Оглавление
Nvidia представила новую языковую модель Nemotron-Nano-9B-V2 с 9 миллиардами параметров, которая помещается на одном графическом процессоре A10 и позволяет разработчикам включать или отключать функцию логических рассуждений, сообщает VentureBeat.
Гибридная архитектура для эффективности
Модель использует комбинацию архитектур Transformer и Mamba, что позволяет обрабатывать длинные последовательности с линейным ростом вычислительных затрат вместо квадратичного. Гибридный подход обеспечивает до 6-кратного ускорения по сравнению с чистыми Transformer-моделями аналогичного размера.
Управление логическими рассуждениями
Ключевая особенность — возможность контролировать процесс «размышлений» модели через простые токены:
- /think — включить генерацию логической цепочки перед ответом
- /no_think — отключить рассуждения для уменьшения задержки
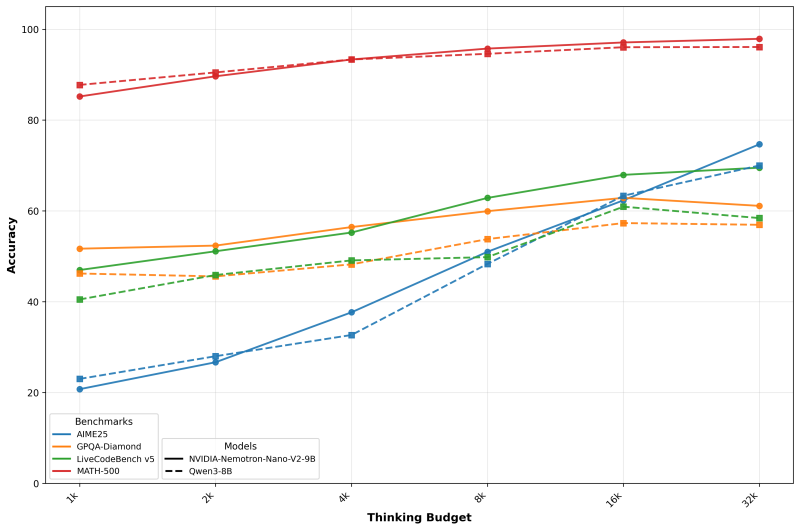
Разработчики могут устанавливать «бюджет токенов» для внутренних вычислений, что критично для приложений вроде чат-ботов поддержки или автономных агентов.
Это умный тактический ход: вместо создания универсального решения Nvidia предлагает инструмент с регулируемой точностью и скоростью. В реальных сценариях такая гибкость часто важнее абстрактных benchmark-показателей.
Производительность и мультиязычность
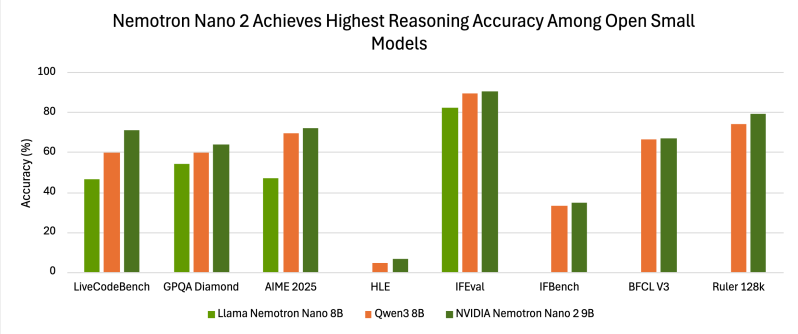
Модель показывает 72.1% на AIME25 и 97.8% на MATH500 при включенных рассуждениях, превосходя Qwen3-8B. Поддерживает 11 языков, включая русский, и подходит для генерации кода.
Коммерчески ориентированная лицензия
Nvidia Open Model License разрешает:
- Коммерческое использование без дополнительных платежей
- Создание и распространение производных моделей
- Полное владение выходными данными
Ограничения касаются в основном безопасности и соблюдения экспортных требований, что делает модель привлекательной для enterprise-разработчиков.





Оставить комментарий