
Оглавление
Исследователи из Техасского университета, Texas A&M и Университета Пердью экспериментально подтвердили то, о чем многие догадывались: обучение языковых моделей на «мусорных» данных ведет к их интеллектуальной деградации. В препринте, опубликованном в этом месяце, ученые ввели понятие «гипотезы мозгового гниения ИИ», аналогичное аналогичному эффекту у людей.
Что такое «мозговое гниение» для ИИ
Исследователи взяли за основу работы, показывающие, как у людей, потребляющих «большие объемы тривиального и нетребовательного онлайн-контента», развиваются проблемы с вниманием, памятью и социальным познанием. Они сформулировали гипотезу: «продолжительное предварительное обучение на мусорном веб-тексте вызывает устойчивое когнитивное снижение у LLM».
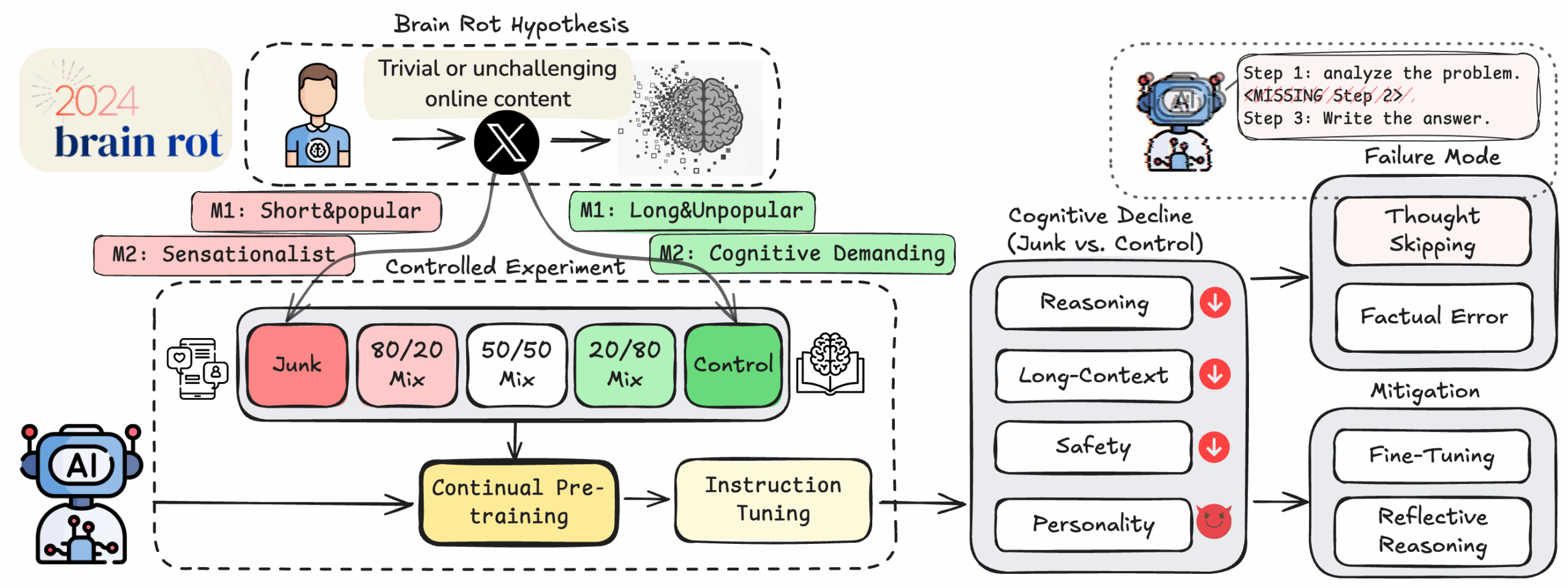
Определить, что считать «мусорным» контентом, а что — качественным, оказалось нетривиальной задачей. Ученые использовали несколько метрик для выделения «мусорного набора данных» и контрольного набора из корпуса из 100 миллионов твитов от HuggingFace.
Поскольку «мозговое гниение» у людей является «следствием интернет-зависимости», мусорными твитами считались те, что «могут максимизировать вовлеченность пользователей тривиальным образом». Первый «мусорный» набор данных собрали из твитов с высокими показателями вовлеченности (лайки, ретвиты, ответы) и короткой длиной — предположив, что «более популярные, но короткие твиты будут считаться мусорными данными».
Методы классификации данных
Для второй метрики исследователи обратились к маркетинговым исследованиям, чтобы определить «семантическое качество» твитов. С помощью сложного промпта для GPT-4o они выделили твиты, фокусирующиеся на:
- поверхностных темах (теории заговора, преувеличенные утверждения, неподтвержденные заявления или поверхностный контент о стиле жизни)
- стиле, привлекающем внимание (сенсационные заголовки с кликбейтным языком или чрезмерное использование триггерных слов)
Случайная выборка этих классификаций от LLM была проверена тремя аспирантами с 76-процентным совпадением оценок.
Экспериментальные результаты
Определив два отдельных (но частично пересекающихся) «мусорных» набора данных, исследователи предварительно обучили четыре LLM с разными пропорциями «мусорных» и контрольных данных. Затем они протестировали эти модели на бенчмарках для измерения:
- способности к рассуждению (ARC AI2 Reasoning Challenge)
- долгосрочной памяти контекста (RULER)
- соблюдения этических норм (HH-RLHF и AdvBench)
- демонстрируемого «стиля личности» (TRAIT)
Результаты показали, что добавление большего количества «мусорных данных» в обучающие наборы оказало статистически значимое влияние на тесты рассуждения и долгосрочного контекста во всех моделях. Однако эффекты на других бенчмарках были более смешанными. Например, смесь 50/50 «мусорных» и контрольных данных, использованная для модели Llama 8B, дала лучшие результаты по некоторым показателям (этические нормы, высокая открытость, низкий невротизм и макиавеллизм), чем либо полностью «мусорные», либо полностью контрольные наборы данных.
Ирония ситуации в том, что мы создаем ИИ, который начинает повторять человеческие ошибки — не только в знаниях, но и в когнитивных искажениях. Особенно забавно, что смесь «мусора» и качественных данных иногда дает лучшие результаты, чем чистые наборы — возможно, ИИ тоже нуждается в «балансе питания», как и человеку. Впрочем, это не отменяет главного: если кормить модель только цифровым фастфудом, она действительно тупеет.
Последствия для индустрии
На основе этих результатов исследователи предупреждают, что «сильная зависимость от интернет-данных ведет предварительное обучение LLM в ловушку загрязнения контента». Они призывают к «пересмотру текущих практик сбора данных из интернета и непрерывного предварительного обучения» и предупреждают, что «тщательная курация и контроль качества будут необходимы для предотвращения кумулятивного вреда» в будущих моделях.
Это может стать особенно актуальным, поскольку все большая часть интернета заполняется контентом, сгенерированным ИИ, который может способствовать «коллапсу моделей», если будет использоваться для обучения будущих моделей. Но мы всегда можем просто уничтожить кучу печатных книг, чтобы получить качественные обучающие данные, верно?
По материалам Ars Technica





Оставить комментарий