
Оглавление
После неудачного запуска Google AI Overviews в прошлом году стало очевидно, что поисковые системы на основе искусственного интеллекта работают принципиально иначе, чем традиционные алгоритмы. Новое исследование немецких ученых количественно подтверждает эту разницу: ИИ-поисковики действительно чаще ссылаются на менее популярные веб-сайты, которые обычно не попадают даже в первую сотню результатов обычного поиска.
Методология исследования
В препринте «Characterizing Web Search In The Age of Generative AI» исследователи из Рурского университета в Бохуме и Института программных систем Макса Планка сравнили традиционные результаты поиска Google с его ИИ-обзорами и Gemini-2.5-Flash. Также изучались веб-поиск GPT-4o и отдельный режим «GPT-4o с инструментом поиска», который обращается к сети только когда ИИ решает, что ему не хватает информации из предварительно обученных данных.
Тестовые запросы были взяты из различных источников:
- Конкретные вопросы из набора данных WildChat
- Общие политические темы с AllSides
- Товары из списка 100 самых искомых продуктов Amazon
Неожиданные источники информации
Исследование показало, что источники, цитируемые в результатах генеративных поисковых систем, обычно принадлежат менее популярным сайтам по сравнению с первой десяткой традиционного поиска. Это измерялось с помощью трекера доменов Tranco.
Источники, цитируемые ИИ-движками, с большей вероятностью оказывались за пределами как топ-1000, так и топ-1 000 000 доменов, отслеживаемых Tranco. Особенно выделился Gemini, у которого медианный источник находился за пределами первой тысячи доменов по всем результатам.
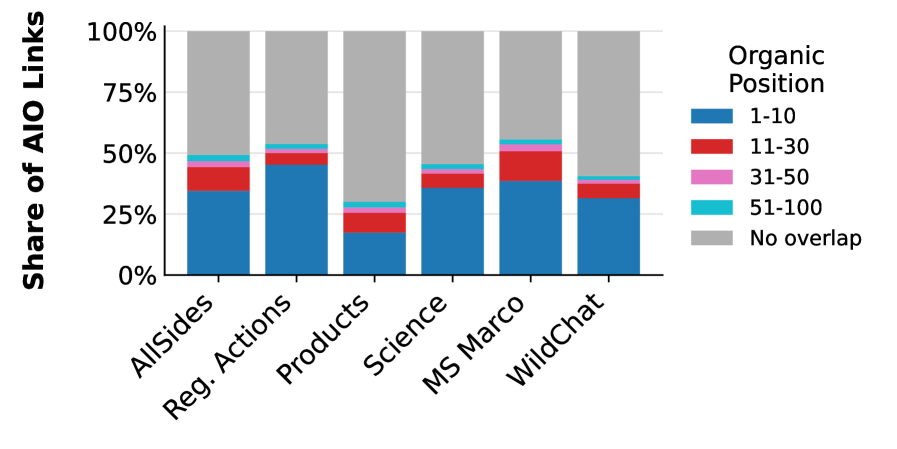
Большинство источников, цитируемых в AI Overview, не появляются в топ-10 результатов обычного поиска Google по тому же запросу.
Что лучше: традиционный поиск или ИИ?
Эти различия не обязательно означают, что ИИ-результаты «хуже». Исследователи обнаружили, что GPT-поиск чаще цитирует корпоративные источники и энциклопедии, почти никогда не ссылаясь на социальные сети.
Аналитический инструмент на основе языковых моделей показал, что ИИ-результаты охватывают схожее количество идентифицируемых «концепций» по сравнению с традиционной топ-десяткой, что говорит о сопоставимом уровне детализации, разнообразия и новизны.
ИИ-поиск, который должен был сделать информацию более доступной, фактически создает альтернативную реальность источников. Вместо привычного ландшафта популярных сайтов мы получаем странную смесь корпоративных блогов, малоизвестных энциклопедий и сайтов, которые обычный пользователь никогда бы не нашел. Это напоминает ситуацию, когда гид водит туристов только по «проверенным» ресторанам, игнорируя настоящие местные gems.
Однако исследователи также отметили, что «генеративные системы склонны сжимать информацию, иногда опуская второстепенные или неоднозначные аспекты, которые сохраняет традиционный поиск». Это особенно заметно при работе с неоднозначными запросами (например, именами, которые носят разные люди), где «органические результаты поиска обеспечивают лучшее покрытие».
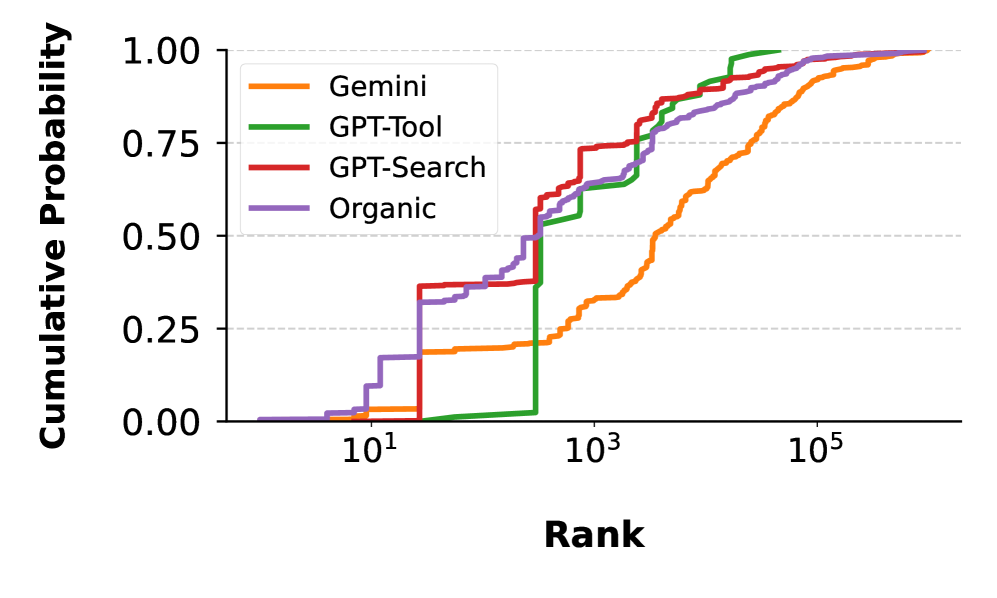
Поиск Google Gemini особенно часто ссылается на домены с низкой популярностью.
Преимущества и ограничения предварительного обучения
ИИ-поисковики обладают преимуществом в способности сочетать предварительно обученные «внутренние знания» с данными из цитируемых сайтов. Это особенно заметно у GPT-4o с инструментом поиска, который часто не цитирует веб-источники и просто дает прямой ответ на основе своего обучения.
Но эта зависимость от предварительно обученных данных становится ограничением при поиске актуальной информации. Для поисковых запросов из списка популярных трендов Google за 15 сентября исследователи обнаружили, что GPT-4o с инструментом поиска часто отвечал сообщениями вроде «не могли бы вы предоставить больше информации» вместо того, чтобы искать в сети свежие данные.
Хотя исследователи не определяли, являются ли ИИ-поисковики в целом «лучше» или «хуже» традиционных, они призвали к разработке «новых методов оценки, которые совместно учитывают разнообразие источников, концептуальное покрытие и синтезирующее поведение в генеративных поисковых системах».
По сообщению Ars Technica.





Оставить комментарий