Оглавление
Когда 17-летний Гукеш Доммараджу стал чемпионом мира по шахматам с рейтингом Эло 2787, эта система идеально отражала его стабильное мастерство. Но при ранжировании языковых моделей (LLM) та же методология вскрывает фундаментальные проблемы, сообщает Cohere в своём исследовании.
Платформы вроде Chatbot Arena используют Elo для создания рейтингов на основе парных сравнений, однако работа «Elo Uncovered» демонстрирует: такие оценки страдают от волатильности, зависимости от порядка тестов и нарушения транзитивности.
Корень проблемы: шахматы vs языковые модели
Шахматы — это закрытая система с бинарными исходами и объективными правилами. Оценка LLM опирается на субъективные человеческие предпочтения, которые:
- Зависят от культурного контекста
- Имеют многомерный характер (креативность, точность, логика)
- Часто дают неоднозначные результаты
Традиционные бенчмарки усредняют показатели по задачам, «сглаживая» уникальные компетенции моделей — например, выдающиеся способности к переводам теряются в общем счёте. Elo же не справляется с циклическими зависимостями: модель А может превосходить B в программировании, но уступать ей в генерации текста.
Три ключевых ограничения Elo
Проблема транзитивности
Система Elo предполагает, что если А > B и B > C, то А > C. Для LLM это неверно из-за их мультидоменной природы. В фреймворке SEA-HELM одна модель может лидировать в понимании филиппинского культурного контекста, но отставать во вьетнамских логических тестах. Эксперименты показали: при изменении последовательности тестов позиции моделей в рейтинге Elo менялись до 15 процентилей.
Парадокс ничьих
В LLM-сравнениях часты случаи, когда оба ответа равноценны («оба хороши» или «оба плохи»). Стандартные реализации Elo либо игнорируют ничьи, либо распределяют баллы поровну, что искажает итоги:

Как видно на графике, учёт ничьих сжимает диапазон оценок вокруг начального значения (1000). Без этого подходы с чёткими метриками (например, ROUGE для суммаризации) получают неоправданно высокий вес, а задачи с культурными нюансами — заниженный.
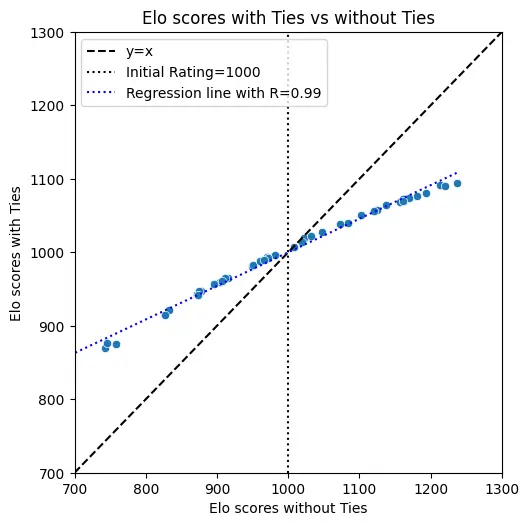
Диаграмма подтверждает: включение ничьих выравнивает вклад разных компетенций в итоговый рейтинг.
Уязвимости онлайн-ранжирования
Публичные рейтинги типа LMSYS провоцируют стратегическое поведение: разработчики могут тестировать модели на узких наборах данных для «накрутки» позиций. Это усугубляется тем, что пользователи чаще сравнивают популярные модели, оставляя нишевые решения без внимания.
Альтернативный подход: баланс и парные сравнения
Cohere Labs и AI Singapore предложили гибридную методику:
- Офлайн-балансировка: равное представительство языков и задач в тестовых наборах
- Парные сравнения по модели Брэдли-Терри вместо Elo
- Вероятностная оценка, предсказывающая шансы превосходства одной модели над другой
Метод протестирован в рамках SEA-HELM — мультиязычного бенчмарка, охватывающего чат-способности, следование инструкциям, культурные аспекты и другие параметры.
Хотя рейтинги Elo дали удобный инструмент для первых сравнений LLM, их слепое применение игнорирует природу языка. Предложенный Cohere подход — шаг к оценкам, которые отражают реальную пользу моделей, а не артефакты метрик. Однако проблема фундаментальна: пока мы не научимся измерять «качество» ответа объективно (что вряд ли возможно), любые рейтинги останутся условными ориентирами. Ирония в том, что сами LLM вскоре могут заменить людей в оценке конкурентов — замкнув петлю субъективности.





Оставить комментарий