
Оглавление
Международная олимпиада по информатике (IOI) давно считается эталонным тестом для оценки способностей языковых моделей к алгоритмическому мышлению и решению задач. Впервые открытая модель смогла достичь уровня золотой медали в этом престижном соревновании, работая в тех же условиях, что и человеческие участники — с ограничением в 50 попыток на задачу и стандартными временными рамками.
Технологический прорыв с открытыми моделями
Модель gpt-oss-120b показала результат в 446,75 баллов на IOI 2025, преодолев порог золотой медали в 438,3 балла. Этот успех стал возможен благодаря фреймворку GenCluster — масштабируемому конвейеру для тестовых вычислений, который эффективно отбирает наиболее перспективные решения из тысяч сгенерированных вариантов.
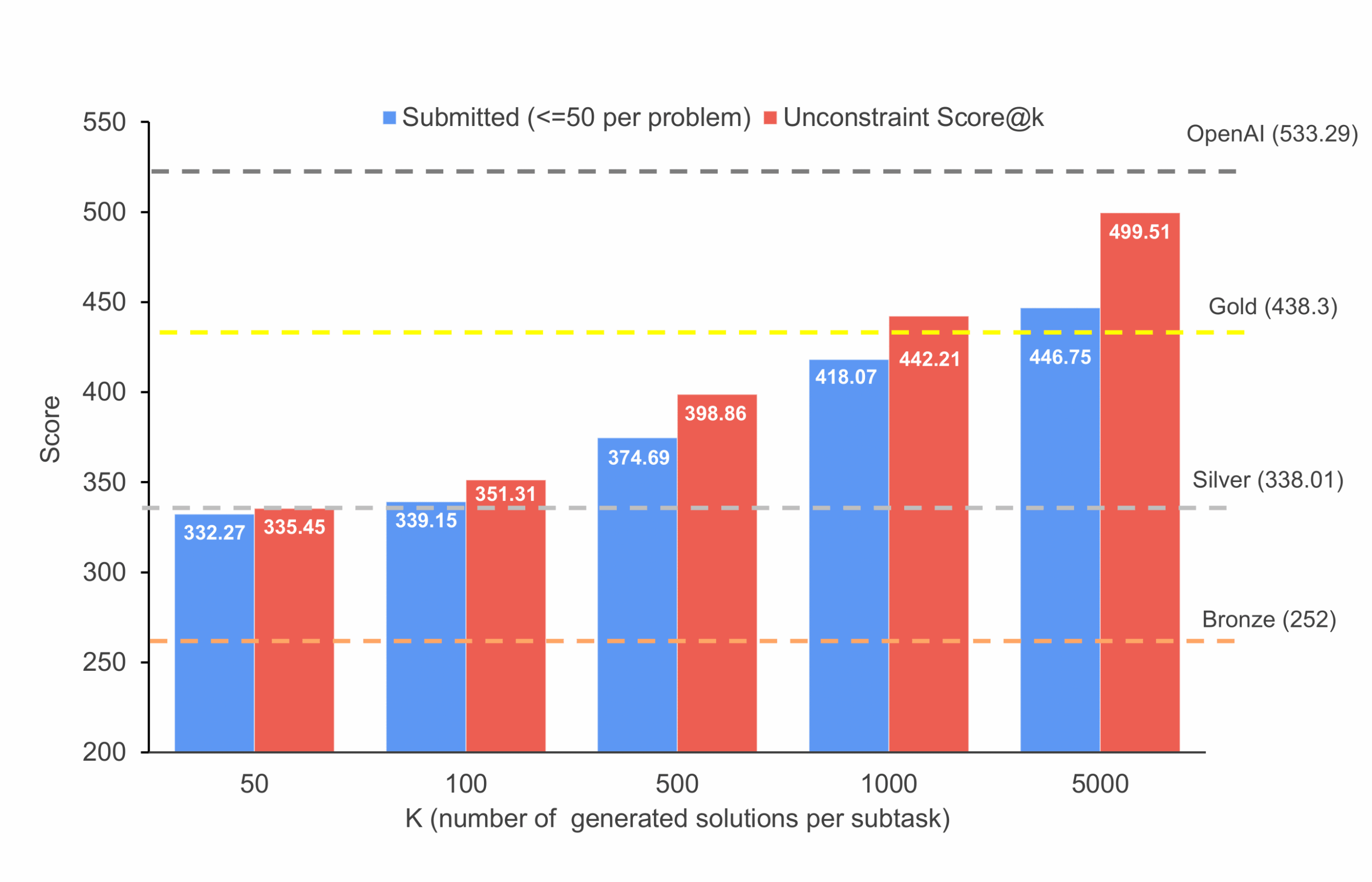
Исследователи обнаружили четкую закономерность: увеличение пула кандидатов последовательно улучшает результаты как при ограниченных, так и при неограниченных условиях. Это демонстрирует преимущества масштабирования тестовых вычислений в сочетании с GenCluster.
