Оглавление
Эффективная обработка множественных параллельных запросов становится критически важной для производительности приложений на основе больших языковых моделей. Как пишет Hugging Face, инженеры TNG провели глубокий анализ работы LLM под нагрузкой, выявив ключевые механизмы оптимизации.
Две фазы генерации токенов: Prefill и Decode
Большинство языковых моделей генерируют текст токен за токеном, гарантируя, что каждый новый токен вычисляется на основе всех предыдущих (это свойство называется авторегрессивностью).
Первый выходной токен зависит от всех токенов промпта, но второй выходной токен уже зависит от всех токенов промпта плюс первого выходного токена, и так далее.
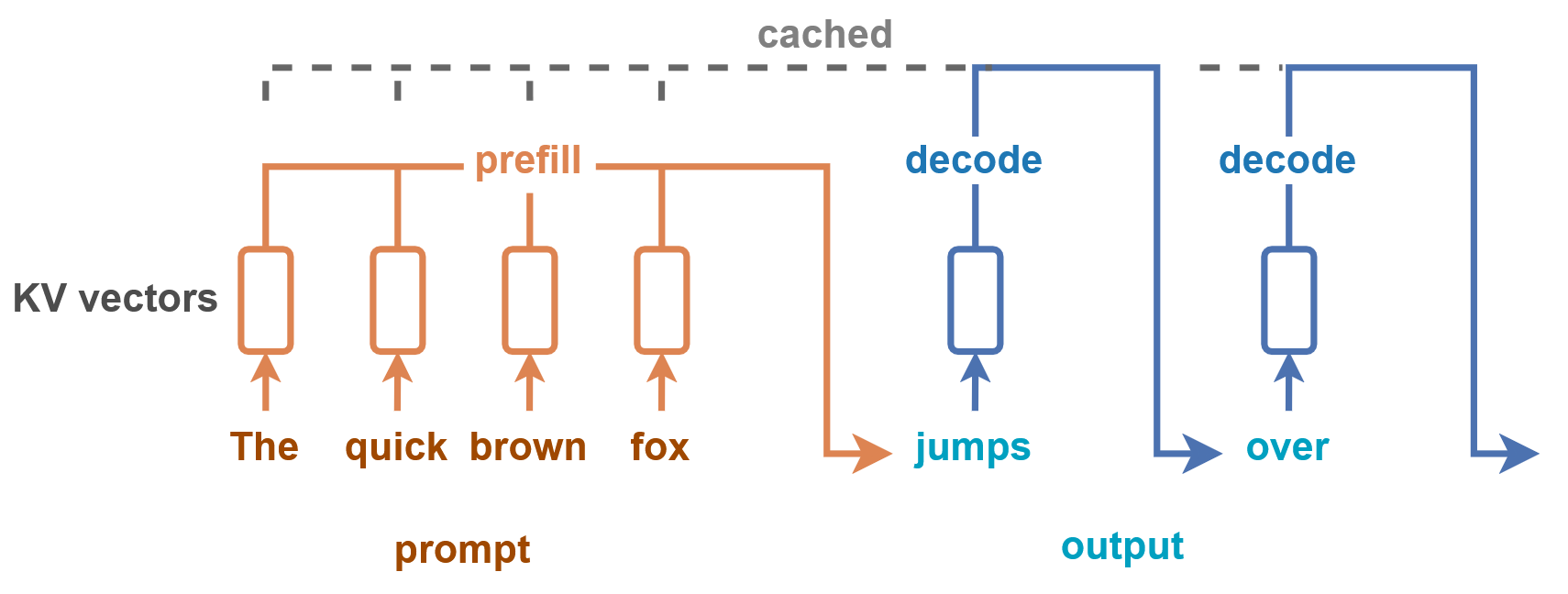
В LLM с механизмами внимания вычисление нового токена требует расчета векторов ключа, значения и запроса для каждого предыдущего токена. К счастью, результаты некоторых вычислений могут повторно использоваться для последующих токенов. Эта концепция известна как кэш ключ-значение (KV-cache).
