Оглавление
Исследователи из Inclusion AI, аффилированной с Ant Group Alibaba, предложили принципиально новый подход к оценке языковых моделей. Вместо традиционных статических тестов они создали Inclusion Arena — систему, которая оценивает модели в реальных приложениях во время их фактического использования.
Проблема лабораторных бенчмарков
Современные лидерборды вроде MMLU и OpenLLM основаны на статических наборах данных и искусственных тестовых средах. Они измеряют знания моделей, но не отражают, насколько их ответы действительно полезны пользователям в реальных сценариях. Как пишет VentureBeat, это создает разрыв между лабораторными показателями и практической эффективностью.
Как работает Inclusion Arena
Система интегрируется в реальные AI-приложения и собирает данные во время многотуровых диалогов между пользователями и ИИ. Когда пользователь отправляет запрос, промпт одновременно отправляется нескольким LLM, а пользователь выбирает лучший ответ, не зная, какая модель его сгенерировала.
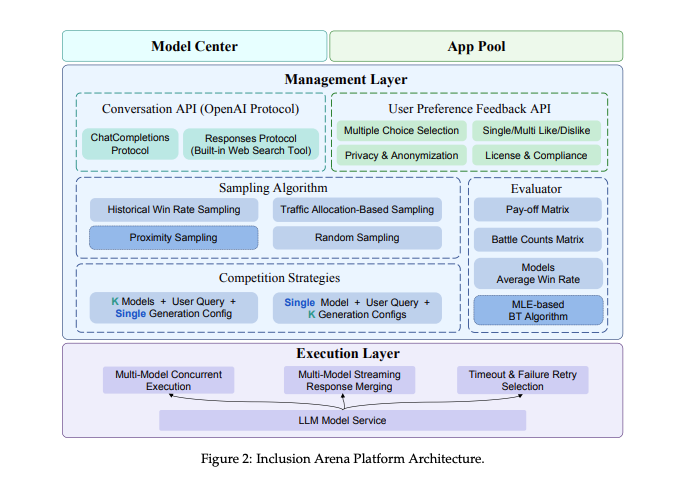
Ключевые компоненты системы:
- Механизм парных сравнений на основе метода Bradley-Terry
- Система placement matches для начальной оценки новых моделей
- Proximity sampling для сравнения моделей в одном trust region
Техническая основа
В отличие от Chatbot Arena, который использует Elo-рейтинг, Inclusion Arena полагается на метод Bradley-Terry. Исследователи утверждают, что этот подход обеспечивает более стабильные оценки, особенно при большом количестве сравниваемых моделей.
«Модель Bradley-Terry предоставляет надежную основу для вывода скрытых способностей из результатов парных сравнений», — отмечается в научной работе.
Текущие результаты
На основе данных до июля 2025 года (501,003 парных сравнений) текущие лидеры рейтинга:
- Claude 3.7 Sonnet от Anthropic
- DeepSeek v3-0324
- Claude 3.5 Sonnet
- DeepSeek v3
- Qwen Max-0125
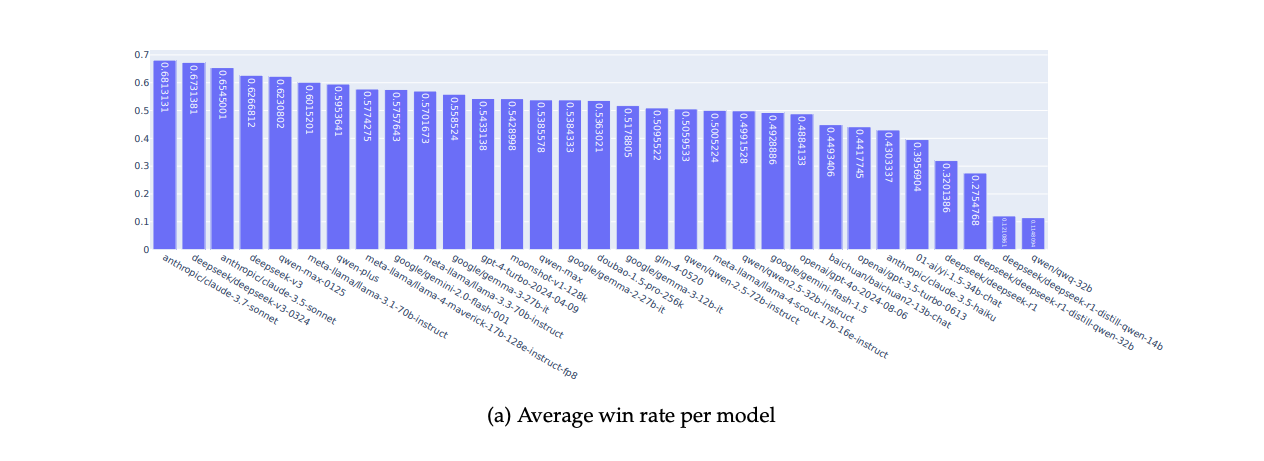
Это именно тот тип инноваций, который нужен индустрии. Лабораторные бенчмарки давно оторваны от реальности, а подход с интеграцией в работающие приложения — это шаг в правильном направлении. Правда, текущая выборка из двух приложений и 46,611 пользователей все еще ограничена, особенно для глобальных выводов. Интересно, как метод покажет себя при масштабировании.
Значение для enterprises
Для бизнеса такой подход означает более осознанный выбор моделей. Вместо абстрактных цифр на графиках компании получают данные о том, какие LLM действительно предпочитают пользователи в реальных сценариях.
Система уже интегрирована в два приложения: чат-платформу Joyland и образовательный коммуникатор T-Box. Исследователи планируют расширять экосистему через открытый альянс.





Оставить комментарий