Похоже, что «грубая сила» в виде массовой генерации решений начинает побеждать элегантность алгоритмического мышления. Интересно, не станет ли это трендом в соревновательном программировании — вместо поиска одного идеального решения генерировать тысячи вариантов и выбирать лучший?
Как работает GenCluster
Фреймворк работает в четыре этапа, методично анализируя тысячи кандидатов для выявления наиболее перспективных решений при ограниченном количестве финальных проверок.
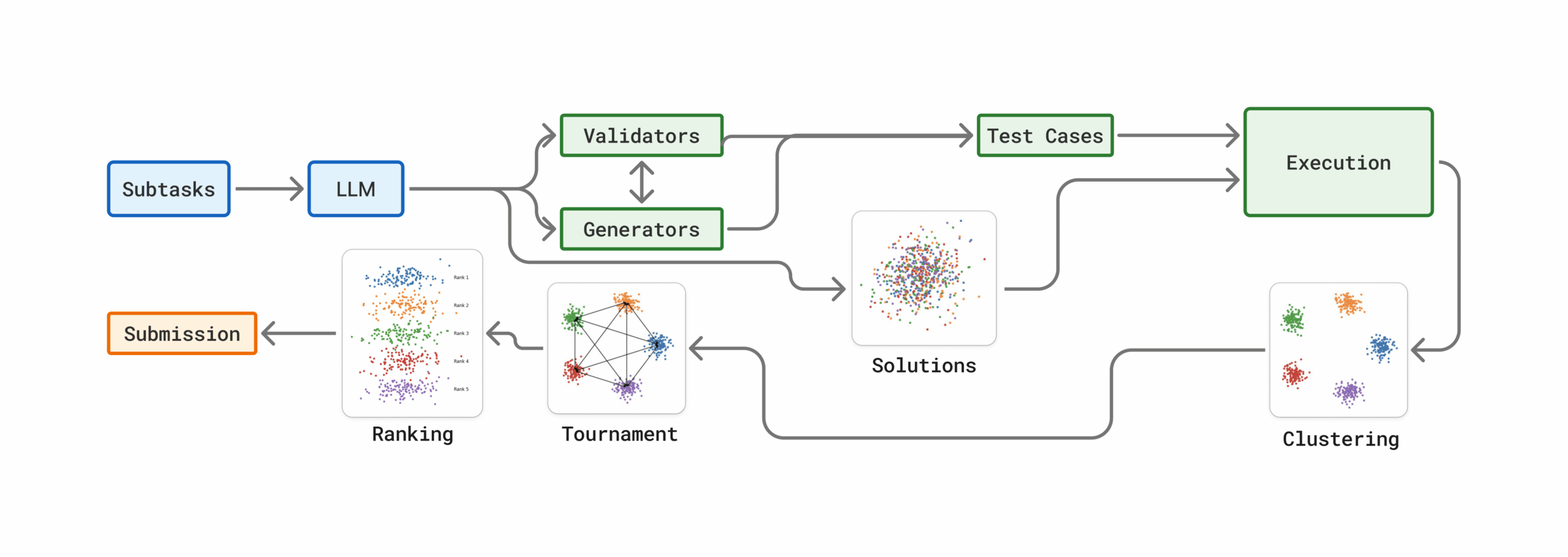
Параллельная генерация кандидатов
На первом этапе система генерирует тысячи потенциальных решений для каждой задачи параллельно. Вместо ожидания одного идеального ответа GenCluster исследует большой и разнообразный пул возможностей, увеличивая шансы на появление хотя бы одного правильного решения.
