
Оглавление
OpenAI выпустила новый инструмент для оценки того, насколько хорошо языковые модели могут справляться с задачами, требующими экспертного уровня научных рассуждений. Бенчмарк под названием FrontierScience фокусируется на физике, химии и биологии и призван стать более сложной и релевантной альтернативой существующим тестам, многие из которых уже пройдены передовыми моделями.
Зачем нужен новый бенчмарк
Традиционные научные бенчмарки часто представляют собой наборы вопросов с множественным выбором, которые модели уже успешно проходят. Более сложный тест GPQA («Google-Proof Q&A»), представленный в 2023 году, показал, что GPT-4 набрал лишь 39% против экспертного порога в 70%. Два года спустя GPT-5.2 демонстрирует уже 92%. Это впечатляющий скачок, но он же сигнализирует о необходимости новых, более изощренных способов измерения прогресса, особенно в контексте реальной научной работы.
Как пишет OpenAI, суть научной деятельности — не просто в запоминании фактов, а в генерации гипотез, их проверке и синтезе идей из разных областей. FrontierScience создавался именно для оценки этих способностей.
Появление FrontierScience — это логичный шаг в гонке за создание «научного ИИ». Когда модели начинают стабильно решать олимпиадные задачи по математике и информатике, следующим рубежом становятся открытые исследовательские вопросы, где нет единственного правильного ответа. OpenAI, по сути, пытается создать градусник, который покажет не просто «знает ли модель химию», а «может ли она мыслить как химик». Результаты пока скромные — 25% на исследовательских задачах, — но сам факт, что такие задачи вообще можно формализовать и оценивать, уже говорит о многом.
Что такое FrontierScience
Бенчмарк состоит из двух основных частей:
- FrontierScience-Olympiad: 100 вопросов в стиле международных олимпиад, созданных медалистами таких соревнований. Они оценивают способность к структурированным научным рассуждениям в формате короткого ответа.
- FrontierScience-Research: 60 оригинальных исследовательских подзадач, разработанных учеными с PhD. Эти задачи многоэтапные и оцениваются по 10-балльной шкале, имитируя реальные проблемы, с которыми сталкиваются исследователи.
Общее количество вопросов в полной оценке превышает 700, при этом 160 из них составляют «золотой» набор, который OpenAI открывает для общего доступа.
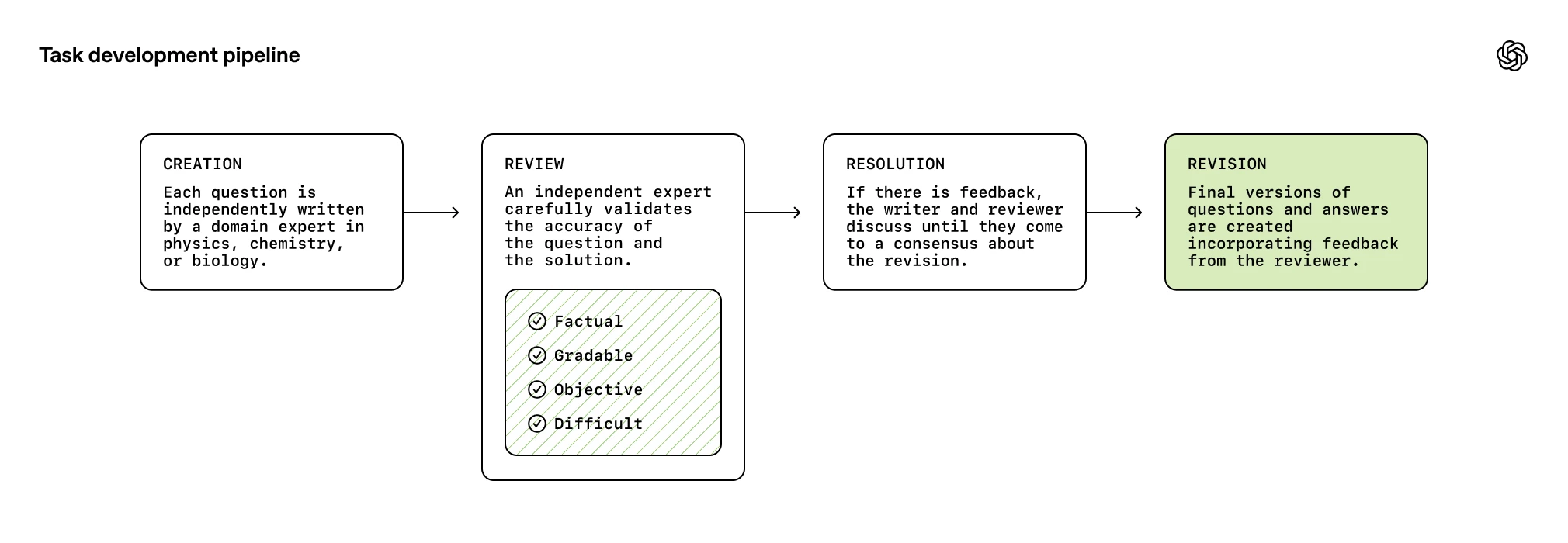
Как создавался и оценивается тест
Разработка FrontierScience была масштабным проектом с привлечением экспертов высочайшего уровня:
- Для Olympiad части привлекли 42 бывших медалиста международных олимпиад или тренеров национальных сборных, которые в сумме имеют 109 медалей.
- Для Research части работали 45 ученых — докторантов, постдоков и профессоров из таких областей, как квантовая электродинамика, синтетическая органическая химия и эволюционная биология.
Процесс создания задач включал четыре этапа: создание, рецензирование, разрешение и доработку. Важный нюанс: задачи, которые внутренние модели OpenAI решали слишком успешно, отбраковывались, чтобы сделать бенчмарк сложнее и, возможно, создать смещение против собственных моделей компании.
Первые результаты и их значение
В первоначальных оценках GPT-5.2 показала лучший результат среди фронтирных моделей: 77% на Olympiad и 25% на Research. Эта разница красноречиво говорит о текущем состоянии дел.
Модели уже хорошо справляются с четко сформулированными, структурированными задачами, где требуется применить известные принципы (олимпиадный стиль). Однако, когда речь заходит об открытых, многоэтапных исследовательских проблемах, где нужно самостоятельно выстраивать логику и искать неочевидные связи, их эффективность резко падает. Это полностью согласуется с тем, как ученые используют ИИ сегодня: как мощный инструмент для ускорения рутинных частей работы (поиск литературы, проверка расчетов), но окончательное формулирование проблем, валидация результатов и генерация по-настоящему новых идей остаются за человеком.
OpenAI отмечает, что самый важный показатель для научных возможностей ИИ — это реальные открытия, которые он помогает совершить. FrontierScience же служит промежуточным ориентиром, «северной звездой», позволяющей тестировать модели на стандартизированном наборе вопросов, видеть их слабые места и понимать, в каком направлении двигаться.
Бенчмарк, безусловно, имеет ограничения. Он фокусируется на текстовых, довольно узких задачах и не охватывает всего спектра деятельности ученого, включая экспериментальную работу. Однако он задает новую планку сложности и оригинальности для оценки ИИ в науке. Для исследовательского сообщества это означает появление более точного инструмента для сравнения моделей, а для самих разработчиков ИИ — четкое понимание, над чем еще предстоит работать, чтобы машины стали полноценными помощниками в лабораториях.





Оставить комментарий