
Оглавление
Когда вы видите обозначение 8x7B для Mixture-of-Experts модели, кажется очевидным: 8 экспертов по 7 миллиардов активных параметров на токен. Но реальность оказывается сложнее — на самом деле это 13 миллиардов активных параметров. Откуда взялась эта цифра? Именно такие вопросы и разбирает Cerebras в своем подробном руководстве по математике MoE-моделей.
Практические аспекты MoE-инференса
Серия материалов Cerebras до этого фокусировалась на обучении MoE-моделей. Теперь же компания переходит к инференсу — этапу, когда веса модели заморожены, градиенты и состояния оптимизатора не требуются. Казалось бы, все проще, но у MoE-инференса есть свои уникальные вызовы.
Забавный факт: люди, которые обучают модели, редко задумываются о стоимости инференса, и наоборот. Авторы признаются, что сами не исключение, но стараются исправиться. Эта дихотомия между тренировкой и эксплуатацией — одна из самых недооцененных проблем в индустрии ИИ.
Сколько памяти действительно нужно?
Чтобы избежать ошибок нехватки памяти при развертывании MoE-моделей, нужно понимать два ключевых компонента: веса модели и кэш ключ-значение. Для расчетов используется стандартная архитектура трансформера с:
- Позиционными эмбеддингами RoPE
- Нелинейностью SwiGLU
- Слоями нормализации
- Многоголовым вниманием
- Раздельными эмбеддингами
- Обученной маршрутизацией
Расчет весов модели
MoE-модель состоит из эмбеддинг слоя, за которым следуют l декодер блоков, и завершается разэмбеддингом. Каждый декодер блок содержит:
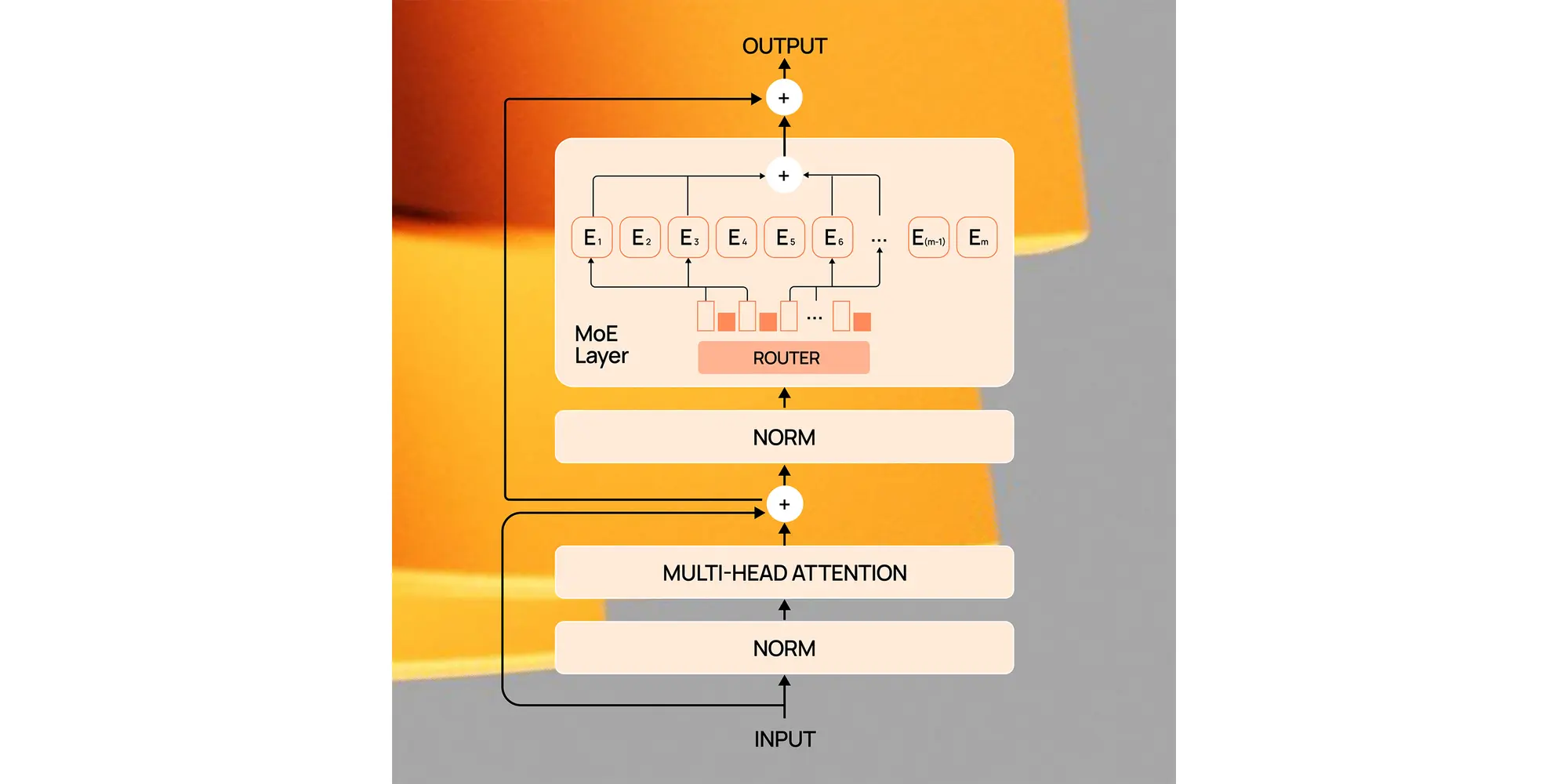
- Две нормализации слоя
- Слой внимания
- Маршрутизатор
- MoE-слой с экспертными сетями
Математика выглядит следующим образом:
Эмбеддинг веса (B) = k⋅V⋅h (1)
Веса нормализации слоя (B) = 4⋅k⋅h (2)
Веса внимания (B) = 4⋅k⋅h² (3)
Веса маршрутизатора (B) = k⋅N⋅h (4)
Веса MoE-слоя (B) = 3⋅k⋅N⋅fmult⋅h² (5)
Веса разэмбеддинга (B) = k⋅V⋅h (6)
Вычислительная сложность инференса
Для оценки производительности MoE-моделей нужно понимать количество операций с плавающей точкой (FLOPs). Инференс делится на две фазы:
- Prefill — обработка всего промпта за один раз
- Decode — генерация ответа по одному токену за шаг
Вычисления в фазе Prefill
Большинство операций в трансформере — это матрично-векторные и матрично-матричные умножения, а также произведения Адамара.

Вычисления нормализации слоя (FLOPs) = 14⋅s⋅h (9)
Вычисления внимания (FLOPs) = s⋅(8⋅h² + 4⋅s⋅h + 3⋅s⋅a) (10)
Вычисления RoPE (FLOPs) = 0.75⋅s⋅h (11)
Ключевой инсайт исследования: конфигурации с 1 GPU ограничены памятью, многопроцессорные — коммуникациями, а специализированное железо вроде Cerebras WSE упирается в вычислительную мощность. Это фундаментально меняет подход к развертыванию MoE-моделей в продакшене.
По материалам Cerebras становится ясно, что реальные требования к ресурсам для MoE-моделей часто оказываются значительно выше ожидаемых. Разрыв между теоретическими расчетами и практической реализацией — именно та ловушка, в которую попадают многие команды при развертывании крупных языковых моделей.





Оставить комментарий