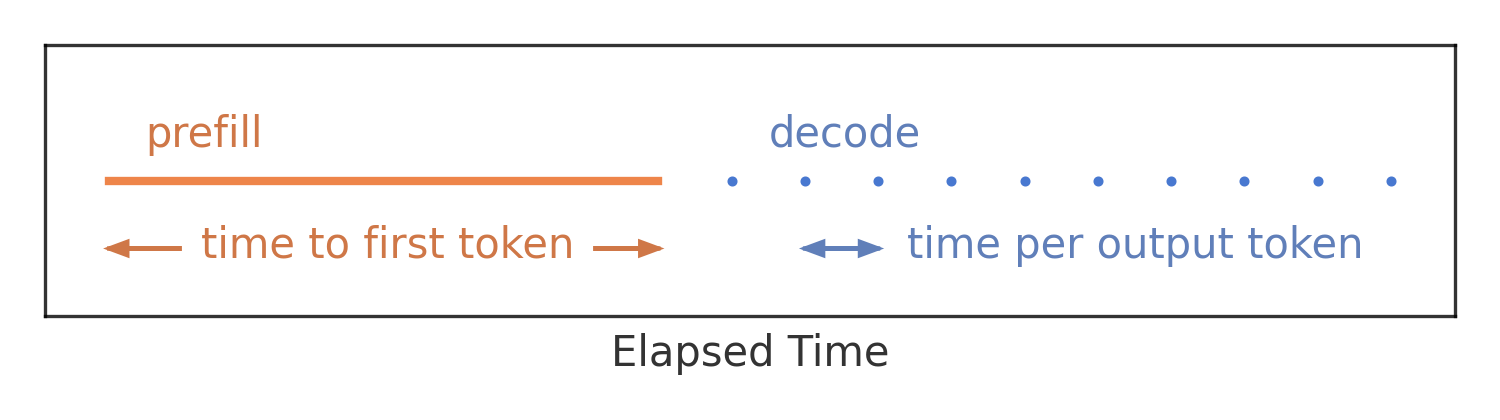
Для каждого дополнительного выходного токена нужно вычислять только один дополнительный набор векторов ключа и значения. Однако для самого первого выходного токена мы начинаем с изначально пустого KV-кэша и должны вычислить столько наборов векторов ключа и значения, сколько есть токенов во входном промпте.
Это различие мотивирует разделение на фазу предзаполнения (вычисление первого выходного токена) и фазу декодирования (вычисление любого последующего выходного токена).
Метрики производительности
Различие между фазами предзаполнения и декодирования также отражается в двух ключевых метриках для генерации текста: Время до первого токена и Время на выходной токен.
Время до первого токена определяется задержкой фазы предзаполнения, в то время как время на выходной токен — это задержка одного шага декодирования. Хотя фаза предзаполнения также генерирует только один токен, она занимает гораздо больше времени, чем один шаг декодирования, потому что все входные токены должны быть обработаны.
Обе задержки являются важными метриками для интерактивных приложений, таких как чат-бот. Если пользователям приходится ждать более 5 секунд перед тем, как они увидят ответ, они могут подумать, что приложение не работает, и уйти. Типичные целевые показатели задержки для интерактивных приложений составляют 100-300 мс на выходной токен и время до первого токена 3 секунды или менее.
