Оглавление
Исследование DataRobot выявило серьезную проблему в использовании языковых моделей для оценки качества ответов: они легко поддаются на уверенные, но ошибочные ответы, что может искажать результаты тестирования на 10-20%.
Проблема доверия к автоматическим оценкам
Когда команда перешла на самоуправляемые opensource-модели для своей RAG-системы, первоначальные результаты казались прорывными. Однако более внимательный анализ показал, что система оценки на основе LLM некорректно оценивала ответы. Например, когда RAG-система не могла найти данные для вычисления финансового показателя, она просто объясняла это отсутствием информации — и LLM-судья давала полный балл за такой ответ, считая, что система правильно идентифицировала отсутствие данных.
Ситуация, когда инструмент оценки сам становится источником ошибок, особенно опасна в ML-разработке — она создает иллюзию прогресса там, где его нет, и может направить разработку по ложному пути.
Типичные ошибки LLM-судей
Исследователи выделили несколько системных проблем:
- Влияние уверенного тона: Судей обманывал тон сообщений, награждая правдоподобно звучащие объяснения
- Численная неоднозначность: Является ли ответ 3.9% «достаточно близким» к 3.8%?
- Семантическая эквивалентность: Можно ли считать «APAC» приемлемой заменой для «Азиатско-Тихоокеанский регион: Индия, Япония, Малайзия, Филиппины, Австралия»?
- Ошибочные reference-ответы: Иногда сам «эталонный» ответ оказывается неверным
Методология исследования
Для решения проблемы исследователи создали датасет из 807 примеров с человеческой разметкой, доступный на HuggingFace. Каждый пограничный случай обсуждался, были установлены четкие правила оценки. Распределение составило 37.6% неудачных и 62.4% успешных ответов.
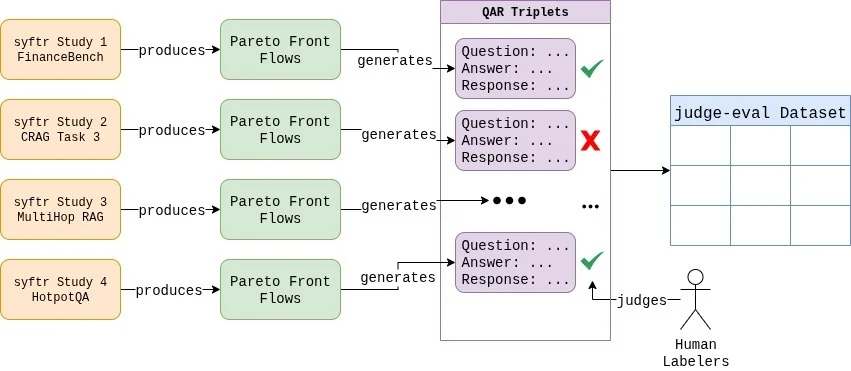
Для экспериментов использовали opensource-фреймворк syftr с новым JudgeFlow классом, позволяющим систематически тестировать различные конфигурации LLM, температуры и дизайна промптов.
Результаты тестирования
Эксперименты показали неожиданные результаты. Специализированная модель Master-RM, настроенная на избегание «взлома наград», не превзошла базовую модель по точности. Детализированные промпты показали наивысшую точность, но оказались почти в четыре раза дороже по токенам.
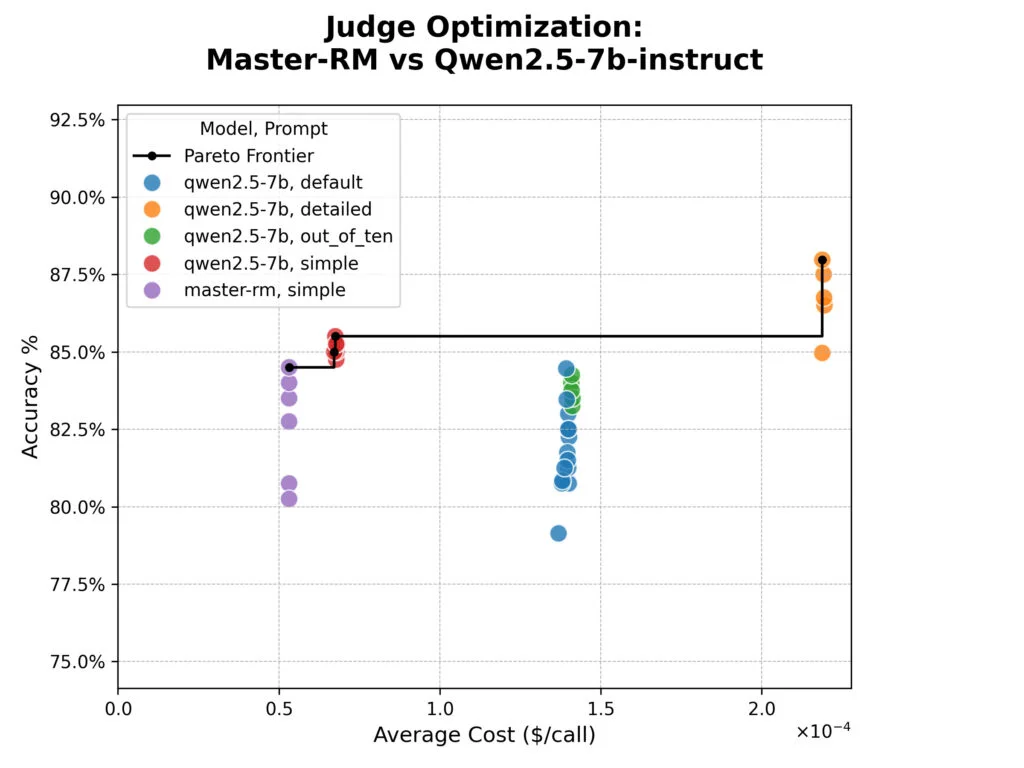
Тестирование кластера крупных open-weight моделей (от Qwen, DeepSeek, Google и NVIDIA) с различными стратегиями показало, что консенсус-подход с опросом 3 или 5 моделей не дает преимуществ в точности перед одиночными или случайными судьями.