Поведенческое кластерирование
Далее решения группируются на основе их поведения. Каждый кандидат проверяется на наборе тестовых случаев, сгенерированных языковой моделью, и в один кластер попадают решения с идентичными выходными данными. Это преобразует хаос тысяч индивидуальных решений в управляемый набор различных стратегий решения задач.
Ранжирование через турнир
Для определения лучшей стратегии проводится турнир. Представитель от каждого кластера соревнуется в парных противостояниях, оцениваемых языковой моделью. Кластеры ранжируются по количеству побед, позволяя наиболее перспективным стратегиям подняться наверх.
Стратегия отправки
Наконец, применяется стратегия циклической отправки для максимального использования строгого лимита в 50 попыток на задачу. Решения из топовых кластеров отправляются одно за другим, начиная с самых сложных подзадач. Внутри каждого кластера решения ранжируются и выбираются по длине цепочки рассуждений.
Сравнение открытых моделей
Исследователи оценили несколько ведущих открытых моделей на бенчмарках соревновательного программирования и обнаружили, что gpt-oss-120b достиг наивысшего результата с значительным отрывом. Это единственная модель с потенциалом достижения уровня золотой медали при масштабировании до 5000 генераций на задачу.
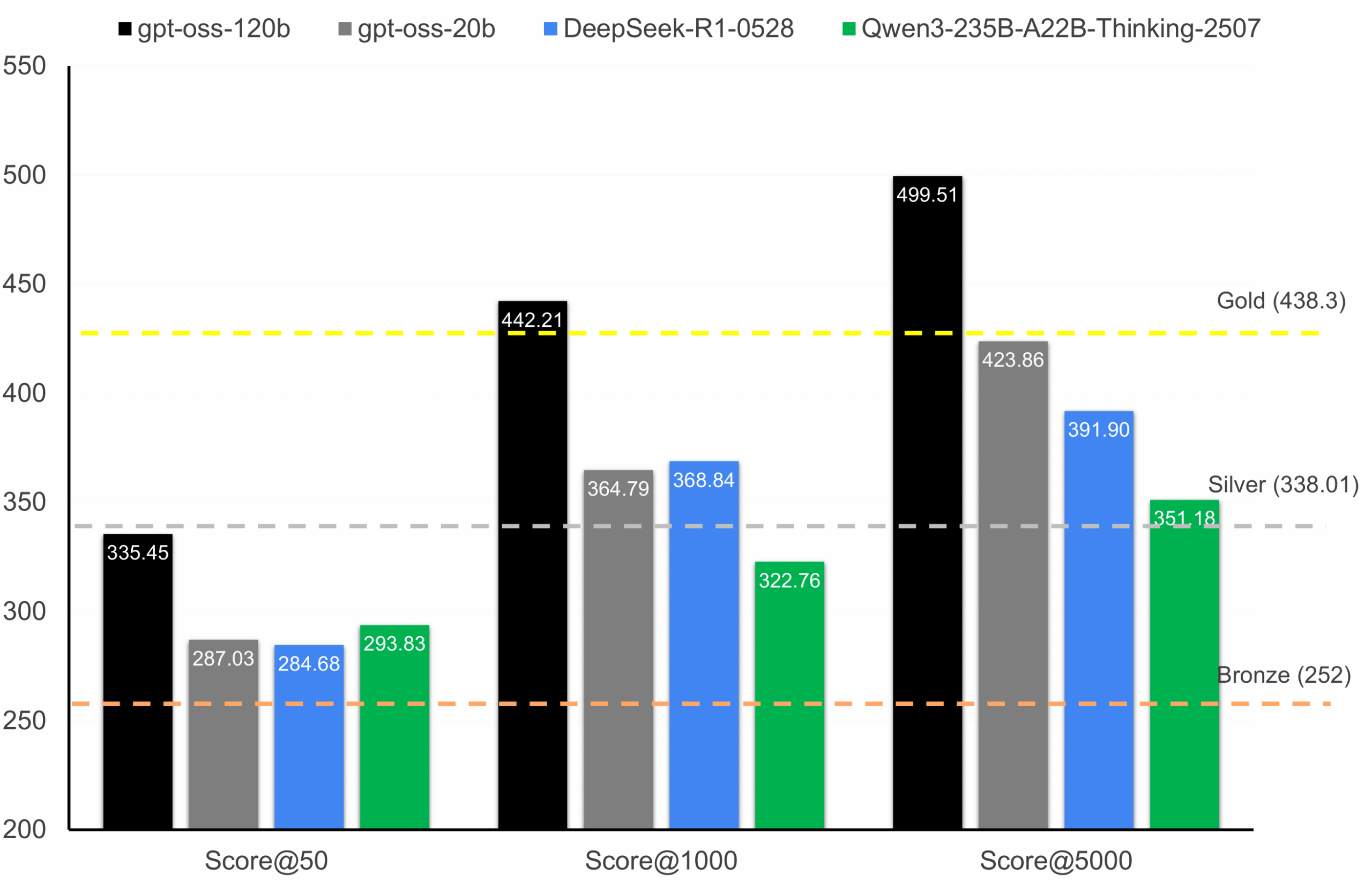
Более того, семейство gpt-oss демонстрирует более сильный рост производительности по мере увеличения количества генераций, что свидетельствует о более эффективном масштабировании с тестовыми вычислениями. В отличие от этого, хотя Qwen3-235B-A22B превосходит gpt-oss-20b и DeepSeek-R1-0528 при меньших вычислительных бюджетах, его производительность масштабируется менее благоприятно при больших объемах.
Влияние максимального количества токенов
Предыдущие исследования показали, что более длинные цепочки рассуждений часто коррелируют с более высокой точностью на сложных задачах, и наши результаты подтверждают эту тенденцию. При варьировании максимальной длины генерации модели gpt-oss продолжали улучшаться вплоть до своих лимитов токенов, в то время как Qwen3-235B-A22B выходил на плато около 48K токенов — значительно ниже рекомендуемых авторами 80K.
