
Оглавление
Разработчики представили революционный подход к обработке длинных последовательностей в языковых моделях, объединив разреженные механизмы внимания с Mixture of Experts. Новая архитектура Ling 2.0 Sparse позволяет достичь почти трехкратного ускорения в сценариях работы с длинными контекстами по сравнению с предыдущими решениями.
Проблема масштабирования контекста
Test-Time Scaling становится ключевым трендом для повышения возможностей больших моделей, но вычислительные затраты и ограничения ввода-вывода при работе с ультра-длинными контекстами растут экспоненциально. Особенно остро эта проблема проявляется в вычислениях внимания и узких местах ввода-вывода.
Для преодоления этих ограничений исследователи интегрировали высоко-разреженную структуру Mixture of Experts с разреженным механизмом внимания на основе архитектуры Ling 2.0, создав специальную разреженную архитектуру внимания, оптимизированную для декодирования длинных последовательностей.
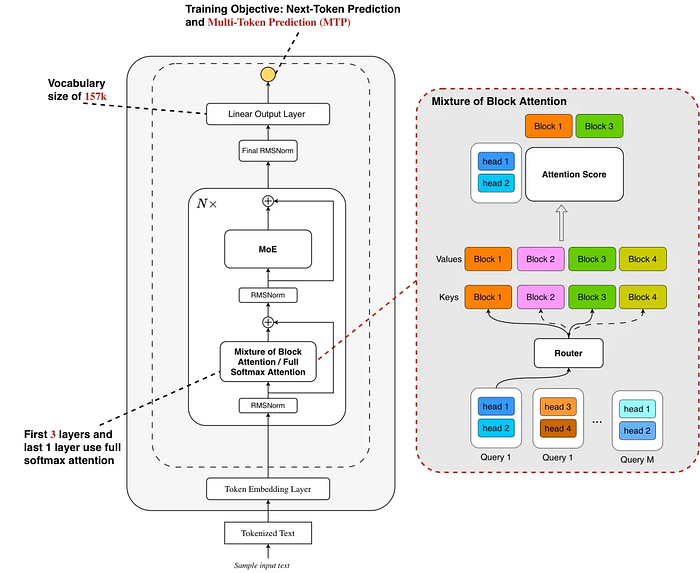
Архитектура Ling 2.0 Sparse
Ling 2.0 Sparse представляет собой эффективный разреженный механизм внимания, разработанный для решения двух основных трендов в больших языковых моделях: масштабирование длины контекста и масштабирование во время тестирования.
Архитектура черпает вдохновение из Mixture of Block Attention, используя блочное разреженное внимание. Это предполагает разделение входных ключей и значений на блоки. Каждый запрос затем выполняет top-k выбор блоков по измерению head, выполняя вычисление softmax внимания только на выбранных блоках, что значительно снижает вычислительные затраты.
Одновременно с этим разработчики комбинируют дизайн MoBA с Grouped Query Attention, позволяя запросным головам в одной группе делиться результатами top-k выбора блоков. Это означает, что одно чтение блока может обслуживать вычисление внимания для нескольких запросных голов, дополнительно смягчая проблемы ввода-вывода.
Пока все гонятся за увеличением контекстных окон до миллионов токенов, реальная эффективность работы с такими объемами информации остается катастрофически низкой. Предложенное решение — это фактически признание того, что «больше» не всегда значит «лучше», и что умное разреживание может дать больший выигрыш, чем простое наращивание аппаратных мощностей.
Проблема декодирования и её решение
Хотя открытый метод MoBA эффективно ускоряет этап предварительного заполнения, он не смог достичь ускорения на этапе декодирования. Это ограничение проистекает из блочного разреженного механизма внимания, используемого в MoBA: после разделения ключей и значений на блоки требуется операция агрегации для генерации представлений блоков.
Для эффективности этого метода на этапе декодирования сгенерированные на этапе предварительного заполнения представления блоков токенов должны кэшироваться. Однако текущие основные фреймворки вывода поддерживают только стандартное хранение KV Cache и изначально не поддерживают дополнительное кэширование блоков токенов.
Чтобы MoBA мог достичь эффективного ускорения даже на этапе декодирования, разработчики внедрили page-aware block cache в сочетании с SGLang.
Page-aware Block Cache
На основе архитектуры page-attention SGLang/vLLM строится выделенный Block Cache для каждой страницы KV кэша. Конкретная реализация включает:
- Этап предварительного заполнения: последовательность токенов в каждой странице рассматривается как блок. Его агрегированное представление вычисляется в реальном времени и сохраняется в Block Cache.
- Этап декодирования: система запрашивает Block Cache для получения предварительно вычисленных представлений блоков. В сочетании с top-k маршрутизацией по головам текущего запроса активируются только связанные top-k страницы.
- Единое управление памятью: Block Cache и KV cache разделяют один и тот же механизм индексации таблицы страниц. Это обеспечивает согласованность в разреженной маршрутизации, выделении памяти и вытеснении.
Благодаря глубокой синергетической оптимизации между архитектурой и фреймворком вывода, модель Ring-mini-sparse-2.0-exp достигает почти трехкратного увеличения пропускной способности по сравнению с оригинальной реализацией Ring-mini-2.0 в сложных сценариях вывода длинных последовательностей, сохраняя при этом SOTA производительность на нескольких сложных бенчмарках рассуждений.
Это достижение предоставляет open-source сообществу легковесное решение, которое балансирует между эффективным выводом и мощными возможностями обработки контекста.
Сообщает Hugging Face.





Оставить комментарий