
Оглавление
В мире больших языковых моделей, где обучение требует колоссальных вычислительных ресурсов, методы параметрически эффективной тонкой настройки (PEFT) становятся ключевым инструментом для адаптации моделей к конкретным задачам без необходимости переобучать миллиарды параметров.
Что такое PEFT и зачем он нужен
PEFT (Parameter-Efficient Fine-Tuning) — это набор методов, которые позволяют адаптировать большие языковые модели более эффективно с точки зрения памяти и вычислительной производительности. Основанные на исследовании «Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning» и библиотеке PEFT, интегрированной с Hugging Face Transformers, эти подходы открывают возможности тонкой настройки моделей для организаций с ограниченными ресурсами.
PEFT — это не просто способ сэкономить на железе, а фундаментальный сдвиг в подходе к кастомизации моделей. Вместо тотального переобучения мы учимся точечно вмешиваться в архитектуру, сохраняя при этом способности модели к обобщению. Похоже на хирургическую операцию вместо химиотерапии — минимальное вмешательство, максимальный эффект.
Категории методов PEFT
Методы эффективной тонкой настройки можно классифицировать по двум основным аспектам: их концептуальной структуре и основной цели — минимизация использования памяти, улучшение эффективности хранения или снижение вычислительных затрат.
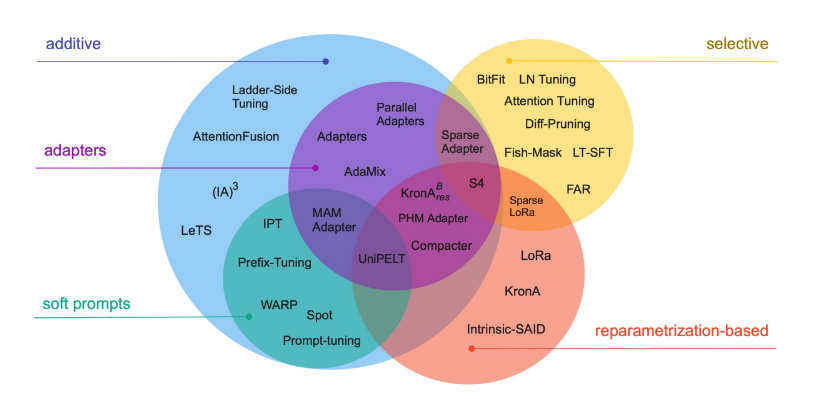
Все методы делятся на три широкие категории:
Аддитивные методы
Аддитивные методы вводят новые параметры в базовую модель, обычно через небольшие адаптерные слои или корректировку части входных эмбеддингов (известных как мягкие промпты). К ним относятся:
- Адаптеры: Малые плотные сети, вставляемые после определенных подслоев трансформера, позволяющие адаптироваться к новым задачам без необходимости обучать все параметры модели
- Мягкие промпты: Тонкая настройка, применяемая непосредственно к входным эмбеддингам модели, позволяющая адаптацию к конкретным задачам без изменения внутренних параметров модели
Эти методы обычно эффективны с точки зрения памяти, так как уменьшают размер градиентов и состояний оптимизатора.
Селективные методы
Селективные методы корректируют только часть существующих параметров модели. Это может быть сделано несколькими способами:
- Тонкая настройка верхних слоев: Фокусировка только на верхних слоях сети при замороженных нижних слоях
- Тонкая настройка конкретных параметров: Выборочное обучение определенных типов параметров, таких как смещения
- Разреженные обновления: Выбор конкретного подмножества параметров для обучения
Несмотря на уменьшение количества обучаемых параметров, селективные методы могут требовать высоких вычислительных затрат, особенно в разреженных конфигурациях.
Методы на основе репараметризации
Методы на основе репараметризации уменьшают количество обучаемых параметров за счет использования низкоранговых представлений, используя избыточность, присутствующую в нейронных сетях. Ключевые методы включают:
- LoRA (Low-Rank Adaptation): Использует низкоранговое матричное разложение для представления обновлений весов
- Intrinsic SAID: Использует преобразование Fastfood для эффективного представления низкоранговых обновлений
Эти методы значительно сокращают количество параметров, которые нужно обучать, делая их идеальными для сценариев, где важна эффективность хранения и времени обучения.
Сравнительная таблица методов
| Метод | Тип | Хранение | Память | Обратное распространение | Накладные расходы инференса |
|---|---|---|---|---|---|
| Adapters (Houlsby et al., 2019) | A | да | да | нет | Extra FFN |
| AdaMix (Wang et al., 2022) | A | да | да | нет | Extra FFN |
| SparseAdapter (He et al., 2022b) | AS | да | да | нет | Extra FFN |
Практическое применение PEFT методов демонстрируется в ноутбуке, где выполняется тонкая настройка модели для суммаризации разговоров службы поддержки с использованием полной тонкой настройки, LoRA, QLoRA и IA3.
По материалам Hugging Face.





Оставить комментарий