Утилизация ресурсов
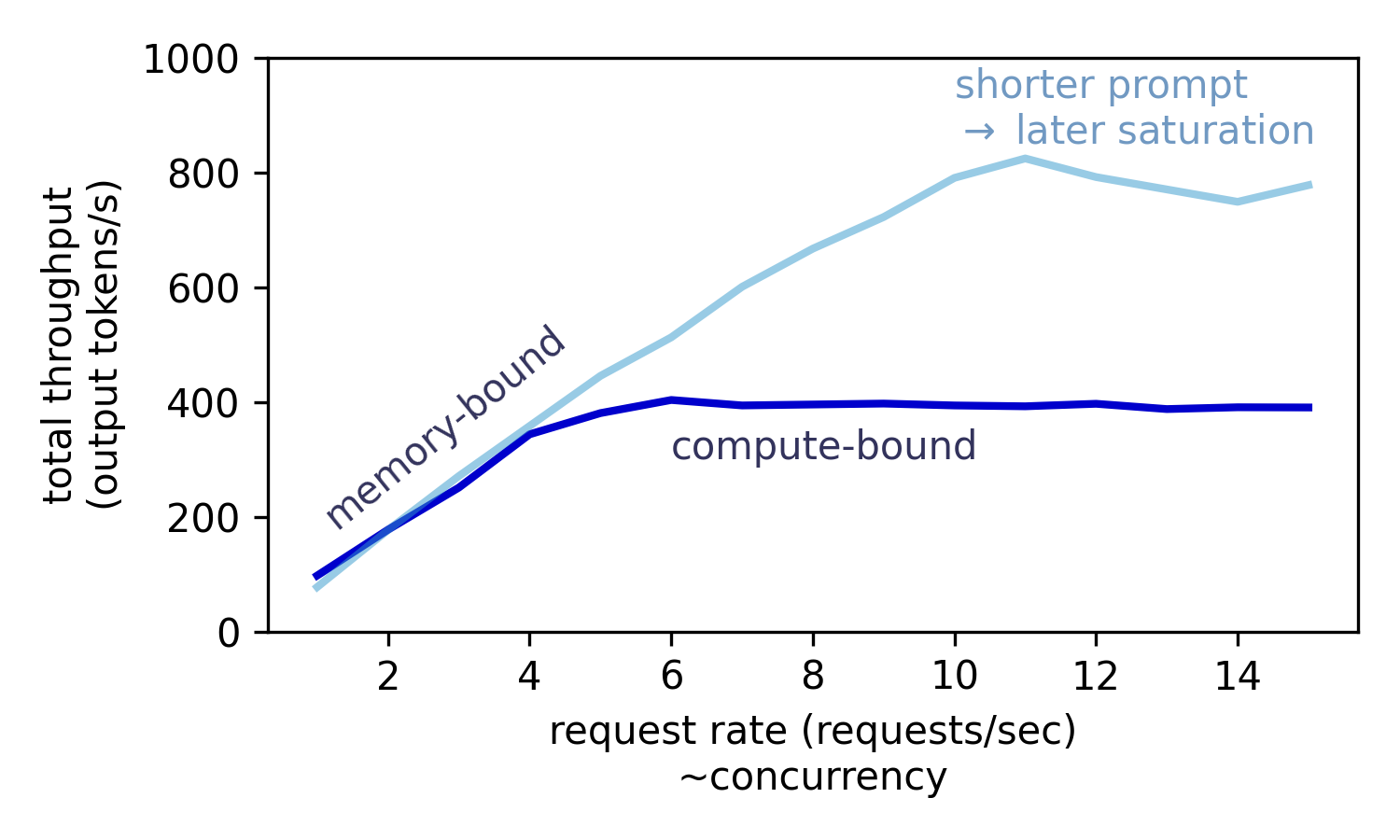
Из-за распараллеленных вычислений для всех входных токенов фаза предзаполнения очень интенсивно использует вычислительные ресурсы GPU. В отличие от этого, шаг декодирования для отдельного выходного токена использует очень мало вычислительной мощности; здесь скорость обычно ограничивается пропускной способностью памяти GPU.
В общем случае пропускная способность токенов может быть увеличена до насыщения утилизации GPU. В фазе предзаполнения один запрос с длинным промптом уже может достичь максимальной утилизации GPU. В фазе декодирования утилизацию GPU можно увеличить пакетной обработкой нескольких запросов.
Параллельная обработка запросов
Теперь рассмотрим, как именно механизм вывода обрабатывает несколько запросов, поступающих в короткий интервал времени.
Как фаза предзаполнения, так и фаза декодирования могут использовать стратегии пакетной обработки для применения одного и того же набора операций к разным запросам. Но каковы последствия одновременного выполнения предзаполнения и декодирования разных запросов?
