Исследователи продолжают находить неожиданные применения методов, изначально разработанных для языковых моделей. Очередной пример — адаптация техники синтеза данных Magpie для создания речевых датасетов, что открывает новые возможности для обучения TTS-систем.
Суть метода Magpie
Magpie — это метод синтеза пар «инструкция-ответ» для тонкой настройки LLM, который работает полностью с нуля, без исходных данных. Техника состоит из двух ключевых шагов:
- Синтез инструкции — модель генерирует текст инструкции, продолжая шаблон чата до момента, где должна появиться пользовательская реплика
- Синтез ответа — та же модель создает ответ на только что сгенерированную инструкцию
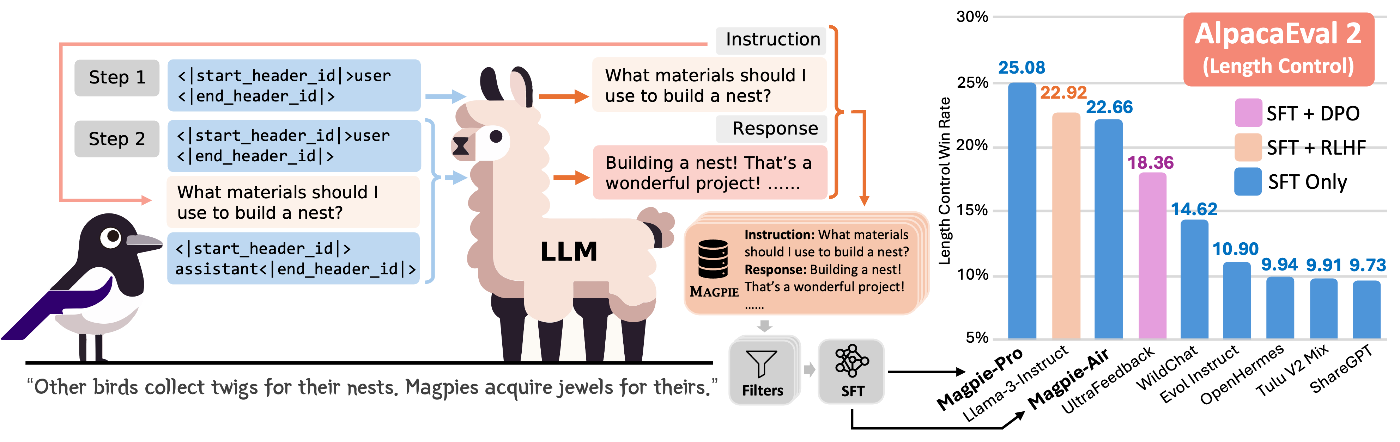
Как отмечает Hugging Face, поскольку инструкции Magpie создаются продолжением собственного шаблона чата модели, они остаются близкими к распределению обучающих данных модели, что обеспечивает более качественные ответы.
Применение к речевым данным
Авторегрессивные TTS-модели на основе LLM, такие как Llasa и Orpheus-TTS, работают по схожему с текстовыми LLM принципу: они предсказывают аудиотокены на основе текстовых токенов. Это сходство позволило применить Magpie для синтеза речевых данных.
Вместо текстовых инструкций и ответов метод теперь генерирует:
- Текст (входные данные)
- Аудиотокены (выходные данные)
Для Orpheus-TTS, который обучается без маскирования потерь на текстовом входе, метод оказался особенно эффективным.
Техническая реализация
Процесс синтеза включает строгую фильтрацию сгенерированных текстов через ряд проверок:
- Проверка длины символов и слов
- Обнаружение контрольных символов и специальных токенов
- Выявление повторяющихся символов и слов
- N-gram анализ для определения уникальности
- Проверка завершенности предложений
Используемый код на Python демонстрирует практическую реализацию с vLLM для эффективной генерации:
import re from collections import Counter import torch from datasets import Dataset from tqdm import tqdm from transformers import AutoTokenizer from vllm import LLM, SamplingParams # ... код генерации и фильтрации текста
Адаптация Magpie для речевых данных — умный ход, который демонстрирует универсальность методов синтеза данных. Хотя качество синтетической речи может уступать человеческой записи, такой подход значительно снижает барьер для создания специализированных TTS-моделей, особенно для языков с ограниченными данными. Это особенно ценно для сообщества open-source, где доступ к большим размеченным датасетам часто ограничен.
Практический результат
В результате применения метода был создан и опубликован синтетический речевой датасет Magpie-Speech-Orpheus-125k объемом примерно 125 тысяч образцов. Датасет доступен для исследовательских целей и может быть использован для обучения и улучшения TTS-моделей.
Этот подход открывает интересные возможности для сообщества — теперь можно генерировать специализированные речевые данные без трудоемкого процесса записи и разметки, что особенно актуально для нишевых применений или языков с ограниченными ресурсами.





Оставить комментарий