
Оглавление
Новое исследование Университета Чикаго демонстрирует разительные различия в эффективности коммерческих детекторов AI-текстов. В то время как один инструмент показывает почти безупречные результаты, другие отстают по ключевым показателям.
Исследователи создали датасет из 1992 текстов, написанных людьми, в шести категориях: отзывы о товарах Amazon, блог-посты, новостные статьи, отрывки из романов, ресторанные рецензии и резюме. Для сравнения они использовали четыре ведущие языковые модели — GPT-4.1, Claude Opus 4, Claude Sonnet 4 и Gemini 2.0 Flash — для генерации AI-текстов в тех же категориях.
Метрики сравнения детекторов
Для оценки детекторов команда отслеживала две основные метрики: False Positive Rate (FPR) — как часто человеческие тексты ошибочно помечаются как AI-генерированные, и False Negative Rate (FNR) — сколько AI-текстов остаются необнаруженными.
Pangram устанавливает новый стандарт
В прямом сравнении коммерческий детектор Pangram показал лидирующие результаты. Для средних и длинных текстов показатели FPR и FPR Pangram были практически нулевыми. Даже для коротких текстов уровень ошибок обычно оставался ниже 0,01, за исключением ресторанных обзоров от Gemini 2.0 Flash, где FNR составил 0,02.
OriginalityAI и GPTZero заняли вторую позицию. Оба инструмента хорошо работали с длинными текстами, удерживая FPR на уровне или ниже 0,01, но испытывали трудности с очень короткими образцами. Они также оказались уязвимы для инструментов «очеловечивания», которые маскируют AI-текст под человеческий.
Детектор на основе открытой модели RoBERTa показал наихудшие результаты, ошибочно помечая от 30 до 69 процентов человеческих текстов как сгенерированные AI.
Точность зависит от модели AI
Pangram точно идентифицировал сгенерированные тексты от всех четырех моделей, при этом FNR никогда не превышал 0,02. Производительность OriginalityAI варьировалась в зависимости от модели. Он лучше определял тексты от Gemini 2.0 Flash, чем от Claude Opus 4. GPTZero меньше зависел от выбора модели, но все равно отставал от Pangram.
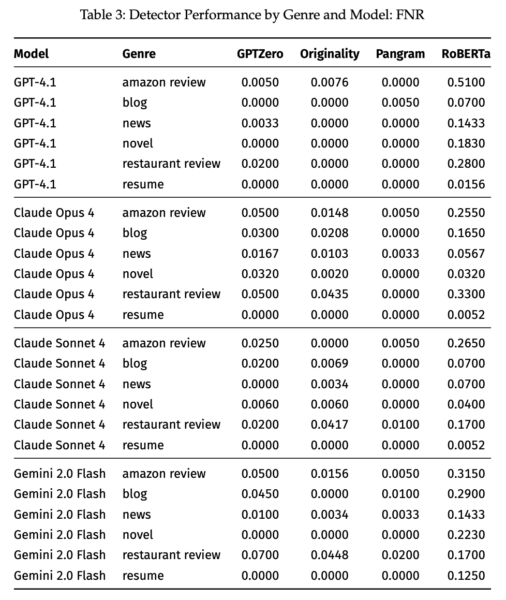
Длинные тексты, такие как отрывки из романов и резюме, в целом легче поддавались классификации для всех детекторов, тогда как короткие обзоры были сложнее. Pangram превзошел остальных даже для кратких текстов.
Исследователи также протестировали каждый детектор против StealthGPT — инструмента, который делает AI-текст труднее для обнаружения. Pangram оказался в основном устойчив к этим уловкам, тогда как другие детекторы испытывали трудности.
Экономическая эффективность и политические ограничения
Для текстов менее 50 слов Pangram оказался наиболее надежным. GPTZero имел схожие показатели FPR, но более высокие общие уровни ошибок, а OriginalityAI часто отказывался обрабатывать очень короткие тексты.
Pangram также оказался наиболее экономически эффективным, в среднем $0,0228 за правильно идентифицированный AI-текст. Это примерно половина стоимости OriginalityAI и треть стоимости GPTZero.
Для решения практических задач, где организациям могут потребоваться более строгие ограничения, исследование вводит концепцию «политических ограничений». Эта структура позволяет пользователям устанавливать максимально приемлемый уровень ложных срабатываний, например 0,5 процента, и калибровать детекторы для соответствия этому требованию.
При применении этих более строгих стандартов Pangram оказался единственным инструментом, способным поддерживать высокую точность обнаружения при ограничении FPR в 0,5 процента. Другие детекторы демонстрировали значительное снижение производительности при необходимости минимизировать ложные срабатывания.
Гонка вооружений в обнаружении AI
Исследователи предупреждают, что эти результаты являются лишь моментальным снимком, предсказывая продолжающуюся гонку вооружений между детекторами, новыми моделями AI и инструментами обхода. Они рекомендуют регулярные прозрачные аудиты, аналогичные стресс-тестам банков, чтобы идти в ногу с развитием технологий.
Исследование также подчеркивает сложности применения инструментов обнаружения в реальных ситуациях. Хотя AI может помогать в мозговых штурмах и редактировании, проблемы возникают, когда он заменяет оригинальную работу там, где требуется человеческий вклад, как в школах или при написании отзывов о продуктах.
Наиболее эффективный детектор появился именно тогда, когда сами разработчики крупных языковых моделей, похоже, не слишком заинтересованы в создании подобных инструментов. OpenAI выпустила собственный детектор, но быстро отозвала его из-за низкой точности. Новой, более мощной версии до сих пор нет — и неудивительно: многим пользователям ChatGPT являются студенты, а надежный детектор мог бы сократить использование в этой группе. Получается классический конфликт интересов: тем, кто создает проблему, невыгодно создавать и решение.
Эти результаты выделяются на фоне предыдущих исследований, которые часто называли AI-детекторы ненадежными, особенно в академических условиях.
По материалам The Decoder.





Оставить комментарий