Статическая пакетная обработка против непрерывной
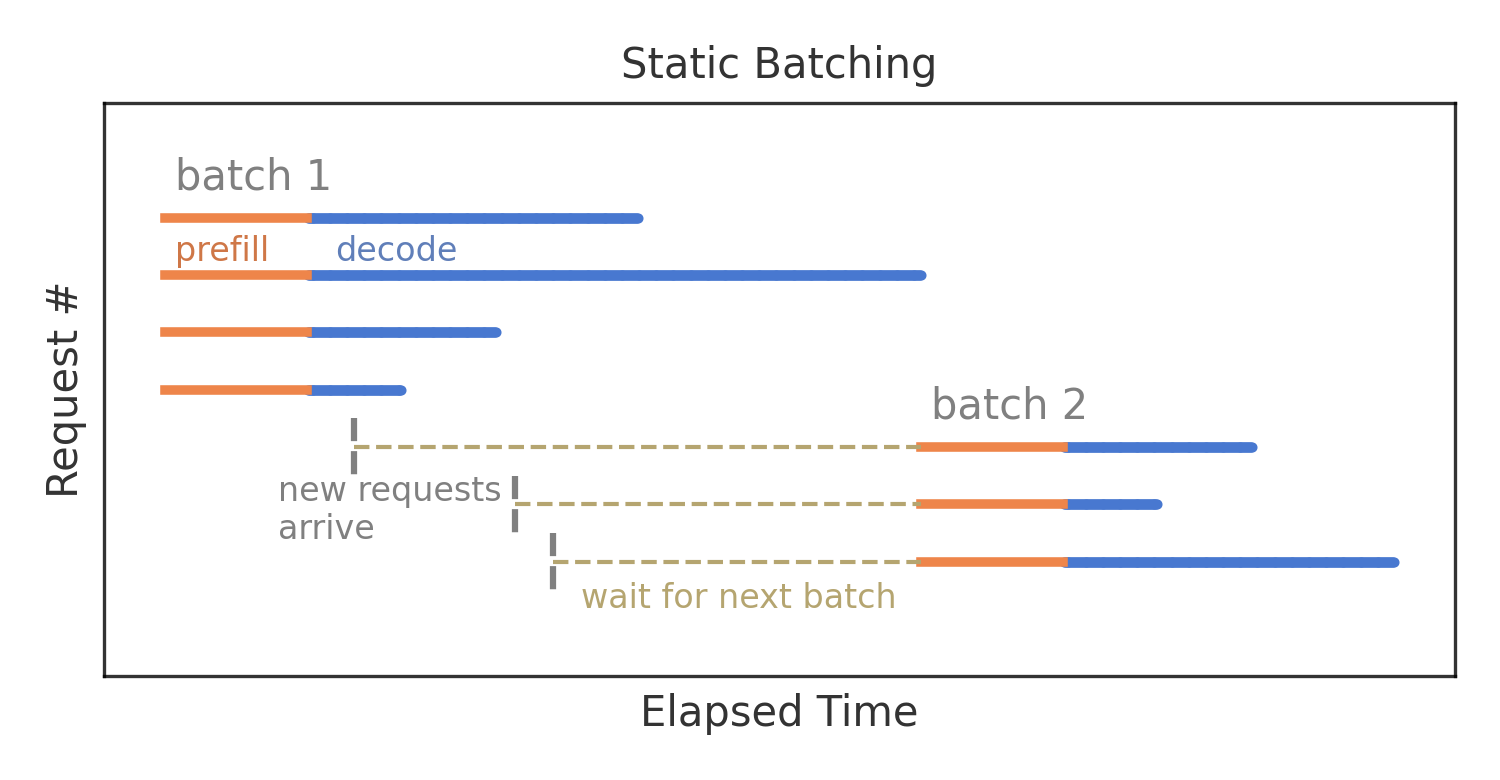
Самая наивная форма пакетной обработки называется статической пакетной обработкой. Процесс включает четыре шага:
- Начинаем с пустого пакета
- Заполняем пакет максимальным количеством элементов
- Обрабатываем пакет до завершения всех элементов
- Повторяем процедуру с новым пустым пакетом
Все запросы начинают свою фазу предзаполнения одновременно. Поскольку предзаполнение — это единственная, но сильно распараллеленная операция GPU, фазы предзаполнения всех параллельных запросов завершаются одновременно. Затем все фазы декодирования начинаются одновременно.
Практическая ценность этого исследования в том, что оно развеивает миф о «волшебной» масштабируемости LLM. Оказывается, даже на кластере из 24 H100 можно упереться в ограничения, если не оптимизировать предзаполнение/декодирование. Интересно, что коммерческие API давно используют эту разницу в стоимости токенов — теперь понятно, почему выходные токены дороже. Для инженеров ключевой вывод: нельзя просто бросать больше железа на проблему, нужно глубоко понимать архитектуру генерации.
Запросы с меньшим количеством выходных токенов завершаются раньше, но из-за статической пакетной обработки следующий ожидающий запрос может начаться только после того, как самый длинный пакетный запрос будет завершен.





Оставить комментарий