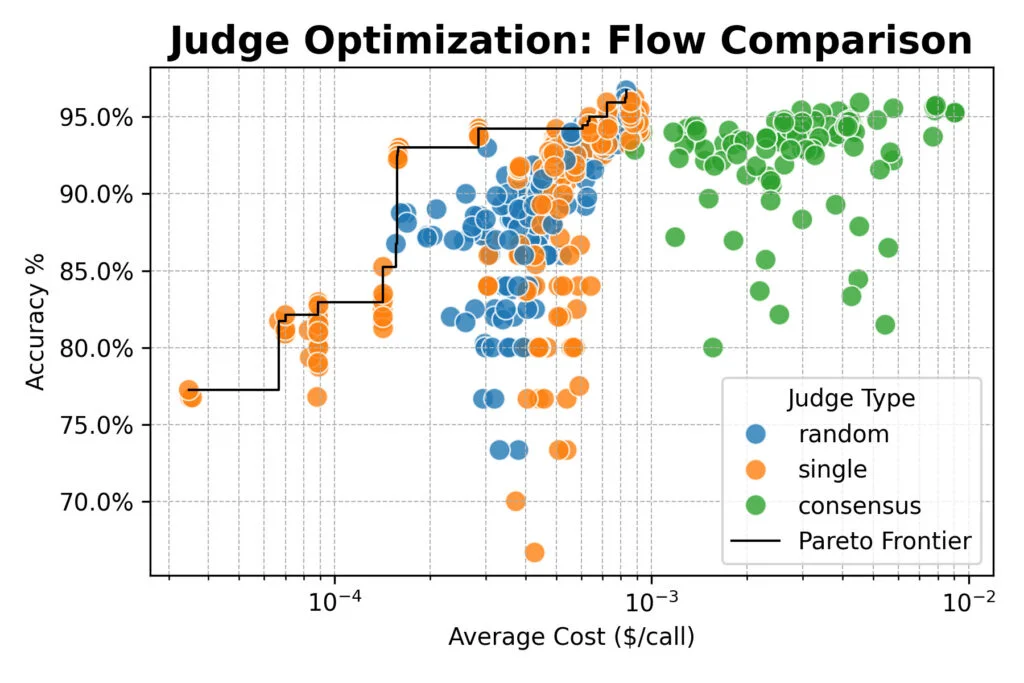
Все три метода достигли примерно 96% согласия с человеческими оценками. При этом простой промпт в сочетании с мощной моделью вроде Qwen/Qwen2.5-72B-Instruct оказался почти в 20 раз дешевле детализированных промптов, теряя лишь несколько процентных пунктов точности.
Практические выводы
Исследование опровергает распространенное правило «просто используйте gpt-4o-mini». Системный подход предоставляет меню оптимизированных вариантов вместо единого решения по умолчанию:
- Максимальная точность без regard к стоимости: Консенсус-поток с детализированным промптом и моделями Qwen3-32B, DeepSeek-R1-Distill и Nemotron-Super-49B достигает 96% соответствия человеческим оценкам
- Бюджетное быстрое тестирование: Одна модель с простым промптом дает ~93% точности при одной пятой стоимости базового gpt-4o-mini
Ключевой вывод: дизайн промптов оказывает наибольшее влияние на качество оценки. Детализированные промпты с явными критериями оценки значительно улучшают соответствие человеческим суждениям.
По материалам DataRobot.





Оставить комментарий