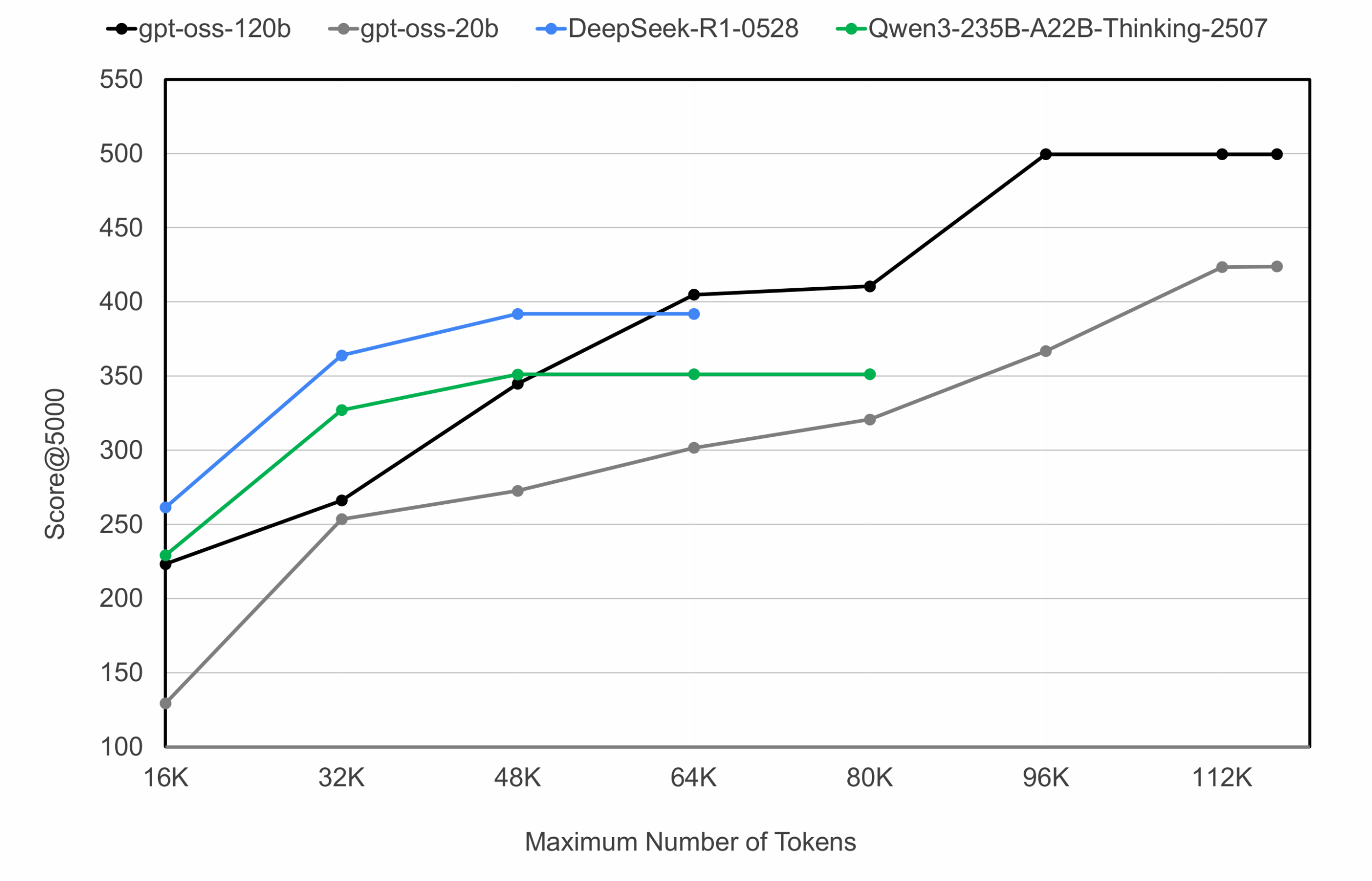
Интересно, что модели gpt-oss не только производили более длинные и детализированные пути рассуждений, но и демонстрировали самую высокую общую производительность, превосходя DeepSeek-R1-0528 и Qwen3-235B-A22B при применении больших вычислительных бюджетов.
Перспективы для исследований
Результаты демонстрируют, что открытые модели в сочетании с масштабируемым фреймворком тестовых вычислений могут приблизиться к производительности ведущих закрытых систем на бенчмарке IOI. Вводя полностью воспроизводимый конвейер, построенный исключительно на открытых весах, исследователи стремятся сделать передовые исследования в области рассуждений более прозрачными, доступными и проверяемыми.
Эта работа открывает путь к использованию тестовых вычислений как средства дальнейшего масштабирования открытых моделей и расширения границ алгоритмического решения задач.
Сообщает Hugging Face.





Оставить комментарий