические детали оптимизации
В PyTorch 2.8 были включены и оптимизированы распространенные конфигурации квантования для языковых моделей на процессорах Intel Xeon, включая A16W8, DA8W8 и A16W4. При использовании torch.compile в квантованной модели система автоматически преобразует шаблоны квантованных матричных умножений (GEMM) в высокопроизводительные ядра на основе шаблонов с максимальным автотюнингом в Inductor.
Это позволяет задействовать возможности Intel AMX и Intel AVX-512 для ускорения обработки. Как показывают тесты с моделью Llama-3.1-8B, производительность нативного стека PyTorch достигает того же уровня или даже превосходит vLLM в офлайн-режиме на одиночном вычислительном узле с CPU Intel Xeon.
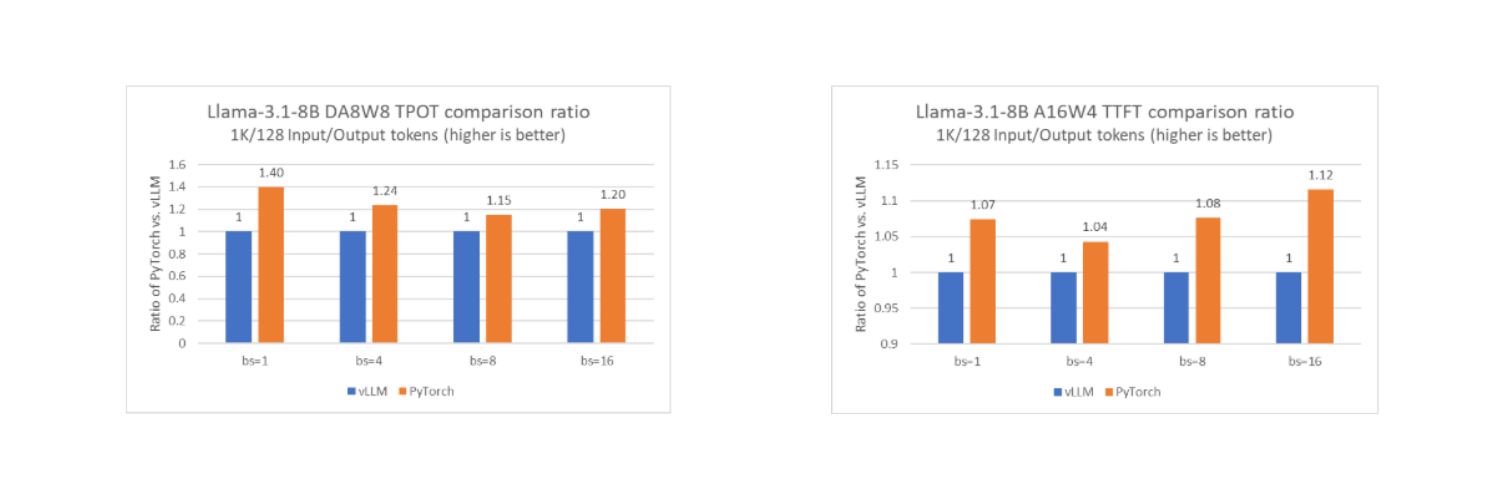
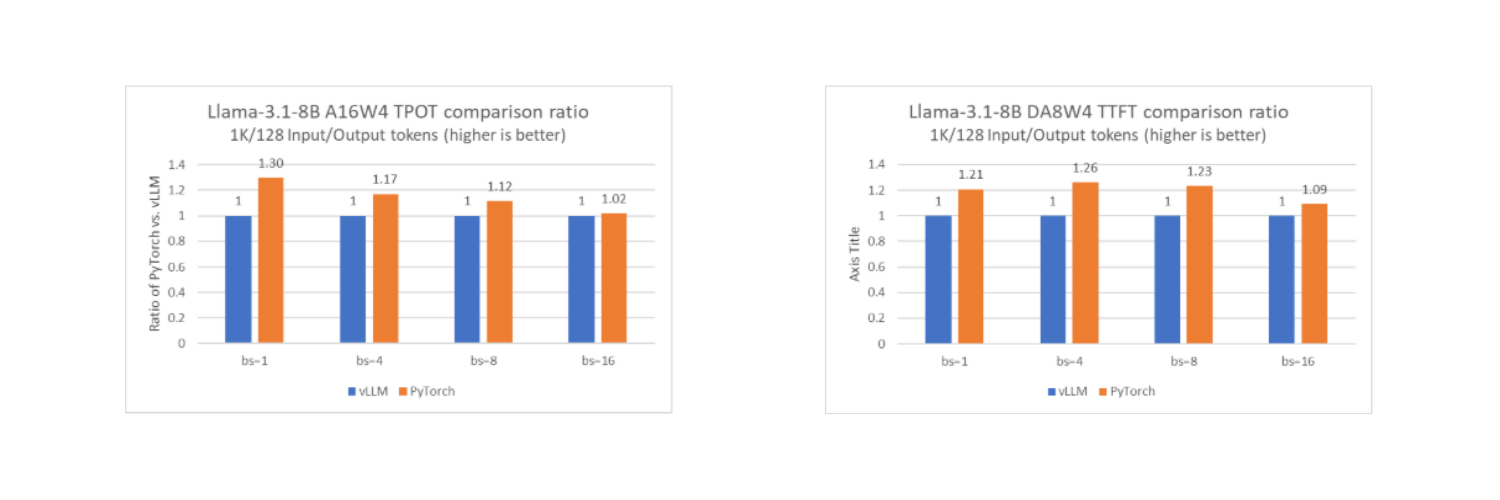
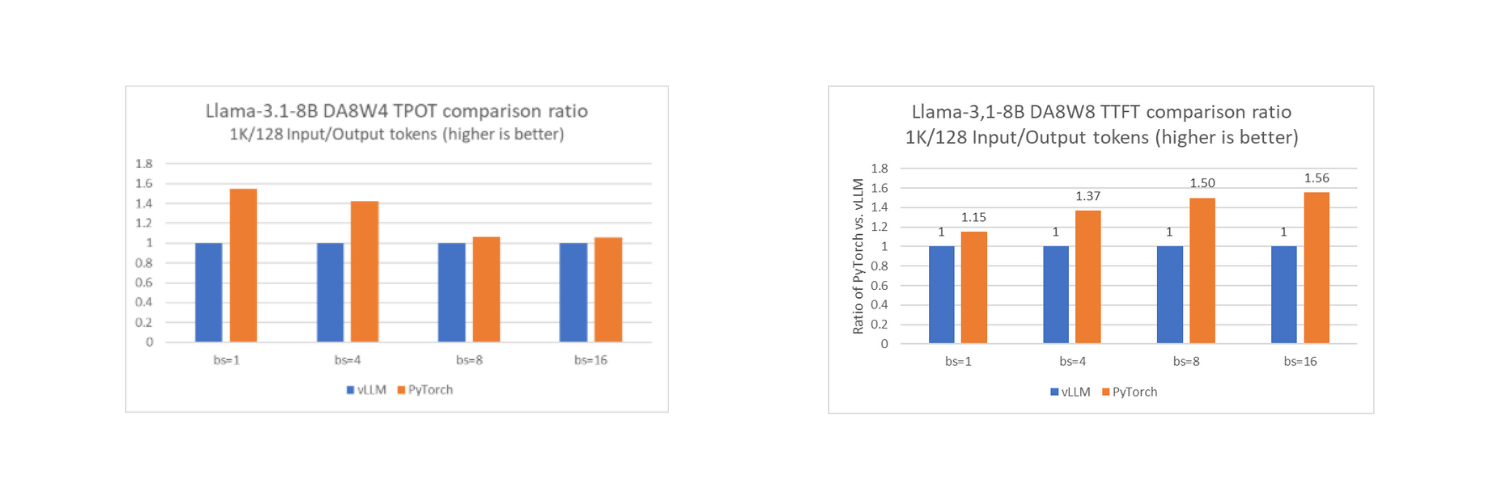
Простота использования
Для получения максимальной производительности пользователям достаточно выполнить несколько простых шагов:
- Выбрать машину с x86 CPU с поддержкой AMX
- Квантовать модель с помощью методов Torchao
- Установить несколько флагов для torch.compile
- Скомпилировать модель с torch.compile
Пример кода для настройки:
# 1. Set torch.compile flags from torch._inductor import config as inductor_config inductor_config.cpp_wrapper = True inductor_config.max_autotune = True inductor_config.cpp.enable_concat_linear = True inductor_config.cpp.use_small_dequant_buffer = True # 2. Get model model = transformers.AutoModelForCausalLM.from_pretrained(<model_id>, ...) # 3. Quantization with Torchao from torchao.quantization.quant_api import ( quantize_, Int8DynamicActivationInt8WeightConfig, Int4WeightOnlyConfig, Int8DynamicActivationInt4WeightConfig, ) ## 3.1 DA8W8 quantize_( model, Int8DynamicActivationInt8WeightConfig(set_inductor_config=False) ) # 4. Apply optimizations with torch.compile model.forward = torch.compile(model.forward)
Наконец-то разработчики получают альтернативу специализированным фреймворкам вроде vLLM без необходимости изучать новые инструменты. Интеграция квантования прямо в PyTorch — это именно то, что нужно экосистеме: единый стек вместо зоопарка технологий. Особенно впечатляет, что оптимизации работают автоматически — достаточно выставить правильные флаги, а дальше магия компилятора делает своё дело.
Перспективы развития
Текущая оптимизация работает на одиночном устройстве с Intel Xeon, но в планах — поддержка распределенных вычислений на нескольких платформах. Это откроет возможности для использования продвинутых функций вроде Tensor Parallel.
Разработчики благодарят сообщество за глубокое сотрудничество и вклад в развитие платформы, отмечая особую роль участников проекта в достижении этих результатов.





Оставить комментарий